









一、模型总体概述
想必大家知道在现代神经网络中,归一化层长期以来被视为关键组件。然而,何恺明他们最新的研究提出的研究表明,通过一种简单的技术,即使用 Dynamic Tanh(DyT)替代归一化层,Transformer 模型能够在不进行归一化的情况下达到甚至超越传统归一化模型的性能。这一发现挑战了目前的传统观念,为深入理解归一化层在神经网络中的作用提供了新视角。
二、模型概述
(一)研究背景
自 2015 年批量归一化(Batch Normalization,BN)提出以来,归一化层在神经网络中得到了广泛应用。层归一化(Layer Normalization,LN)和均方根归一化(Root Mean Square Normalization,RMSNorm)等变体在 Transformer 架构中尤为流行。这些归一化层通过调整输入的均值和方差,有助于加速模型收敛、稳定训练过程并提高模型性能,因此被普遍认为是训练深度神经网络不可或缺的部分。
我这里举例几个上述提出的为什么在transformer架构里要这些归一化层?也可以为了不了解什么是归一化的新人去更好的读懂这篇论文的牛逼之处:
1. 批量归一化(Batch Normalization, BN)
原理
批量归一化是在训练过程中,对每个小批量数据的每个特征维度计算均值和方差,然后对数据进行归一化处理,使得数据的均值为 0,方差为 1。之后,通过可学习的缩放因子 和偏移因子
对归一化后的数据进行缩放和平移,以恢复数据的表达能力。其公式为:
其中, 是输入数据,
和 分别是小批量数据的均值和方差,
是一个小的常数,用于避免除零错误,
和
是可学习的参数。我这里构建一个简单的归一化,下面是构建的流程图,可以作一下参照:
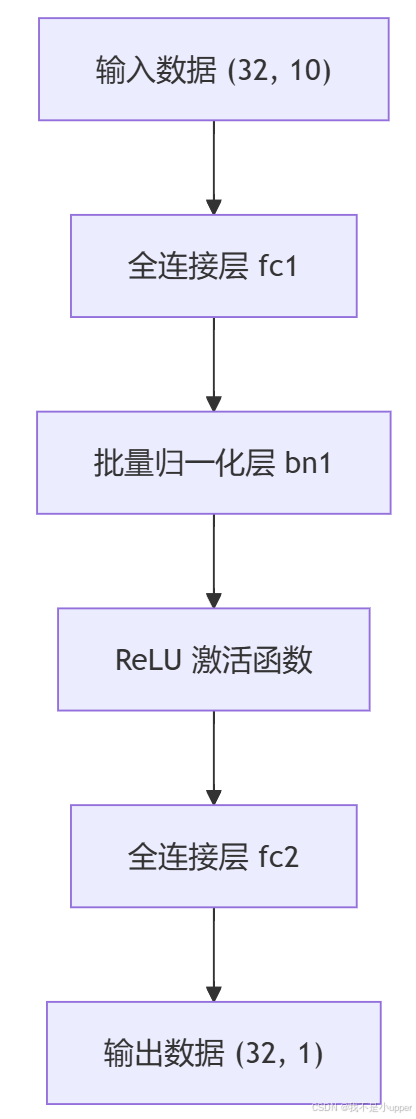
下面是复现批量归一化的代码示例:
import torch
import torch.nn as nn
# 定义一个简单的神经网络模型,包含批量归一化层
class SimpleNetWithBN(nn.Module):
def __init__(self):
super(SimpleNetWithBN, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.bn1 = nn.BatchNorm1d(20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = self.bn1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
# 创建模型实例
model = SimpleNetWithBN()
# 生成一些随机输入数据
input_data = torch.randn(32, 10)
# 前向传播
output = model(input_data)
print(output.shape)看不懂代码的同学我这里给代码做一下解释,我在这里导入了 torch 库,它是 PyTorch 的核心库,提供了张量计算和自动求导等功能;torch.nn 是 PyTorch 中用于构建神经网络的模块,包含了各种神经网络层和损失函数等。
然后定义包含批量归一化层的简单神经网络模型,对于类的定义- SimpleNetWithBN 类继承自 nn.Module,这是 PyTorch 中所有神经网络模块的基类。然后就是__init__ 方法,super(SimpleNetWithBN, self).__init__():调用父类 nn.Module 的构造函数,确保正确初始化。然后定义一个全连接层(线性层)self.fc1 = nn.Linear(10, 20),输入维度为 10,输出维度为 20。全连接层将输入数据进行线性变换。再去定义一个一维批量归一化层self.bn1 = nn.BatchNorm1d(20),输入特征维度为 20。批量归一化层用于对输入数据进行归一化处理,使得数据的均值为 0,方差为 1,然后通过可学习的缩放因子和偏移因子进行调整。最后再定义另一个全连接层self.fc2 = nn.Linear(20, 1),输入维度为 20,输出维度为 1。
