



注:作者为初学者,有些知识可能描述不准确,望见谅。同时由于目前作者学习知识有限,这次实战的最后效果可能没有那么好。
先放效果图:
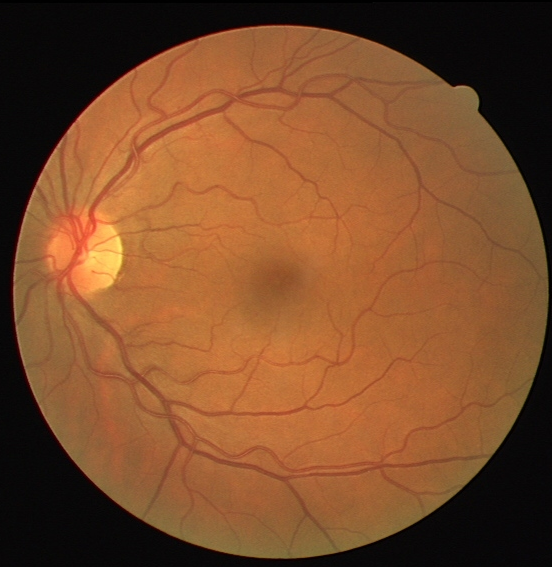
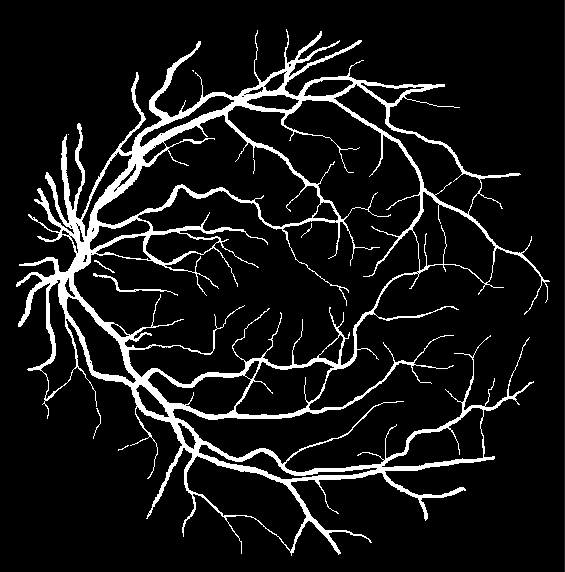
真实标签:
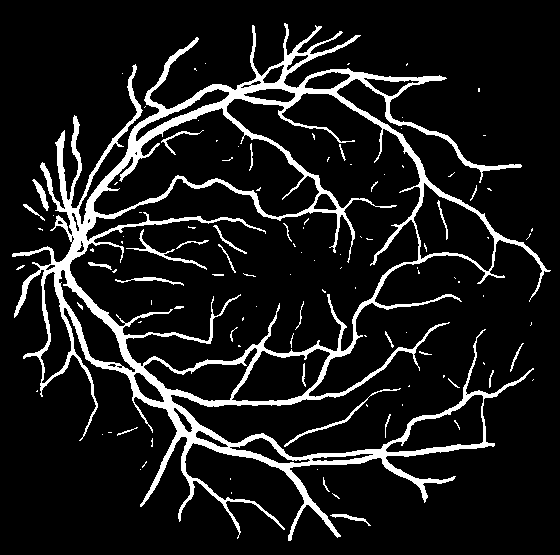
训练后模型推理出的结果,可以看出细小血管的分割不太到位:
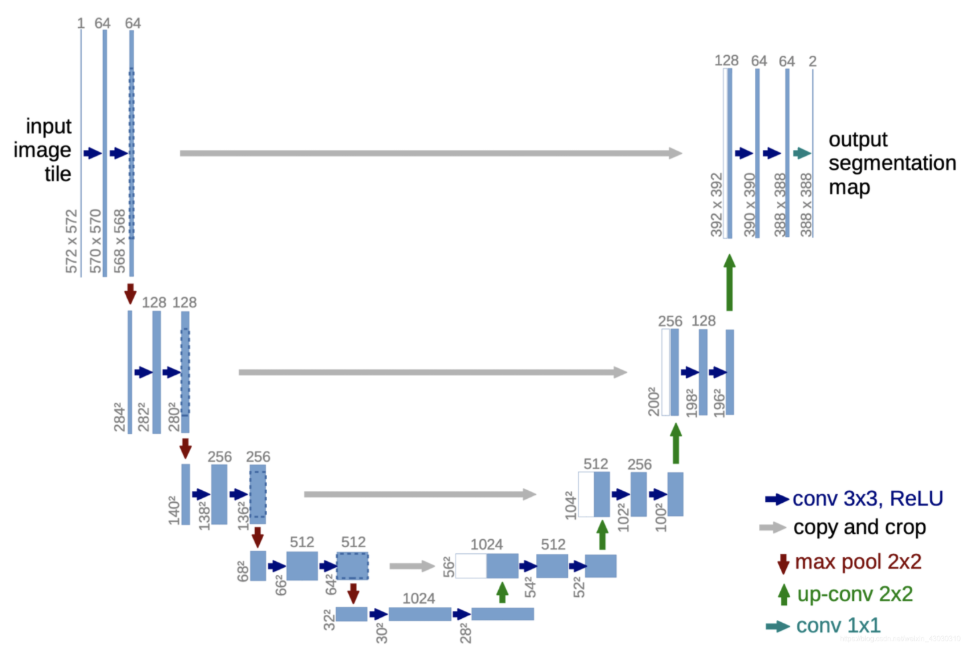
Unet网络简介
关于Unet网络的讲解请看博主的这篇文章:
DRIVE数据集介绍
DRIVE数据集的全称为Digital Retinal Images for Vessel Extraction(用于血管提取的数字视网膜图像)。
该数据集是视网膜图像分析领域的基准数据集,主要用于视网膜血管分割算法的开发和评估。包含40张彩色眼底照片(其中20张用于训练,20张用于测试),每张图像均配有专家手动标注的血管分割结果和视盘掩模。
关键特点
- 图像分辨率:584×565像素
- 数据来源:荷兰糖尿病视网膜病变筛查项目
- 标注类型:二值血管分割图、视盘位置标注
- 应用方向:医学图像分割、糖尿病视网膜病变研究
代码实现
DRIVE数据集下载
可以从Kaggle、飞桨等网站下载,下载后放在代码文件夹中:
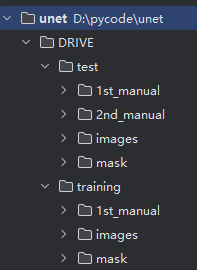
其中1st_manual为第一位眼科医生在原始眼底图像上勾勒的血管像素,被视为“金标准”,2nd_manual为第二位医生独立完成、同样勾勒血管像素的标注,但它存在的意义并不是拿来当训练/测试标签,而是用来衡量不同人工标注者之间的一致性,在此实现中暂时不用管它。
mask为在 DRIVE 数据集的语境里,“mask” 并不是算法生成的二值掩膜,而是人为划定的一块“有效区域”二值图,用来明确告诉使用者:“在这张 565×584 的整幅眼底照片里,只有 mask 像素为 1 的区域才算视网膜有效区域;其余像素(黑色背景、相机边框、光斑、边缘伪影等)一律不参与训练、也不参与指标计算。”
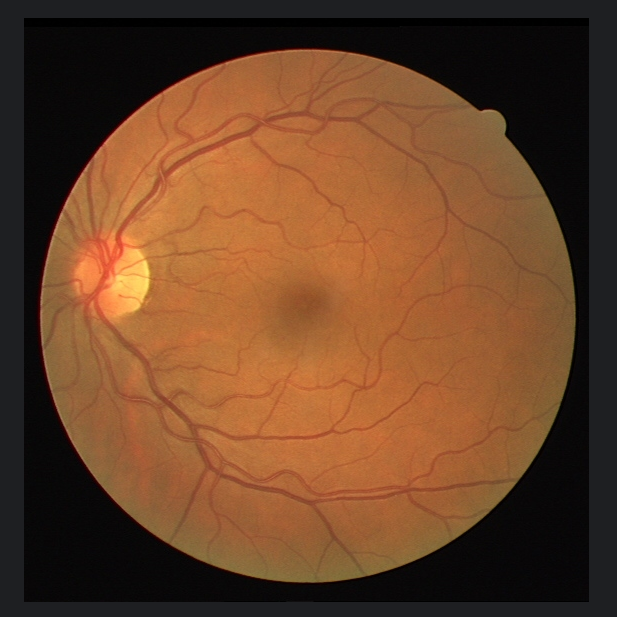

使用mask的原因:
眼底相机拍出来的原始图像是长方形,但视网膜只占中央一个近似圆盘。四周会出现黑色背景(无信号)、光斑、镜像、睫毛影子、相机视场边缘的低信噪比区域。如果把这些区域当成“负样本”去训练或评估,会引入大量虚假 FP(False Positive),指标失真。因此必须先把“可信任区域”抠出来。
Unet网络结构实现
这里写的unet网络结构不同于我之前文章里讲到的,这里做了一些写法上的简化,卷积层做了padding使得尺寸不变,不用裁剪后再拼接,同时加入了BN层。关于BN层可以看博主的文章:https://blog.youkuaiyun.com/qq_73038863/article/details/151801094?fromshare=blogdetail&sharetype=blogdetail&sharerId=151801094&sharerefer=PC&sharesource=qq_73038863&sharefrom=from_link
(1)DoubleConv 模块:
class DoubleConv(nn.Module):
"""
两次(Conv3×3 → BN → ReLU) 堆叠。
参数:
in_channels : 输入通道
out_channels : 输出通道(两次卷积都输出同一通道数)
"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
# 第一次 3×3 卷积
nn.Conv2d(in_channels, out_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
# 第二次 3×3 卷积
nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.double_conv(x)这里的forward函数是所有 nn.Module 子类都必须实现的,训练时调用。
