



简介
UNTER++ 是一种基于深度学习的自然语言处理(NLP)模型,专注于文本生成、摘要和对话系统任务。其核心架构结合了Transformer的变体,通过多任务学习优化生成质量与效率。
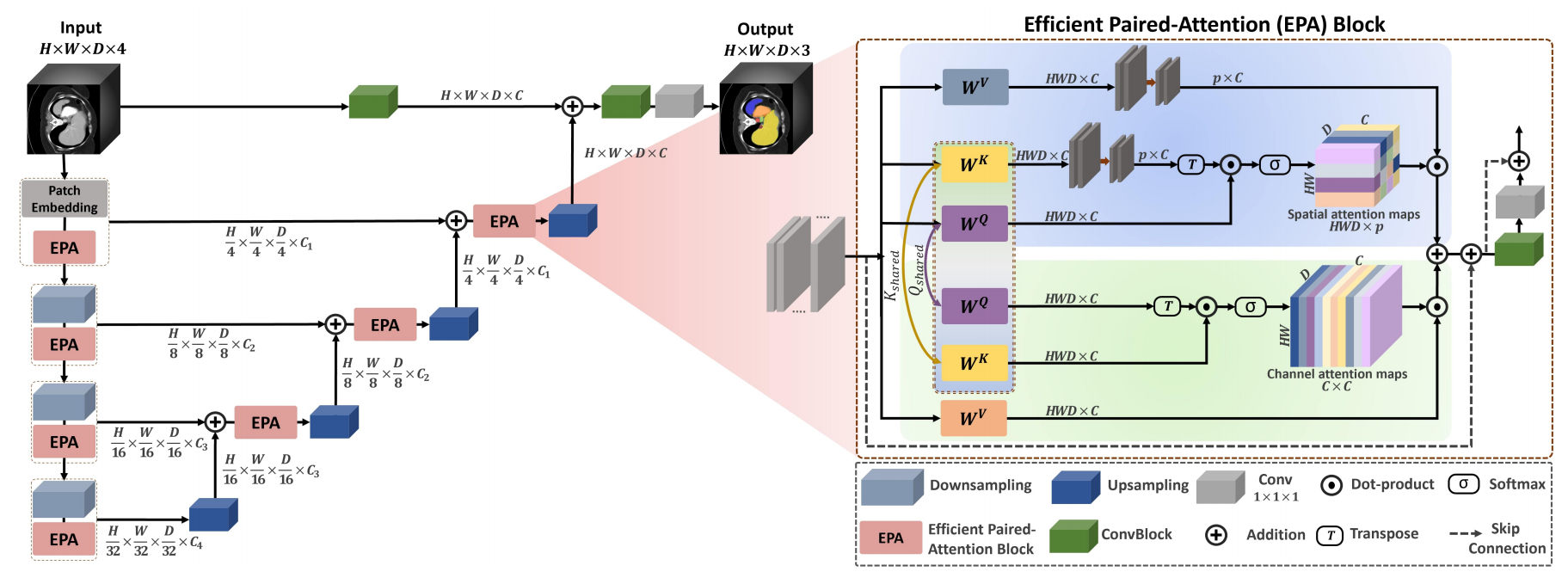
其网络结构如下图所示:
改进点
与UNETR网络相比最核心的改进点是用 EPA 替代原始 Self-Attention。
| 对比项 | UNETR | UNETR++ |
|---|---|---|
| 注意力机制 | 标准 ViT 中的 vanilla self-attention | EPA 模块:联合建模空间 + 通道注意力,线性复杂度 |
| 是否共享 Q/K | 否(Q, K, V 独立) | 是(空间和通道分支共享 Q 和 K 投影权重) |
| 建模维度 | 仅空间依赖 | 空间 + 通道联合依赖 |
| 参数量 | 高(每层 3 个投影矩阵) | 低(共享 Q/K,仅 2 个 V 投影 + 卷积) |
原始 UNETR 使用标准的 Vision Transformer(ViT)编码器,其中每个 Transformer 块包含自注意力(Self-Attention)和 MLP。这种设计在医学图像分割中计算开销大,且对局部-全局依赖建模不够高效。
EPA 的设计在保持甚至提升分割性能的同时,显著降低参数量和 FLOPs:
(1)将自注意力分解为 通道注意力 和 空间注意力 两个并行分支(即“paired”)。
(2)每个分支只关注一个维度(通道或空间),大幅减少计算量。
(3)通过轻量级交互机制融合两个分支的信息。
关于UNETR网络的讲解请看博主的这篇文章:
网络结构层次化(Hierarchical Design)
| 对比项 | UNETR | UNETR++ |
|---|---|---|
| 特征分辨率 | 固定 patch 序列(如 16×16×8 → 所有层 token 数相同) | 多尺度金字塔结构(类似 Swin): Stage 1: H/4×W/4×D/2 → Stage 2: H/8×... → Stage 4: H/32×... |
| 下采样方式 | 无显式下采样(靠 patch embedding 一次性降维) | 使用 stride=2 的 3D 卷积进行逐级下采样 |
| 跳跃连接对齐 | 特征图尺寸固定,跳跃连接简单拼接 | 需要对不同尺度特征进行上采样/融合,更符合 U-Net 原始思想 |


















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