再用forward 方法去定义模型的前向传播过程。x = self.fc1(x)是将输入数据 x 通过第一个全连接层进行线性变换。然后命名x = self.bn1(x)对经过第一个全连接层的输出进行批量归一化处理。再用x = torch.relu(x)对批量归一化后的输出应用 ReLU 激活函数,引入非线性。ReLU 函数的公式为 。最后,
x = self.fc2(x):将经过激活函数处理后的输出通过第二个全连接层进行线性变换,得到最终的输出,这样就可以创建模型的实例了(其实就是实例化 SimpleNetWithBN 类,创建一个具体的模型对象。)。
model = SimpleNetWithBN()我们使用 torch.randn 函数生成一个形状为 (32, 10) 的随机张量作为输入数据。这里的 32 表示批量大小,即一次处理 32 个样本;10 表示每个样本的特征维度。将输入数据 input_data 输入到模型中进行前向传播,得到模型的输出 output。然后打印输出的形状。由于第二个全连接层的输出维度为 1,批量大小为 32,所以输出的形状应该是 (32, 1)。
2. 层归一化(Layer Normalization, LN)
原理
层归一化是对每个样本的所有特征维度进行归一化处理,即计算每个样本的均值和方差,然后对该样本的所有特征进行归一化。其公式与批量归一化类似: 其中,
和
是当前样本的均值和方差。
这里我会根据下面的流程图复现一下层归一化的代码:
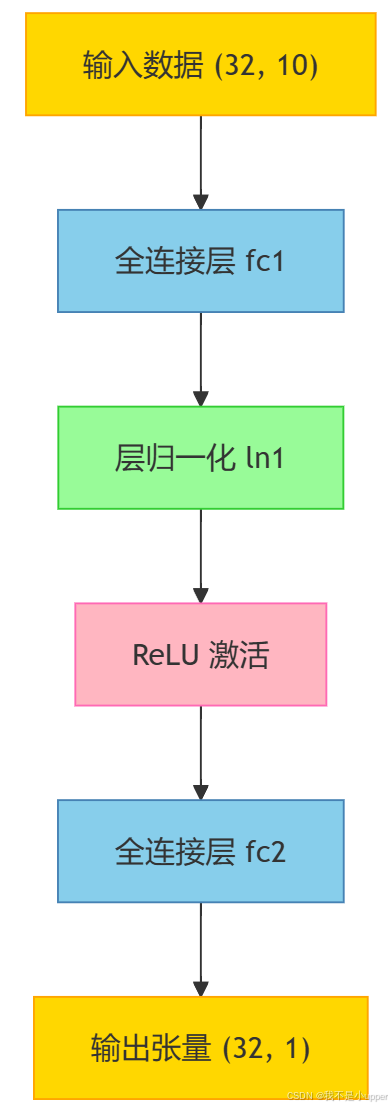
复现代码:
import torch
import torch.nn as nn
# 定义一个简单的神经网络模型,包含层归一化层
class SimpleNetWithLN(nn.Module):
def __init__(self):
super(SimpleNetWithLN, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.ln1 = nn.LayerNorm(20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = self.ln1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
# 创建模型实例
model = SimpleNetWithLN()
# 生成一些随机输入数据
input_data = torch.randn(32, 10)
# 前向传播
output = model(input_data)
print(output.shape)可能对于 批量化归一化的解释有些读者朋友有些晦涩难懂,这里我将尝试换一种方法去阐述我代码的复现过程和思路:
1. 输入层
输入的数据形状: torch.Size([32, 10])
- 32 个样本,每个样本 10 个特征
- 对应代码:
input_data = torch.randn(32, 10)
2. 全连接层 fc1
nn.Linear(10, 20) # 输入维度 10 → 输出维度 20 输出形状: torch.Size([32, 20])- 权重矩阵:
20 × 10 - 公式:
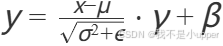
3. 层归一化 ln1
nn.LayerNorm(20) # 对最后一个维度归一化 输出形状: torch.Size([32, 20])- 对每个样本的 20 维特征进行归一化
- 计算公式:
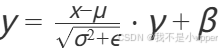
4. ReLU 激活
torch.relu(x) # 非线性激活 输出形状: torch.Size([32, 20])- 将负值置零:ReLU(x)=max(0,x)ReLU(x)=max(0,x)
- 保持维度不变
5. 全连接层 fc2
nn.Linear(20, 1) # 输入维度 20 → 输出维度 1 输出形状: torch.Size([32, 1])- 权重矩阵:
1 × 20 - 最终输出每个样本的预测值