(2)UNet:
class UNet(nn.Module):
def __init__(self, in_channels=1, out_channels=2,
features=[64, 128, 256, 512]):
super(UNet, self).__init__()
self.downs = nn.ModuleList()
self.ups = nn.ModuleList()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)in_channels:网络最入口的通道数。眼底灰度图就填 1,RGB 填 3。
out_channels:最终分割要输出几类。二分类(血管/背景)写 2,多类病灶就写类别数。
features:一个“通道数日程表”。它既决定下采样每一步输出多少通道,也决定对称上采样每一步输入多少通道。
nn.ModuleList 和 Python 列表最大的区别:里面的层能被 model.cuda()、optimizer 识别。里面存放的是下上采样中的操作层。
MaxPool2d(2,2) 就是下采样,把高宽砍一半。
下采样过程:
for feature in features:
self.downs.append(DoubleConv(in_channels, feature))
in_channels = feature等同于:
self.downs += [
DoubleConv( 1, 64), # 0
DoubleConv( 64, 128), # 1
DoubleConv(128, 256), # 2
DoubleConv(256, 512), # 3
]瓶颈层:
self.bottleneck = DoubleConv(features[-1], features[-1] * 2)
# 即 DoubleConv(512, 1024)上采样过程:
for feature in reversed(features): # 512 256 128 64
# 1. 转置卷积:把空间尺寸×2,通道砍半
self.ups.append(
nn.ConvTranspose2d(feature * 2, feature, 2, stride=2)
)
# 2. 拼接后 DoubleConv:输入通道 feature*2,输出 feature
self.ups.append(
DoubleConv(feature * 2, feature)
)相当于:
[0] ConvTranspose2d(1024→512, 2×2/2)
[1] DoubleConv(512+512=1024 → 512)
[2] ConvTranspose2d( 512→256, 2×2/2)
[3] DoubleConv(256+256=512 → 256)
[4] ConvTranspose2d( 256→128, 2×2/2)
[5] DoubleConv(128+128=256 → 128)
[6] ConvTranspose2d( 128→64, 2×2/2)
[7] DoubleConv(64+64=128 → 64)输出:
self.final_conv = nn.Conv2d(features[0], out_channels, kernel_size=1)1×1 卷积,只改变通道数:64 → 2(或你设的类别数)。高宽不变,得到的是每个像素的 raw score(logits)。
(3)forward:
def forward(self, x):
skip_connections = []
for down in self.downs:
x = down(x)
skip_connections.append(x)
x = self.pool(x)
x = self.bottleneck(x)
skip_connections = skip_connections[::-1]
for idx in range(0, len(self.ups), 2):
x = self.ups[idx](x)
