



简介
nnFormer(nnU-Net-based Transformer)是一种将 Transformer 架构与 nnU-Net 框架相结合的医学图像分割模型。它在继承 nnU-Net 自动化、鲁棒性强等优点的基础上,引入了 Transformer 的全局建模能力,以克服传统 CNN(如 U-Net)在长距离依赖建模方面的局限性。
nnFormer 将 Swin Transformer 作为 nnU-Net 框架中的一个“可插拔编码器模块”,其余所有自动化流程(数据预处理、训练策略、推理后处理等)完全复用 nnU-Net 的成熟 pipeline(流程)。
流程
下面是nnformer的整体框架图:
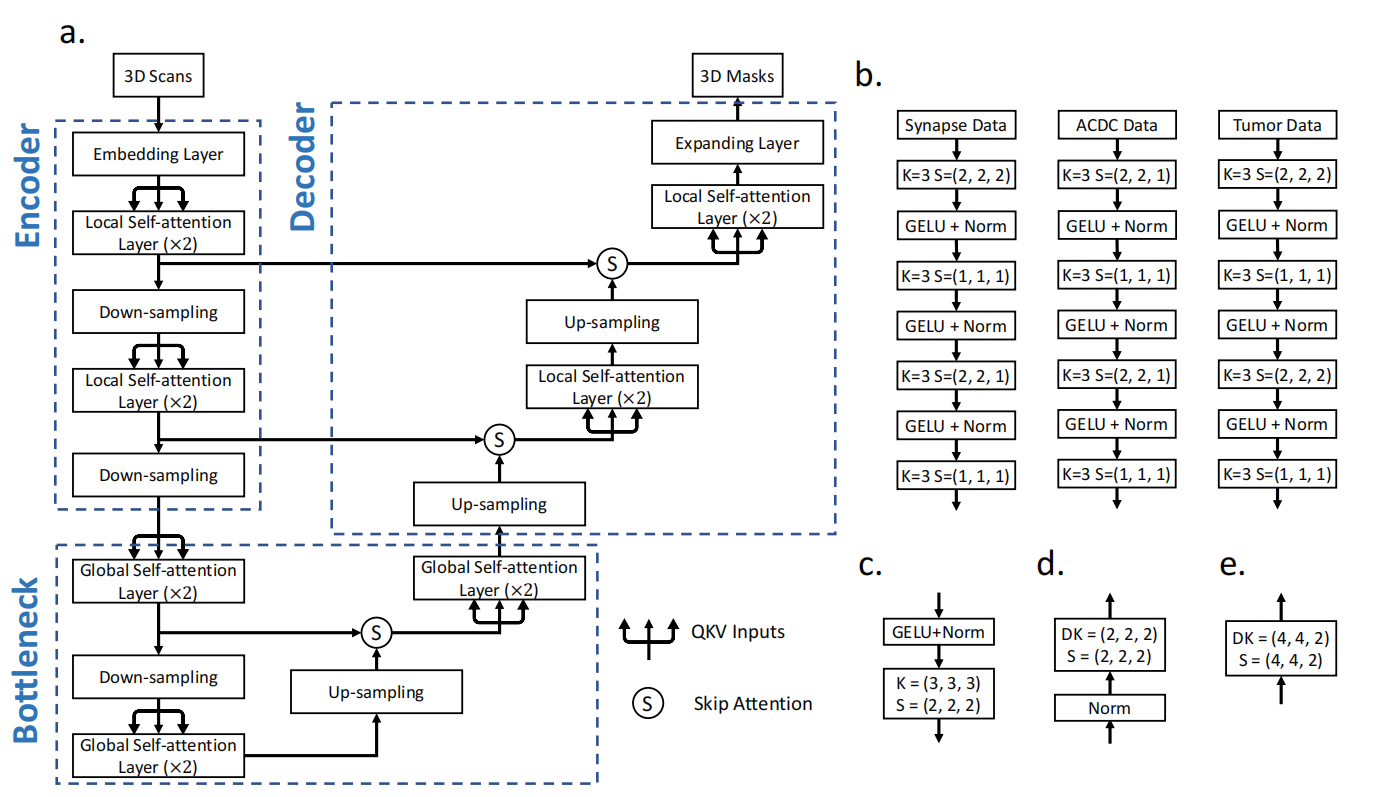
主要可以划分为如下几个模块:
(1)3D Scans(Embedding Layer)模块
(2)Encoder(含 Patch Merging 与 Swin Blocks)
(3)Decoder(含上采样与跳连融合)
(4)输出头(Prediction Head)
模块 1:3D Scans模块(初始特征提取)
将原始图像(如 CT/MRI)通过一个卷积层提取低级特征;然后 reshape 成序列形式(tokens),供 Transformer 处理。
| 步骤 | 操作 | 输入尺寸 (B×C×D×H×W) | 输出尺寸 (B×C×D×H×W) | 说明 |
|---|---|---|---|---|
| 1 | 原始输入 | 1×1×128×128×128 | — | 单通道 3D 医学图像(如 CT) |
| 2 | Stem Conv3d | 1×1×128×128×128 | 1×48×64×64×64 | Conv3d(kernel=3, stride=2, padding=1, out_channels=48) |
| 3 | LayerNorm + GELU | 1×48×64×64×64 | 1×48×64×64×64 | 归一化与非线性激活 |
模块 2:Encoder(Swin Transformer 编码器)
包含 4 个 stage,每个 stage = Patch Merging(除 Stage1) + 若干 Swin Blocks。
Stage 1(无下采样):Local Self-attention Layer (×2)
使用局部自注意力(Local Self-attention),即在小窗口内计算注意力;两个 block 组成一个 stage,通常包含 W-MSA 和 S-MSA(偏移窗口)。
| 步骤 | 操作 | 输入尺寸 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| 2.1 | Reshape to tokens | 1×48×64×64×64 | 1×(64⋅64⋅64)×48 | 转为序列:N=262144N=262144 tokens |
| 2.2 | Swin Block (W-MSA) | 1×262144×48 | 1×262144×48 | 窗口大小 = 7×7×7,局部自注意力 |
| 2.3 | Swin Block (S-MSA) | 1×262144×48 | 1×262144×48 | 窗口偏移 (3,3,3),实现跨窗口交互 |
| 2.4 | Reshape back to volume | 1×262144×48 | 1×48×64×64×64 | 恢复为体素格式 |
Stage 2(第一次下采样)
| 步骤 | 操作 | 输入尺寸 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| 2.5 | Patch Merging | 1×48×64×64×64 | 1×96×32×32×32 | 合并 2×2×2 体素 → 通道 48×8=384 → Linear→96 |
| 2.6 | Swin Block ×2 | 1×96×32×32×32 | 1×96×32×32×32 | W-MSA + S-MSA |
Stage 3(第二次下采样)
| 步骤 | 操作 | 输入尺寸 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| 2.7 | Patch Merging | 1×96×32×32×32 | 1×192×16×16×16 | 96×8=768 → Linear→192 |
| 2.8 | Swin Block ×2 | 1×192×16×16×16 | 1×192×16×16×16 | — |
保存为跳连特征 F₃:1×192×16×16×161×192×16×16×16