输出验证
print(output.shape) # 输出: torch.Size([32, 1])- 32 个样本 → 32 个预测结果
- 每个结果维度为 1(回归任务典型输出)
3. 均方根归一化(Root Mean Square Normalization, RMSNorm)
原理
均方根归一化是对层归一化的一种简化,它只考虑了输入数据的方差,而不考虑均值。其公式为:
其中,n 是特征维度的数量。
同理,我会根据下面的流程图复现一下层归一化的代码:
顺带提一嘴RMSNorm的内部流程是啥样的:
复现代码:
import torch
import torch.nn as nn
# 自定义 RMSNorm 层
class RMSNorm(nn.Module):
def __init__(self, dim, eps=1e-8):
super(RMSNorm, self).__init__()
self.eps = eps
self.gamma = nn.Parameter(torch.ones(dim))
def forward(self, x):
norm_x = torch.norm(x, dim=-1, keepdim=True)
rms_x = norm_x * x.size(-1) ** (-0.5)
x_normed = x / (rms_x + self.eps)
return self.gamma * x_normed
# 定义一个简单的神经网络模型,包含 RMSNorm 层
class SimpleNetWithRMSNorm(nn.Module):
def __init__(self):
super(SimpleNetWithRMSNorm, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.rmsnorm1 = RMSNorm(20)
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = self.rmsnorm1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
# 创建模型实例
model = SimpleNetWithRMSNorm()
# 生成一些随机输入数据
input_data = torch.randn(32, 10)
# 前向传播
output = model(input_data)
print(output.shape)1. 同样,首先定义一个输入层,其输入形状是批量大小 32,特征维度 10 代码里面表现为torch.Size([32, 10])
2. 定义全连接层 fc1
nn.Linear(10, 20) # 线性变换
输出形状: torch.Size([32, 20])
公式为:![]()
3. 然后定义 RMSNorm 层(个人认为这个是核心创新点),因为与传统 LayerNorm 对比的的话RMSNorm的计算量更低,归一化基准是采用的是RMS, 而LayerNorm是用的均值方差, 而且RMSNorm层可以在大模型/长序列场景适用,而LayerNorm只能适用于常规模型。 下面是代码展示:
class RMSNorm(nn.Module):
def __init__(self, dim, eps=1e-8):
self.gamma = nn.Parameter(torch.ones(dim)) # 可学习参数
self.eps = eps
def forward(self, x):
norm_x = torch.norm(x, dim=-1, keepdim=True) # L2 范数
rms_x = norm_x * x.size(-1) ** (-0.5) # RMS 计算
x_normed = x / (rms_x + self.eps) # 归一化
return self.gamma * x_normed # 缩放
4. ReLU 激活(保留正数,负数置零)
x = torch.relu(x) # 非线性激活
输出形状: torch.Size([32, 20])
5. 全连接层 fc2(回归任务典型输出)
