




最近有个项目需要在Jetson Nano 上部署NanoSAM模型,在环境搭建上面遇到了不少问题,搞了好几天,终于搞完了,现在浅浅的记录一下。
这里需要注意,因为训练需要,我在Jetson上和本地Linux都进行了安装及部署,所以可能会在架构上搞错了,jetson一般是aarch64架构,而Linux是X86_64架构
创建并激活新环境(可选)
conda create -n myenv python=3.8
conda activate myenv
myenv 是你搭建的环境名字,可以更改,如果觉得下载太慢,可以配置清华大学镜像源
配置清华大学镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/conda config --dd channeconda config --set show_channel_urls yes
1. 安装环境配置

● 安装Pytorch、torchvision
安装Pytorch
安装依赖库
sudo apt-get -y update
sudo apt-get -y install autoconf bc build-essential g++-8 gcc-8 clang-8 lld-8 gettext-base gfortran-8 iputils-ping libbz2-dev libc++-dev libcgal-dev libffi-dev libfreetype6-dev libhdf5-dev libjpeg-dev liblzma-dev libncurses5-dev libncursesw5-dev libpng-dev libreadline-dev libssl-dev libsqlite3-dev libxml2-dev libxslt-dev locales moreutils openssl python-openssl rsync scons python3-pip libopenblas-dev
进入网址PyTorch for Jetson,根据Jetpack系统版本选择合适的whl文件,whl文件名称开头代表Pytorch版本,cp38代表Python版本是3.8
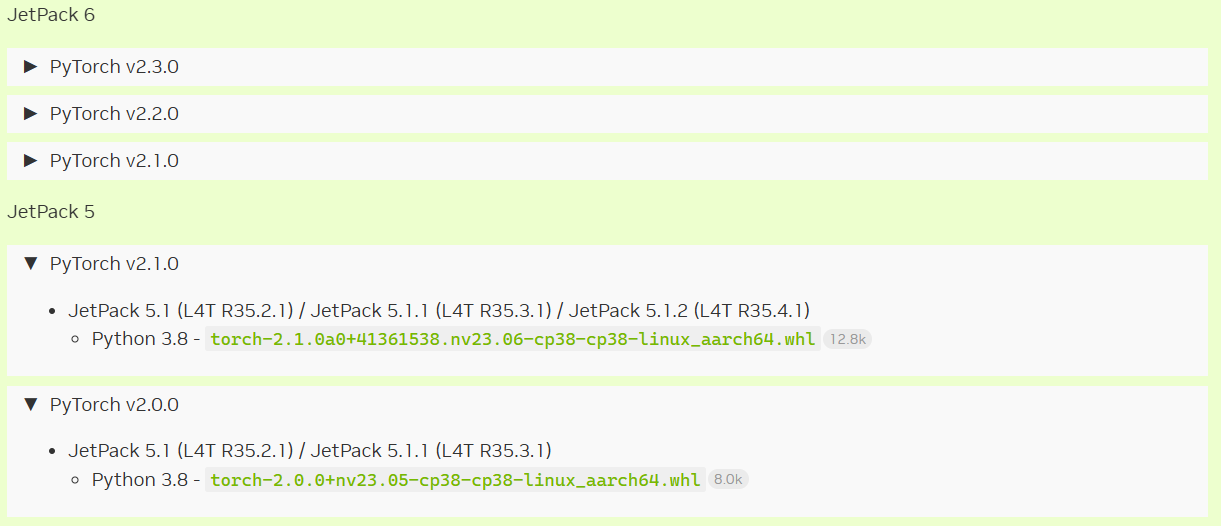
具体可参考Jeston Orin Nnao 安装pytorch与torchvision环境
安装torchvision 0.15.1
根据Pytorch版本选择适配的torchvision版本,我选择的Pytorch版本是2.0.0,对应的torchvision是0.15.1,进入GitHub - pytorch/vision at v0.15.1 ,在Tags选择合适的版本,下载zip文件
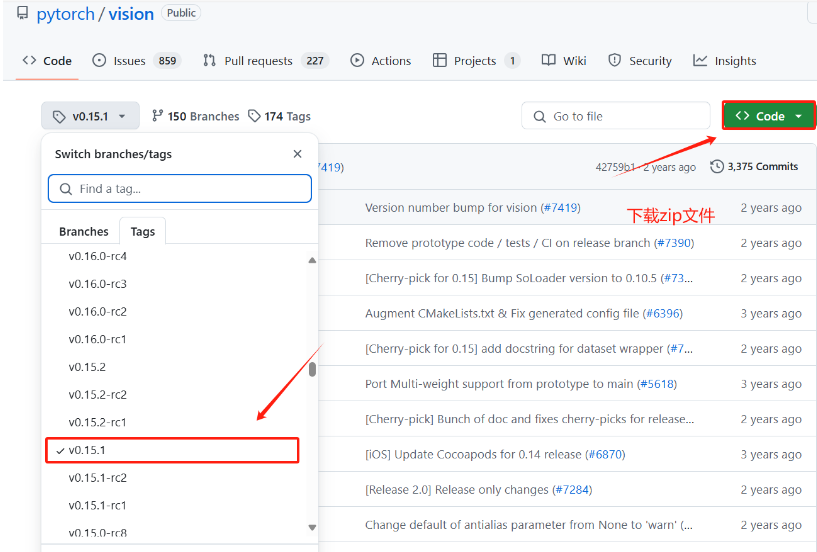
考虑到Github网络不稳定,我是先下到自己的电脑上,然后再将文件拷到Linux系统的
# 解压
unzip vision-v0.15.1.zip
# 进入解压文件
cd vision-0.15.1
# 安装
python3 setup.py install --user
● 安装Tensor RT
环境要求
这是TensorRT的GitHub仓库GitHub - NVIDIA/TensorRT

这里说明Tensor RT安装需要的环境要求,其中比较重要的就是cuda和cuDNN,这里推荐cuda11.8 + cuDNN 8.9.0
查看是否安装cuda 以及 cuDNN
查看cuda版本
# 查看cuda版本
nvcc --version
# 查看cuda安装路径
which nvcc
whereis nvcc
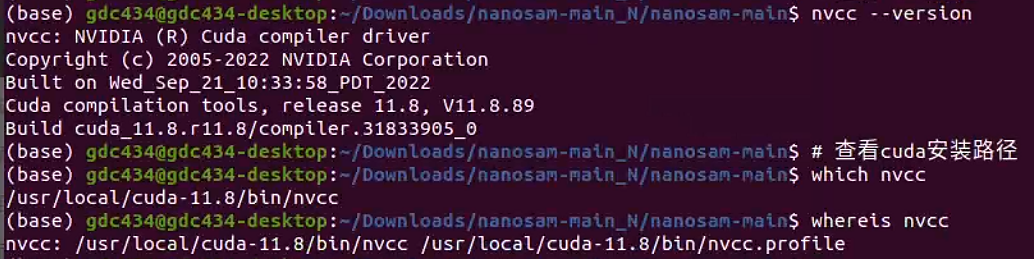
这里的cuda版本是11.8
查看cuDNN版本
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

如果执行上面的指令后没有显示,说明没有安装或环境未配置正确,这里以没安装为例
查看当前Ubuntu版本
lsb_release -a

安装cuda(可选)
安装依赖包
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6369
6369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









