




 本文介绍了如何使用LSTM与CRF进行实体识别,解释了CRF的损失函数及其动态规划求解过程,并阐述了如何利用模型预测输入的标签序列。虽然未提供完整代码,但详细说明了预测思路和路径选择策略。
本文介绍了如何使用LSTM与CRF进行实体识别,解释了CRF的损失函数及其动态规划求解过程,并阐述了如何利用模型预测输入的标签序列。虽然未提供完整代码,但详细说明了预测思路和路径选择策略。
Recap
参考https://www.jianshu.com/p/aed50c1b2930开始这个任务。
crf参考网址:https://www.cnblogs.com/createMoMo/p/7529885.html
知道了lstm的输出格式(即crf中会使用到的emission score,每个位置的单词对应各label的概率),虽然只利用lstm也可以进行预测(每个单词的label取使概率取最大值的即可),但这样的预测在很多时候明显是错的(如i标签出现,在前面未有b的情况下),而条件随机场很好地解决了这个问题(通过在预测时不光考虑emission,也考虑transition)。
crf的lost function表达。难点在于表达log(e^s1+…e sn)和利用训练好的模型预测未见过的句子的label这两个dp算法。
吃完饭回来继续dp+code,之后开始gcn的学习(关系提取)。
lost function
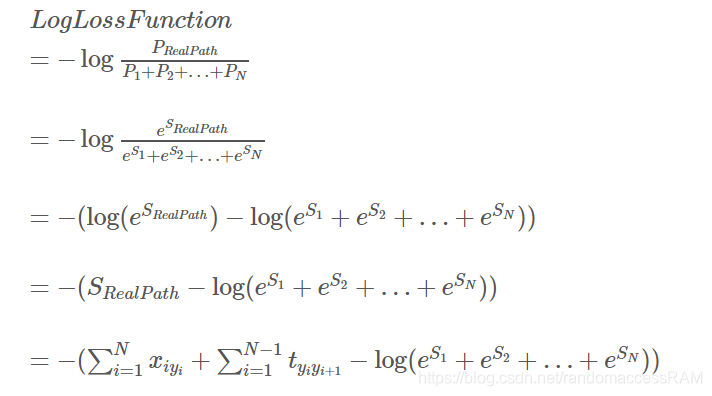
如果可以表达出来lost function,就可以进行优化,从而update模型参数。
所有路径的log(e^si)之和
假设这样一个toy example:三个words(w0,w1,w2),都是可以从l1和l2两个label里面取。
假设有两个命名为obs(i.e,observe),previous的数据结构。obs的第一列代表到此时分析到的最后一个word,label取为l1,第二列类似。
可以跟着下面这样的方法演算一遍:
wo时:
previous = [x01,x02]
obs为空
w0->w1时:
previous为[x11,x12]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3976
3976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