nn.Linear(20, 1) # 最终预测层
输出形状: torch.Size([32, 1])
最后输出验证:
print(output.shape) # 输出: torch.Size([32, 1])
扯回论文😄
(二)Dynamic Tanh(DyT)的提出
研究发现,LN 层的输入输出映射呈现出类似 tanh 函数的 S 型曲线,基于此,提出了 Dynamic Tanh(DyT)。DyT 的定义为:,其中
是可学习的标量参数,用于根据输入范围对输入进行缩放;
和
是可学习的向量参数,类似于归一化层中的缩放和平移参数,使输出能够恢复到任意范围。
三、归一化层剖析
(一)归一化层的通用公式
大多数归一化层的通用公式为:,其中
是一个小常数,防止分母为零;
和
是可学习的向量参数,用于缩放和平移输出;
和
分别是输入的均值和方差,不同的归一化方法主要区别在于这两个统计量的计算方式。
(二)常见归一化层(可见文章上一节,写的非常详细)
- 批量归一化(BN):主要用于卷积神经网络(ConvNet),计算均值和方差时考虑批量和令牌维度,公式为:
和
。
- 层归一化(LN):在 Transformer 架构中广泛使用,为每个样本中的每个令牌独立计算统计量,公式为:
和
。
- 均方根归一化(RMSNorm):简化了 LN,去除了均值中心化步骤,公式为:
和
。目前,LN 因其简单性和通用性在大多数现代神经网络中被广泛使用,而 RMSNorm 在一些语言模型(如 T5、LLaMA 等)中受到青睐。
四、DyT 的设计机制
(一)DyT 的设计灵感
通过对训练后的网络中归一化层行为的实证研究发现,LN 层在较深层的输入输出关系呈现出类似 tanh 函数的 S 型曲线。尽管 LN 层的操作本质上是线性的,但由于不同令牌具有不同的均值和标准差,整体上对输入张量的激活表现出非线性变换,这种非线性变换与缩放后的 tanh 函数高度相似。
(二)DyT 的工作原理
DyT 通过可学习的参数 对输入进行缩放,然后利用 tanh 函数对极端值进行压缩,从而模拟归一化层的行为。在训练过程中,
会根据输入激活的标准差动态调整,以保持激活值在合适的范围内,实现稳定有效的训练。
五、代码复现
(一)DyT 层的代码实现(以 PyTorch 为例)
import torch
import torch.nn as nn
class DyT(nn.Module):
def __init__(self, C, init_α):
super().__init__()
self.β = nn.Parameter(torch.zeros(C))
self.α = nn.Parameter(torch.ones(1) * init_α)
self.γ = nn.Parameter(torch.ones(C))
def forward(self, x):
x = torch.tanh(self.α * x)
return self.γ * x + self.β上述代码的参数说明:
| 参数 | 形状 | 功能 | 初始化策略 |
|---|---|---|---|
β | (C,) | 通道级偏置 | 全零初始化 |
α | (1,) | 输入动态缩放因子 | 用户指定初始值 init_α |
γ | (C,) | 通道级输出缩放 | 全一初始化 |
其前向传播流程:
-
动态输入缩放
x = torch.tanh(self.α * x)---通过可学习参数α对输入进行缩放,使用tanh将值约束到(-1, 1)范围 -
通道级变换
return self.γ * x + self.β---对每个通道应用独立的缩放 (γ) 和偏置 (β)
设计优势分析
1. 动态激活幅度
- 优势:通过可学习的
α参数,网络可以自动调整 tanh 激活前的输入幅度,解决传统tanh固定幅度可能导致的梯度消失问题。 - 对比传统方法:
传统tanh的输入范围固定,而DyT的α可根据数据分布自适应调整。
2. 通道级可学习参数
- 优势:
γ和β为每个通道提供独立的缩放和偏置,增强模型对不同通道特征的表达能力。 - 适用场景:
在处理多通道数据(如图像的 RGB 通道)时,允许不同通道有不同的非线性变换。
