







可以本地搭建自己的本地大模型,可以成为自己本地的一个ai助手,下面是简单案例。
一、下载Ollama
下载这个貌似是直接下载在c盘,但是下载大模型注意,可以换盘!!!
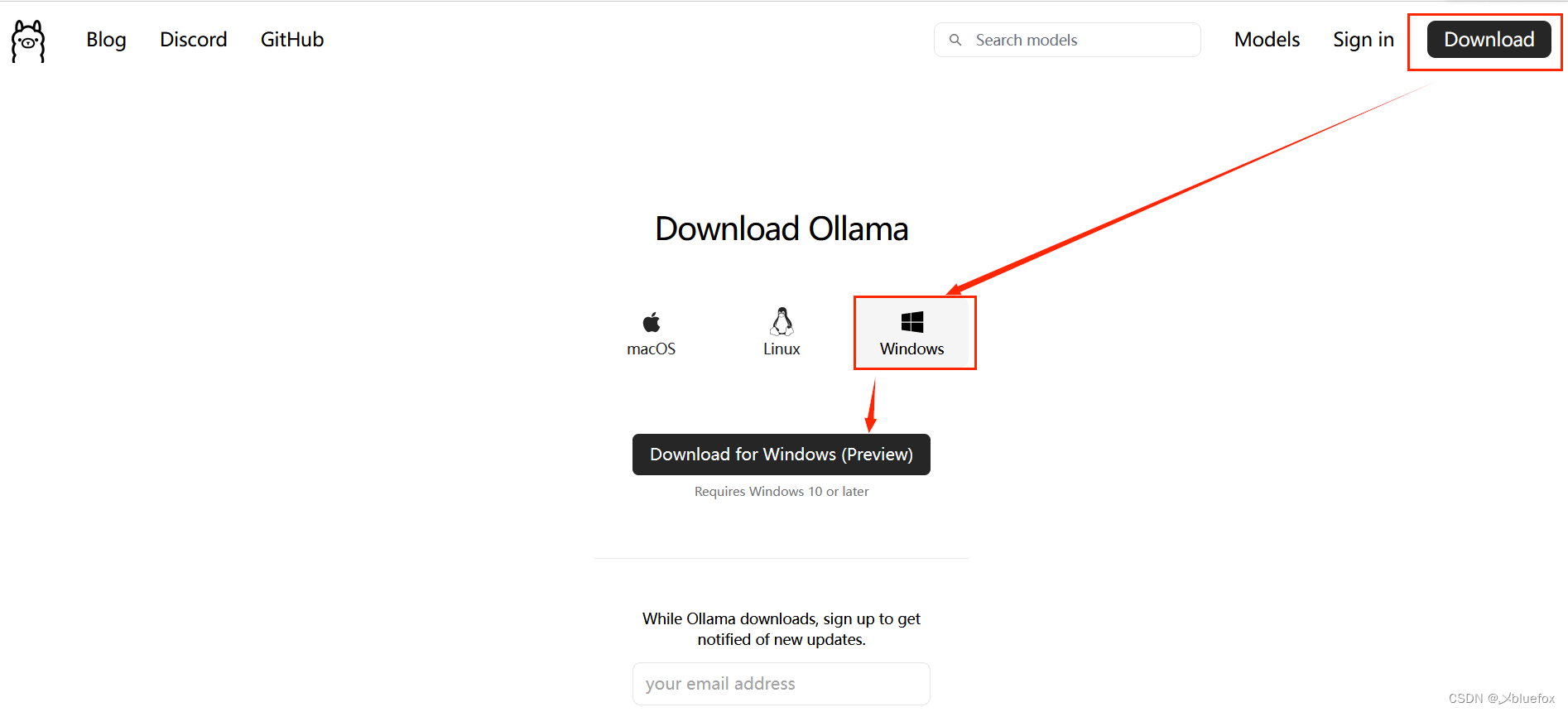
下载完成直接双击那个下载包,按着下载。
二、配置环境变量
注意,记得配置环境变量!!!
注意,记得重启电脑!!!
