







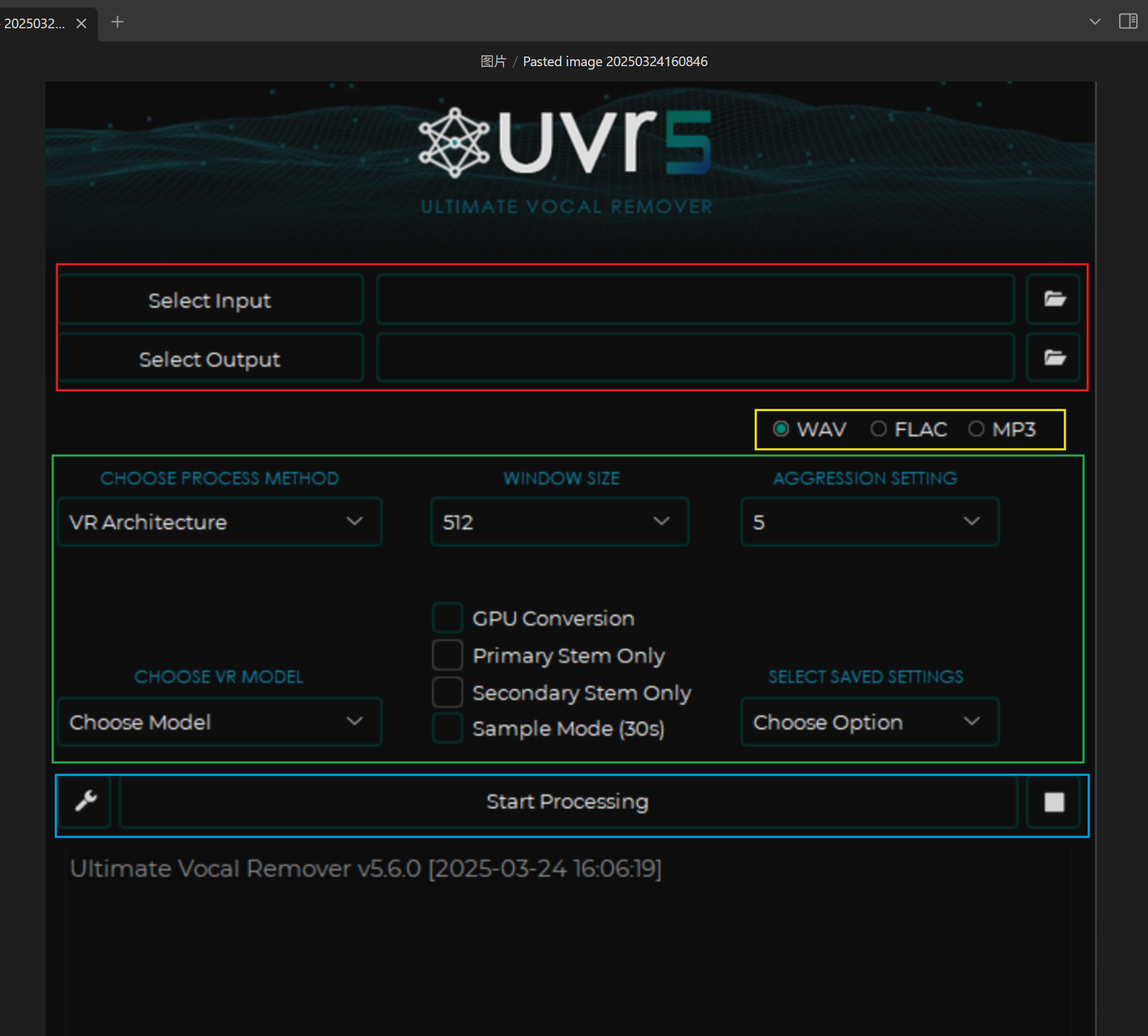
# 第①部分:(红色)
Select Input:导入要处理的音频,可以选择多个音频
Select Output:选择输出音频的目录
# 第②部分:(黄色)
**选择输出音频的格式:**
wav:无损音频,没有被压缩,体积大
flac:无损音频,无损压缩,体积适中
mp3:有损音频,有损压缩,体积小
# 第③部分:(绿色)
## **CHOOSE PROCESS METHOD:选择处理音频的算法**
VR Architecture:使用幅度频谱图进行音源分离。
MDX-Net:采用混合频谱网络进行音源分离。
Demucs:利用混合频谱网络进行音源分离。
Ensemble Mode:将多个模型和网络的结果组合以获得最佳结果。
Audio Tools:提供额外的实用工具,以增加便利性。
**GPU Conversion:使用显卡加速处理(强烈建议勾选,CPU计算的速度非常慢)**
**Sample Mode (??s) :只处理??秒的音频,可以预览结果**
### **如果处理算法选择****VR Architecture**
WINDOW SIZE:选择窗口大小以平衡质量和速度
1024 - 快速但质量较低。
512 - 中等速度和质量。
==320 - 需要更长时间,但可能提供更好的质量。(推荐,实际上慢不了多少)==
AGGRESSION SETTING:调整主音轨提取的强度
可调范围是[-100, 100],较大的值意味着更深的提取。
通常,对于人声和器乐,将其设置为5。
超过5的值可能会使非人声模型的声音变得混浊。
#### 下面的选项会随着不同的模型发生变化
Vocals Only:只提取人声
Instrumental Only:只提取伴奏
No Echo Only:只输出去掉混响的音频
Echo Only:只输出混响部分的音频
No Noise Only:只输出降噪后的音频
Noise Only:只输出噪声部分的音频
### **如果处理算法选择MDX-Net**
SEGMENT SIZE:调整切片大小
较小的大小消耗较少的资源。
较大的大小消耗更多资源,但可能提供更好的结果。
==(默认的256即可,长切片对效果的提升微乎其微)==
OVERLAP:控制预测窗口之间的重叠量
较高的值可能会提供更好的结果,但会导致更长的处理时间。
==(默认即可,实测没啥提升)==
下面的选项会随着不同的模型发生变化
Vocals Only:只提取人声
Instrumental Only:只提取伴奏
No Reverb Only:只输出去掉混响的音频
Reverb Only:只输出混响部分的音频
### **如果处理算法选择Demucs**
CHOOSE STEM(s):选择音轨
Vocals:人声,Bass:贝斯,Drums:鼓,Other:其他乐器