skip_connection = skip_connections[idx // 2]
if x.shape != skip_connection.shape:
x = F.interpolate(x, size=skip_connection.shape[2:])
concat_skip = torch.cat((skip_connection, x), dim=1)
x = self.ups[idx + 1](concat_skip)
return self.final_conv(x)1.先准备一个空篮子,用来装“压缩路上”的特征图。
2.下采样:图变成最小:x.shape == (B, 512, H/16, W/16)。篮子里按顺序存了 4 张不同尺寸的特征图(后面要“拼回去”)。
3.瓶颈:再做两次卷积,通道 512→1024,尺寸不变。
4.把篮子倒过来,方便从最小图开始一一配对。
5.上采样。
6.输出。
train.py:
数据处理与数据集构建
定义DriveDataset类处理DRIVE数据集,包含图像、标签和视野(FOV)数据。初始化时指定图像路径、标签路径和FOV路径,并设置图像变换和掩码尺寸。__getitem__方法实现单样本加载,对图像进行RGB转换,标签和FOV转为灰度图,并通过双线性插值调整尺寸。掩码和FOV通过阈值处理转为二值张量。
class DriveDataset(Dataset):
def __init__(self, image_dir, label_dir, fov_dir, transform=None, mask_size=(572, 572)):
self.image_dir = image_dir
self.label_dir = label_dir
self.fov_dir = fov_dir
self.transform = transform
self.mask_size = mask_size
self.images = sorted(os.listdir(image_dir))
self.labels = sorted(os.listdir(label_dir))
self.fovs = sorted(os.listdir(fov_dir))
sorted: 保证三个列表按字典序严格对齐,否则第 i 张图可能拿到别人的标签。
def __len__(self):
return len(self.images)
# 让 DataLoader 知道一共有多少样本;后续 epoch 就循环这么多次。
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.images[idx])
label_path = os.path.join(self.label_dir, self.labels[idx])
fov_path = os.path.join(self.fov_dir, self.fovs[idx])
image = Image.open(img_path).convert("RGB")
mask = Image.open(label_path).convert("L")
fov = Image.open(fov_path).convert("L")
if self.transform:
image = self.transform(image)
# mask & fov resize
mask = mask.resize(self.mask_size, Image.NEAREST)
fov = fov.resize(self.mask_size, Image.NEAREST)
mask = np.array(mask, dtype=np.uint8)
fov = np.array(fov, dtype=np.uint8)
mask = (mask > 128).astype(np.float32)
fov = (fov > 10).astype(np.float32)
mask = torch.from_numpy(mask).unsqueeze(0)
fov = torch.from_numpy(fov).unsqueeze(0)