别问为啥,问就是当你下载几十g的大模型在c盘,细品,可以通过修改环境变量,当你也以为万事大吉了,点击下载,几十g的大模型还在c盘,细品!!!所以记得重启电脑。
在高级系统变量里面配置:
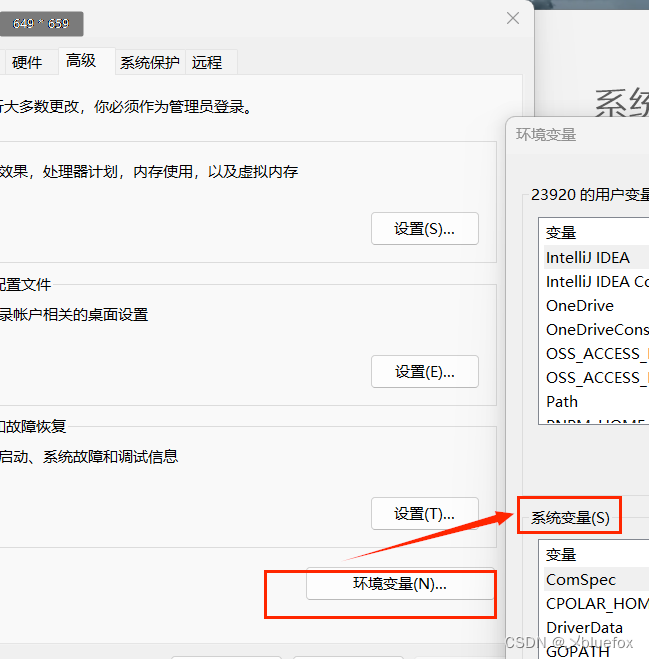
新建一个环境变量:
变量名:OLLAMA_MODELS
变量值:D:\developApp\Ollama //这里写你打算放大模型的位置
配置好环境变量,重启电脑!!!
三、拉取大模型
这里我举个拉取阿里的qwen这个大模型的例子:library

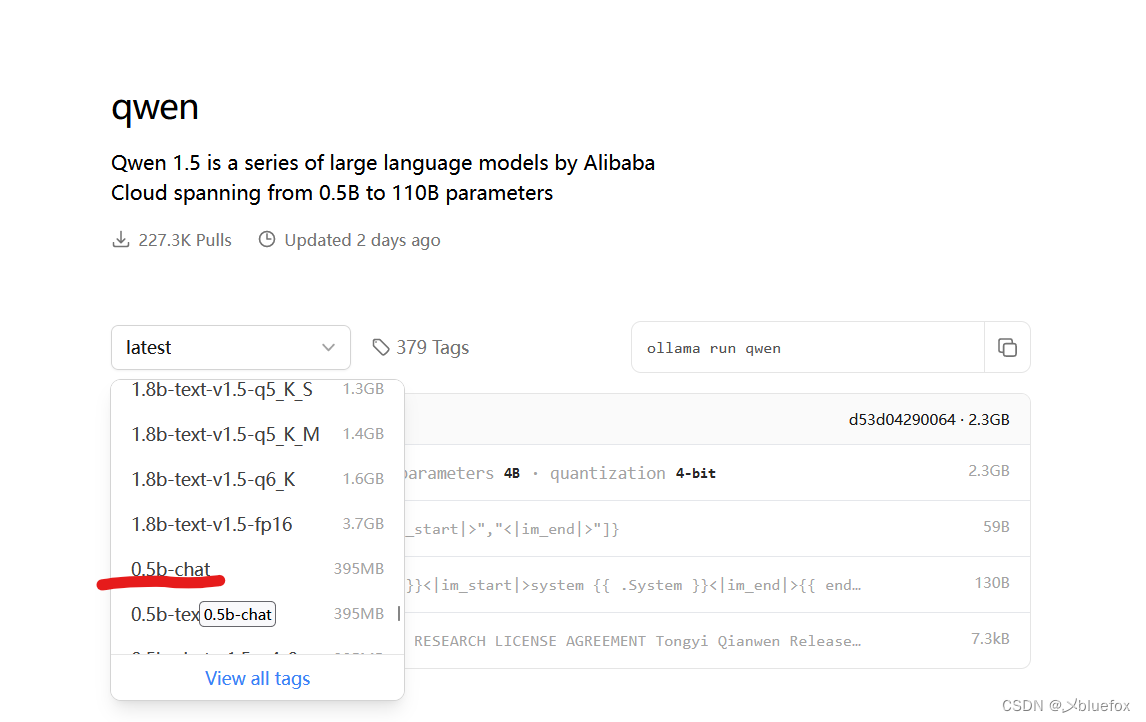
这里我选择最小的下载,chat是指只支持聊天,当然越大功能越强大。
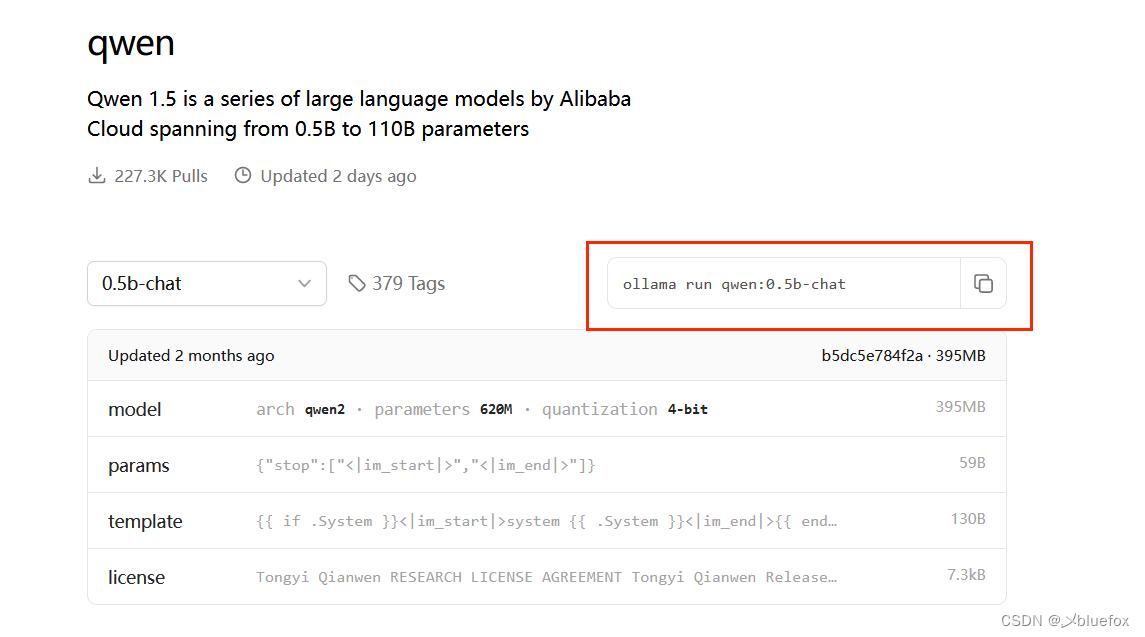
复制上面的指令去你之前配置环境变量那个位置,打开cmd。
ollama run qwen:0.5b-chat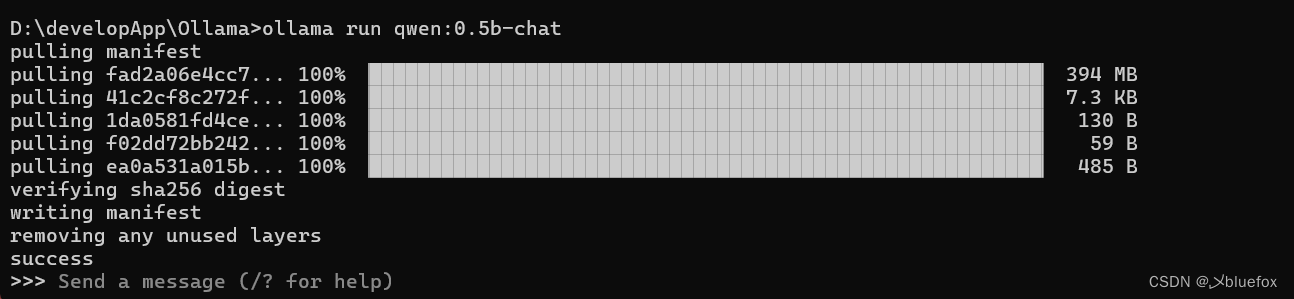
下载完成,下面你可以看到你配置环境变量的那个包里面有两个文件夹。
拉取的模型可以在存储目录blobs下看到

四、默认 Ollama api 监听的端口
默认 Ollama api 会监听 11434 端口。
netstat -ano | findstr 11434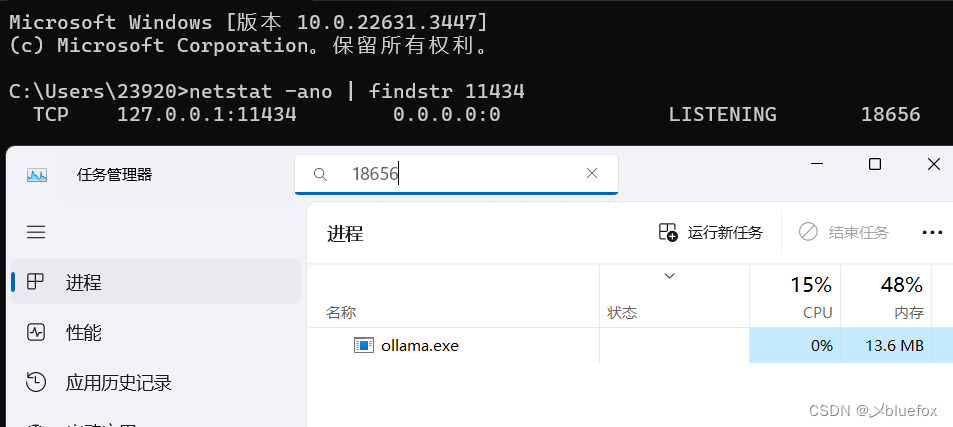
四、代码
(1)配置maven
和其他chat项目一样,springboot3+,jdk17+,springai坐标,还要配置外部仓库