Guitar:吉他,Piano,钢琴(这两项是v4 | htdemucs_6s模型独占)
SEGMENT:调整切片大小
较小的大小消耗较少的资源。
较大的大小消耗更多资源,但可能提供更好的结果。
(默认即可,长切片对效果的提升微乎其微)
### **如果处理算法选择Ensemble Mode**
MAIN STEM PAIR:选择合奏的音轨类型
Vocals/Instrumental:主要音轨:人声,次要音轨:伴奏
Bass/No Bass:主要音轨:贝斯,次要音轨:没有贝斯
Drums/No Drums:主要音轨:鼓,次要音轨:没有鼓
Other/No Other:主要音轨:其他,次要音轨:没有其他
4 Stem Ensemble:汇集所有4音轨Demucs模型并合并所有输出。
Multi-stem Ensemble:"丛林合奏"汇集所有模型并合并相关的输出。(不是很懂QAQ)
ENSEMBLE ALGORITHM:选择用于生成最终输出的合奏算法
例如:Max Spec/Min Spec,斜杠前面的对主要音轨(Primary stem)生效,斜杠后面的对次要音轨(Secondary stem)生效,对于“4音轨合奏(4 Stem Ensemble)”选项,只会显示一个算法。
详细解释:
⚪Max Spec:
产生可能的最高输出。
适用于人声音轨,以获得更丰满的声音,但可能会引入不希望的伪影。
适用于器乐音轨,但请避免在合奏中使用VR Arch模型。
⚪Min Spec:
产生可能的最低输出。
适用于器乐音轨,以获得更清晰的结果。可能会导致“浑浊”的声音。
⚪Average:
将所有结果取平均以生成最终输出。
# 第④部分:(蓝色)
小扳手🔧:打开设置
Start Processing:开始处理
小方块■:停止处理
---
# 使用
下载完模型后开始处理音频,select input选择输入文件,select output选择输出文件夹,输出格式选WAV,记得点上**GPU Conversion**(使用GPU),首先选择**MDX-Net**类型使用**Bs-Roformer**-Viperx-1297(目前最好的提取人声的模型,又快又好)提取人声。处理完的音频(vocals)的是人声。然后把人声再输入去混响(下面三选一):**VR Architecture**:UVR-De-Echo-**Normal**(轻度混响)、UVR-De-Echo-**Aggressive**(重度混响)、UVR-De-Echo-**Dereverb**(变态混响),最后用UVR-**DeNoise**降噪一下。这套流程弄完会比自带的UVR5在人声提取方面好一点。



















 2467
2467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











