 UNETR模型详解
UNETR模型详解




论文的arXiv 链接:https://arxiv.org/abs/2103.10504
简介
UNETR(UNEt TRansformer)是一种基于Transformer架构的医学图像分割模型,结合了U-Net的编码器-解码器结构和Transformer的全局建模能力。它通过替换U-Net的卷积编码器为纯Transformer模块,直接从3D图像块序列中提取多尺度特征,同时保留U-Net的解码器进行渐进式上采样和定位。网络整体架构如下:
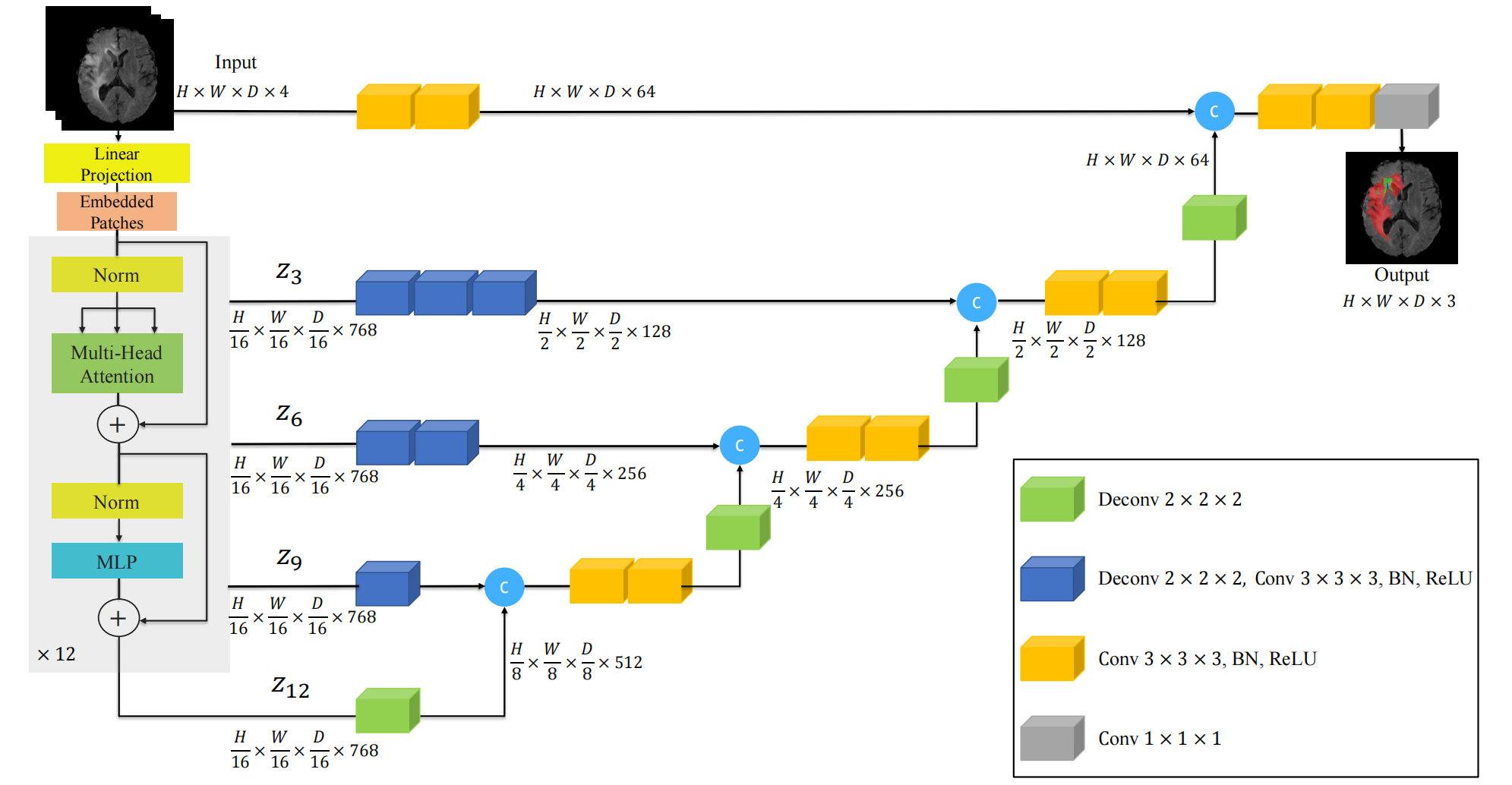
| 🟢 绿色立方体 | Deconv 2×2×2:3D 转置卷积,上采样 ×2 |
| 🔵 蓝色立方体 | Deconv 2×2×2 + Conv 3×3×3 + BN + ReLU:完整上采样+融合单元 |
| 🟡 黄色立方体 | Conv 3×3×3 + BN + ReLU:普通卷积层 |
| 🔵+🟢 组合 | 表示一个“上采样 + 卷积融合”模块 |
| 🔵(带 c) | 拼接(Concatenation)操作 |
| 🟤 灰色立方体 | Conv 1×1×1:最终分类头 |
UNETR 保留了 U-Net 的经典 对称 U 型结构:
(1)编码器(下采样路径):逐级提取高层语义特征;
(2)解码器(上采样路径):解码器仍是 CNN,非 Transformer,逐步恢复空间分辨率;
(3)跳跃连接:将编码器各阶段的多尺度特征传递给对应层级的解码器,用于融合局部细节与全局语义。
流程
下面我以一个例子简单讲解一下整个的计算流程以及尺寸变化。我们假设:
输入图像尺寸:96 × 96 × 96(H × W × D,体素空间)
输入通道数:1(如单模态 CT)
目标分割类别数:14(如 MSD 数据集中的多器官分割)
Patch Embedding(分块嵌入)
将输入划分为 non-overlapping 3D patches。每个 patch 大小:16×16×16;每个 patch 体素数:16 × 16 × 16 = 4096;总 patch 数:(96//16) × (96//16) × (96//16) = 6 × 6 × 6 = 216。
每个 patch 展平为 16×16×16 = 4096 维向量,通过线性投影(embedding)映射到隐空间维度 C = 768(标准 ViT 设置)。
输出张量:
Token 序列 [B, N=216, C=768],加上位置编码(可学习)后输入 Transformer。(B是批次大小batch_size)
Transformer 编码器(多层 ViT)
12 层标准 Transformer blocks。
关键输出层:取第 3、6、9、12 层的输出用于跳跃连接(对应 4 个尺度)
| 层级 | 输出 token 尺寸 | 对应“虚拟”空间分辨率 |
|---|---|---|
| ViT-3 | [B, 216, 768] | 6×6×6 |
| ViT-6 | [B, 216, 768] | 6×6×6 |
