




 作者作为一名机械工程学生,利用SolidWorks生成标准件动画并截取帧作为图像,创建了一个包含21828张图片的数据集。通过OpenCV读取和处理图像,解决中文路径问题,并进行了训练集和测试集的划分。尽管图像特征相似,但通过迁移学习在测试集上取得了77%的准确率,显示出数据集的有效性。文章还提及了在Ubuntu上配置matplotlib中文显示的挑战。
作者作为一名机械工程学生,利用SolidWorks生成标准件动画并截取帧作为图像,创建了一个包含21828张图片的数据集。通过OpenCV读取和处理图像,解决中文路径问题,并进行了训练集和测试集的划分。尽管图像特征相似,但通过迁移学习在测试集上取得了77%的准确率,显示出数据集的有效性。文章还提及了在Ubuntu上配置matplotlib中文显示的挑战。
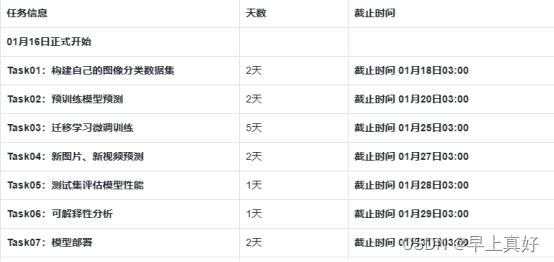
任务一要求:构建自己的图像分类数据集
对于datawhale的开源学习计划,我眼馋很久了,只是之前在学校,不敢轻易尝试。此次寒假终于能够克服畏难情绪进行尝试,终归是有所进步的。
第一个任务即是构建自己的图像分类数据集,看起来还是一个比较简单的任务,没想到还是让我头大许久。
数据来源
身为一名机械工程学院学生,我采用了一百个标准件构建数据集。
构建方法是,通过solidworks的运动算例生成标准件改变视图的动画,再将动画视频按帧读取。因为solidworks中的帧数可以自己调整,所以我制作的多是40~80帧、4~5秒的动画视频。
用opencv读取每一帧。这里出现了一个问题,cv.imwrite()不支持中文路径,因此我直接采用0~99的数字为名字创建文件夹,随后用os库与之前读取的零件名称列表对文件夹名进行了修改。
这样最初的图片文件夹就建立完成了。
疑虑
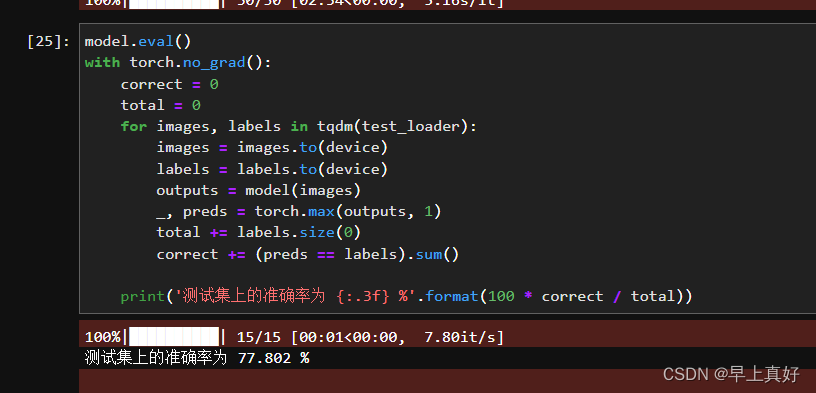
由于这些零件在图片中所处位置、颜色等方面都比较相似,与ImageNet数据集的相似度也比较低,我对这样一个数据集能否进行有效的分类心存疑虑。选择了25种零件进行了迁移学习微调训练,仅30个轮次,在测试集上的准确率就达到了77%,这二十五种零件都是螺栓、轴承的种类,相互之间本就没有很大的差别。这让我意识到,我这个刚刚接触深度学习的小白还是太孤陋寡闻了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 231
231




 到【灌水乐园】发言
到【灌水乐园】发言