return image, mask, fov根据索引 idx 把对应的三张图(RGB 眼底、血管标签、FOV 掩膜)读出来、统一 resize 成 572×572、二值化后转成 (0/1) 张量并返回。
损失函数设计
组合BCE损失和Dice损失,平衡分类准确性和区域重叠度。DiceLoss计算预测与真实掩码的交并比,BCEDiceLoss按比例加权两种损失。
关于BCE与Dice的介绍请看作者的这篇文章:
class DiceLoss(nn.Module):
def __init__(self, eps=1e-6):
super(DiceLoss, self).__init__()
self.eps = eps
def forward(self, preds, targets):
preds = torch.sigmoid(preds)
preds = preds.view(-1)
targets = targets.view(-1)
intersection = (preds * targets).sum()
union = preds.sum() + targets.sum()
dice = (2 * intersection + self.eps) / (union + self.eps)
return 1 - dice
class BCEDiceLoss(nn.Module):
def __init__(self):
super(BCEDiceLoss, self).__init__()
self.bce = nn.BCEWithLogitsLoss()
self.dice = DiceLoss()
def forward(self, preds, targets):
return 0.4 * self.bce(preds, targets) + 0.6 * self.dice(preds, targets)训练与验证流程
train_fn:把模型切成训练模式,跑完一个 epoch,返回平均训练损失loss。
eval_fn:把模型切成评估模式,跑完验证集,返回 FOV 区域内的像素准确率 acc 和 Dice 系数。
def train_fn(loader, model, optimizer, criterion, device):
model.train()
total_loss = 0
for imgs, masks, _ in loader:
imgs, masks = imgs.to(device), masks.to(device)
optimizer.zero_grad()
outputs = model(imgs)
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(loader)
def eval_fn(loader, model, device):
model.eval()
correct, total = 0, 0
dice_total = 0.0
with torch.no_grad():
for imgs, masks, fovs in loader:
imgs, masks, fovs = imgs.to(device), masks.to(device), fovs.to(device)
outputs = model(imgs)
preds = torch.sigmoid(outputs)
preds_bin = (preds > 0.5).float()
correct += ((preds_bin == masks) * fovs).sum().item()
total += fovs.sum().item()
intersection = (preds_bin * masks * fovs).sum().item()
union = (preds_bin * fovs).sum().item() + (masks * fovs).sum().item()
dice_total += (2. * intersection + 1e-6) / (union + 1e-6)
acc = correct / total if total > 0 else 0