| ViT-9 | [B, 216, 768] | 6×6×6 |
| ViT-12 | [B, 216, 768] | 6×6×6 |
多尺度特征重建(从 token 到 3D 特征图)重点!
这一步是UNETR 的关键技巧,将固定数量的 token 重建为不同分辨率的 3D 特征图,以便与解码器的上采样路径对接。
使用 3D 卷积转置(ConvTranspose3d)或插值 + 卷积 逐步上采样。采用分阶段上采样模块,从 ViT-12 开始,逐级融合并上采样:
| 阶段 | 来源 | 重建后特征图尺寸 | 通道数 |
|---|---|---|---|
| S4(最深层) | ViT-12 | 6 × 6 × 6 (96/16) | 768 → 32 |
| S3 | ViT-9 + 上采样(S4) | 12 × 12 × 12(96/8) | 32 |
| S2 | ViT-6 + 上采样(S3) | 24 × 24 × 24(96/4) | 32 |
| S1(最浅层) | ViT-3 + 上采样(S2) | 48 × 48 × 48(96/2) | 32 |
CNN 解码器(上采样 + 跳跃连接融合)
| 阶段 | 来源(ViT 层) | 解码器输入 | 操作步骤(按顺序) | 输出尺寸(B=1) |
|---|---|---|---|---|
| D4 (最深层) | ViT-12(Z₁₂) | [1, 32, 6, 6, 6] | 1. 上采样 ×2(Deconv 2×2×2) 2. 拼接 S3(来自 ViT-9 上采样至 12³) 3. 3×3×3 Conv + BN + ReLU(融合) | [1, 32, 12, 12, 12] |
| D3 | ViT-9(Z₉)→ S3 | [1, 32, 12, 12, 12] | 1. 上采样 ×2 2. 拼接 S2(ViT-6 上采样至 24³) 3. 3×3×3 Conv 融合 | [1, 32, 24, 24, 24] |
| D2 | ViT-6(Z₆)→ S2 | [1, 32, 24, 24, 24] | 1. 上采样 ×2 2. 拼接 S1(ViT-3 上采样至 48³) 3. 3×3×3 Conv 融合 | [1, 32, 48, 48, 48] |
| D1 (输出层) | ViT-3(Z₃)→ S1 | [1, 32, 48, 48, 48] | 1. 上采样 ×2 → 96³2. 1×1×1 Conv(分类头) | [1, C=类别数, 96, 96, 96] |
S1、S2、S3、S4是 ViT 中间层输出经过上采样和通道调整后的特征图,用于跳跃连接:
S1 ← ViT-3 → 上采样 ×8 → [48,48,48]
S2 ← ViT-6 → 上采样 ×4 → [24,24,24]
S3 ← ViT-9 → 上采样 ×2 → [12,12,12]
S4 ← ViT-12 → 无上采样 → [6,6,6](作为 D4 的初始输入)

















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