Stage 4(第三次下采样,Bottleneck)
| 步骤 | 操作 | 输入尺寸 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| 2.9 | Patch Merging | 1×192×16×16×16 | 1×384×8×8×8 | 192×8=1536 → Linear→384 |
| 2.10 | Swin Block ×2 | 1×384×8×8×8 | 1×384×8×8×8 | 最深层语义特征 |
编码器最终输出 F₄:1×384×8×8×81×384×8×8×8
模块 3:Decoder(上采样 + 跳连融合)
| 步骤 | 操作 | 输入尺寸 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| 1 | Upsample F₄ | 1×384×8×8×8 | 1×384×16×16×16 | Trilinear interpolation (scale_factor=2) |
| 2 | Concat with F₃ | 1×(384+192)×16×16×16 | 1×576×16×16×16 | 跳连来自 Encoder Stage 3 |
| 3 | Fusion Conv3d | 1×576×16×16×16 | 1×192×16×16×16 | Conv3d(576→192, k=3, p=1) + LN + GELU → D₃ |
| 4 | Upsample D₃ | 1×192×16×16×16 | 1×192×32×32×32 | ×2 上采样 |
| 5 | Concat with F₂ | 1×(192+96)×32×32×32 | 1×288×32×32×32 | 跳连来自 Stage 2 |
| 6 | Fusion Conv3d | 1×288×32×32×32 | 1×96×32×32×32 | Conv3d(288→96) → D₂ |
| 7 | Upsample D₂ | 1×96×32×32×32 | 1×96×64×64×64 | ×2 上采样 |
| 8 | Concat with F₁ | 1×(96+48)×64×64×64 | 1×144×64×64×64 | 跳连来自 Stage 1 |
| 9 | Fusion Conv3d | 1×144×64×64×64 | 1×48×64×64×64 | Conv3d(144→48) → D₁ |
模块 4:输出头(Prediction Head)
| 步骤 | 操作 | 输入尺寸 | 输出尺寸 | 说明 |
|---|---|---|---|---|
| 1 | Final Upsample | 1×48×64×64×64 | 1×48×128×128×128 | Trilinear interpolation (scale_factor=2) |
| 2 | 1×1×1 Conv (logits) | 1×48×128×128×128 | 1×K×128×128×128 | K = 类别数(如 3) |
| 3 | Softmax (多类) / Sigmoid (二类) | 1×K×128×128×128 | 1×K×128×128×128 | 输出每个体素的类别概率 |
补充
nnFormer 如何“嵌入”到 nnU-Net 框架中?
保留 nnU-Net 的整体训练 pipeline(流程):
(1)使用完全相同的预处理流程(如重采样到 median spacing)
(2)使用相同的 patch size 选择逻辑(基于数据集统计)
(3)使用相同的损失函数:Dice Loss + Cross-Entropy
(4)使用相同的增强策略:旋转、缩放、弹性形变、gamma 变换等
仅替换 encoder 部分为 Swin Transformer:
(1)原 nnU-Net 使用 ResNet-style U-Net(堆叠 Conv + InstanceNorm + LeakyReLU)
(2)nnFormer 将 encoder 替换为 Swin Transformer stages
(3)decoder 仍保留 nnU-Net 风格:上采样 + 跳连 + 卷积(非纯 Transformer decoder)
优势:
(1)利用 Swin 的全局建模能力提升分割精度;
(2)保留 nnU-Net decoder 的局部细节恢复能力;
(3)无需重新设计训练策略,直接复用 nnU-Net 的鲁棒pipeline。

















 2588
2588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