dice = dice_total / len(loader)
return acc, dice主程序配置
主函数设置数据路径、变换和加载器。初始化UNet模型,使用Adam优化器和混合损失函数。支持CUDA设备自动检测。
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据路径
train_img_dir = "DRIVE/training/images/"
train_label_dir = "DRIVE/training/1st_manual/"
train_fov_dir = "DRIVE/training/mask/"
test_img_dir = "DRIVE/test/images/"
test_label_dir = "DRIVE/test/1st_manual/"
test_fov_dir = "DRIVE/test/mask/"
# transform
transform = transforms.Compose([
transforms.Resize((572, 572)),
transforms.ToTensor(),
])
train_dataset = DriveDataset(train_img_dir, train_label_dir, train_fov_dir, transform=transform)
test_dataset = DriveDataset(test_img_dir, test_label_dir, test_fov_dir, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=2, shuffle=False)
model = UNet(in_channels=3, out_channels=1).to(device)
criterion = BCEDiceLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
num_epochs = 60
best_dice = 0
save_path = "unet_best.pth"
for epoch in range(1, num_epochs + 1):
loss = train_fn(train_loader, model, optimizer, criterion, device)
acc, dice = eval_fn(test_loader, model, device)
if dice > best_dice:
best_dice = dice
torch.save(model.state_dict(), save_path)
print(f"Epoch [{epoch}/{num_epochs}] "
f"Loss: {loss:.4f} Accuracy: {acc:.4f} Dice: {dice:.4f}")
if __name__ == "__main__":
main()
关键实现细节
数据预处理阶段对标签进行二值化处理,让血管=1、背景=0,这样标签才能直接作为 0/1 浮点掩膜去计算 BCE、Dice 等二分类损失,无需再做数值转换。阈值设置为128,因为对 DRIVE 的手工标注(只有 0 和 255)来说,128 就是中间点,能把血管和背景干净地分成 0/1。
FOV掩码用于排除无效区域,仅保留视网膜血管区域。
Dice系数计算引入平滑项避免除零错误,最后得到的Dice越大越好。
训练时采用批处理加速,验证时使用FOV掩码过滤背景。输入图像尺寸统一调整为572x572以匹配UNet架构要求。损失函数权重设置为0.4(BCE)和0.6(Dice)的比例(可改为更合适的)。
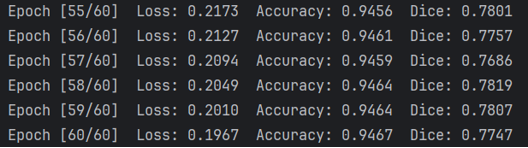
训练结果
实现效果不是那么好,代码还有可以优化的地方,作者目前水平有限,望大家建议指正。


















 1690
1690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









