




 针对带有特定前缀的CSV文件,需要转换为新的CSV格式,包括小写化头衔、删除头衔前缀、合并共享部分名称的列,并保留原始行的特殊值。使用SPL语言可以实现动态转换,处理过程中需要处理未知数量和名称的列,同时确保具有特定标识(如'Inc')的列在合并时得以保留。
针对带有特定前缀的CSV文件,需要转换为新的CSV格式,包括小写化头衔、删除头衔前缀、合并共享部分名称的列,并保留原始行的特殊值。使用SPL语言可以实现动态转换,处理过程中需要处理未知数量和名称的列,同时确保具有特定标识(如'Inc')的列在合并时得以保留。
【问题】
I have a CSV file whose awful format I cannot change (simplified here):
Inc,a_One,a_Two,a_Three,b_One,b_Two,b_Three
1,1,1.5,"5 Things",2,2.5,"10 Things"
2,5,5.5,"10 Things",6,6.5,"20 Things"
Inc,a_One,a_Two,a_Three,b_One,b_Two,b_Three
3,9,9.5,"15 Things",10,10.5,"30 Things"
My desired output is a new CSV containing:
inc,label,one,two,three
1,"a",1,1.5,"5 Things"
2,"a",5,5.5,"10 Things"
3,"a",9,9.5,"15 Things"
1,"b",2,2.5,"10 Things"
2,"b",6,6.5,"20 Things"
3,"b",10,10.5,"30 Things"
Basically:
- lowercase the headers
- strip off header prefixes and preserve them by adding them to a new column
- remove header repetitions in later rows
- stack each column that shares the latter part of their names (e.g.
a_Oneandb_Onevalues should be merged into the same column). - During this process, preserve the
Incvalue from the original row (there may be more than one row like this in various places).
With caveats:
-
I don't know the column names ahead of time (many files, many different columns). These need to be parsed if they are to be used as logic for stripping the repetitious header rows.
-
There may or may not be more than one column with properties like Inc that need to be preserved when everything gets stacked. Generally, Inc represents any column that does not have a prefix like a_ or b_. I have a regex to strip out these prefixes already.
So far, I've accomplished this:
> wip_path <- 'C:/path/to/horrible.csv'
> rawwip <- read.csv(wip_path, header = FALSE, fill = FALSE)
> rawwip
V1 V2 V3 V4 V5 V6 V7
1 Inc a_One a_Two a_Three b_One b_Two b_Three
2 1 1 1.5 5 Things 2 2.5 10 Things
3 2 5 5.5 10 Things 6 6.5 20 Things
4 Inc a_One a_Two a_Three b_One b_Two b_Three
5 3 9 9.5 15 Things 10 10.5 30 Things
> skips <- which(rawwip$V1==rawwip[1,1])
> skips
[1] 1 4
> filwip <- rawwip[-skips,]
> filwip
V1 V2 V3 V4 V5 V6 V7
2 1 1 1.5 5 Things 2 2.5 10 Things
3 2 5 5.5 10 Things 6 6.5 20 Things
5 3 9 9.5 15 Things 10 10.5 30 Things
> rawwip[1,]
V1 V2 V3 V4 V5 V6 V7
1 Inc a_One a_Two a_Three b_One b_Two b_Three
But then when I try to apply a tolower() to these strings, I get:
> tolower(rawwip[1,])
[1] "4" "4" "4" "4" "4" "4" "4"
And this is quite unexpected.
So my questions are:
1)How can I gain access to the header strings in `rawwip[1,]` so that I can reformat them with `tolower()` and other string-manipulating functions?
2) Once I’ve done that, what’s the most effective way to stack the columns with shared names while preserving the inc value for each row?
Bear in mind, there will be well over a thousand repetitious columns that can be filtered down to perhaps 20 shared column names. I will not know the position of each stackable column ahead of time. This needs to be determined within the script.
【回答】
如果是静态变换,这个问题用R比较容易实现,但如果是动态变换就困难了,比如要求:字段名可以是任何字符串(不限于a,b,one,two,three),任意数量(不限于2*3)。用SPL容易实现动态变换,代码如下:
| A | B | ||
| 1 | =file("d:\\source.csv").import@tc() | ||
| 2 | =A1.select(Inc!="Inc") | ||
| 3 | =A1.fname().to(2,).(~.split("_")) | ||
| 4 | =A3.id(~(1)) | =A3.id(~(2)) | |
| 5 | =create(inc,label,${B4.(lower(~)).concat@c()}) | ||
| 6 | =A2.run(A4.run(A5.record(A2.Inc|A4.~|B4.(A2.~.field(A4.~+"_"+~))))) | ||
| 7 | =file("d:\\result.csv").export@tc(A5) | ||
A1:读取 csv文件的内容并返回成序表;

A2:选出文件中非标题行的数据;

A3:对字段名中含有"_"的字段名进行拆分,结果拆分成含有序列的序列;
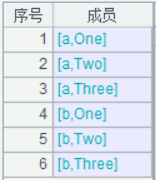
A4:去掉重复数据;
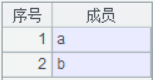
B4:去掉重复数据;
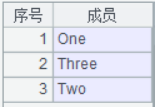
A5:创建序表A5 ,用于保存最终的查询结果。此处通过宏替换依次将B4中字符串变为小写;
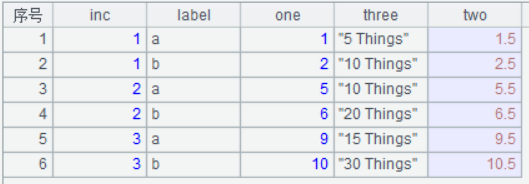
A6:将A2中的记录,经过处理,将一行转换为多行记录,并将结果保存到A5中,得到转换后的结果如上图;
A7:将A5中的结果导出到新的csv文件;



















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