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>0.8.1</version>
</dependency><!--配置本项目的仓库:因为maven中心仓库还没有更新spring ai的jar包-->
<repositories>
<!-- <!–快照版本的仓库–>-->
<!-- <repository>-->
<!-- <id>spring-snapshot</id>-->
<!-- <name>Spring Snapshots</name>-->
<!-- <url>https://repo.spring.io/snapshot</url>-->
<!-- <releases>-->
<!-- <enabled>false</enabled>-->
<!-- </releases>-->
<!-- </repository>-->
<!--里程碑版本的仓库-->
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>(2)yml配置
spring:
application:
name: #写你的项目名
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: qwen:0.5b-chat(3)写接口
@RestController
public class OllamaController {
@Resource
private OllamaChatClient ollamaChatClient;
public Object ollama(@RequestParam(value = "msg",defaultValue = "给我讲一个笑话") String msg) {
String called = ollamaChatClient.call(msg);
System.out.println(called);
return called;
}
@RequestMapping(value = "/ai/ollama2")
public Object ollama2(@RequestParam(value = "msg",defaultValue = "给我讲一个笑话") String msg) {
ChatResponse chatResponse = ollamaChatClient.call(new Prompt(msg, OllamaOptions.create()
.withModel("qwen:0.5b-chat") //使用哪个大模型
.withTemperature(0.4F))); //温度,温度值越高,准确率下降,温度值越低,准确率会提高
System.out.println(chatResponse.getResult().getOutput().getContent());
return chatResponse.getResult().getOutput().getContent();
}
}
测试:http://localhost:8080/ai/ollama
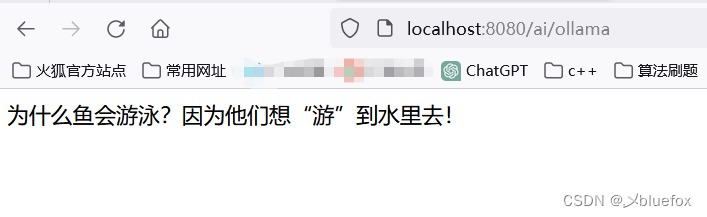
成功!!


















 1561
1561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