3. 可控的初始化
- 优势:
init_α参数允许用户指定初始缩放强度,例如:init_α=1:初始行为接近标准tanhinit_α=0.1:初始阶段近似线性变换,逐步学习非线性
- 调参意义:
可通过调整init_α控制模型训练初期的稳定性。
4. 梯度稳定性
- 数学分析:
tanh的导数范围为(0, 1],通过α缩放后的导数变为: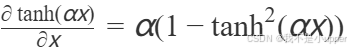
可学习的α能够动态平衡梯度大小。
5. 计算高效性
- FLOPs:
相比其他复杂激活函数(如 Swish),DyT仅增加 3 个可学习参数,计算量与tanh相近。
与传统激活函数对比
| 激活函数 | 可学习参数 | 通道级适应 | 动态幅度 | 典型应用场景 |
|---|---|---|---|---|
ReLU | 无 | 否 | 否 | 通用深度学习模型 |
tanh | 无 | 否 | 否 | RNN/特征归一化 |
DyT(本文) | 3 组参数 | 是 | 是 | 多通道数据/动态特征 |
SELU | 无 | 否 | 否 | 自归一化网络 |
因此,我认为在传统激活函数与DyT的对比中,ReLU作为通用深度学习模型的首选激活函数,其无参数特性保证了计算效率,但固定的非线性输出模式在面对多通道数据时缺乏对不同特征通道的差异化处理能力。tanh 函数虽然通过输出以零为中心的特性缓解了梯度偏移问题,但其静态的幅度限制在循环神经网络等序列建模任务中难以适应动态变化的特征分布。SELU通过自归一化特性在深层网络中保持梯度稳定,但固定的激活幅度限制了模型对复杂非线性关系的捕捉精度。
而DyT通过引入可学习的 α 缩放因子和通道级参数 γ、β,实现了动态幅度调整与通道级适应的双重优化。其中 α 参数允许模型根据输入分布自动调整激活函数的敏感区域,有效缓解传统 tanh 在极端值区域的梯度消失问题;通道级参数则为不同特征通道提供独立的非线性变换空间,这种细粒度控制特别适用于多模态数据融合或图像处理任务中通道间差异性显著的应用场景。相较于SELU 等固定激活函数,DyT的三组可学习参数构成的动态调节机制,使模型能够自适应地平衡特征表达强度与梯度传播稳定性,可以在动态特征建模任务中展现出更强的环境适应能力。
(二)在 Transformer 模型中使用 DyT 替换归一化层
在 Transformer 模型中,将原本的归一化层(如 LN 或 RMSNorm)替换为 DyT 层。以基于 PyTorch 的简单 Transformer 模块为例:
import torch
import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, C, init_α):
super().__init__()
# 假设这里有注意力层、前馈网络层等
# 用DyT替换归一化层
self.dyt = DyT(C, init_α)
def forward(self, x):
# 注意力层和前馈网络层的计算
# 这里省略具体计算过程,假设得到输出为out
out = self.dyt(out)
return out
(三)实验设置中的代码示例(以图像分类任务为例)
下面是使用 PyTorch 实现的一个对比示例代码,展示了使用 Dynamic Tanh(DyT)替换层归一化(LN)前后训练 Vision Transformer(ViT)模型的过程:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, ToTensor, Resize
from torch.utils.data import DataLoader
from torchvision.models import vit_b_16
# 定义 DyT 层
class DyT(nn.Module):
def __init__(self, C, init_α):
super().__init__()
self.β = nn.Parameter(torch.zeros(C))
self.α = nn.Parameter(torch.ones(1) * init_α)
self.γ = nn.Parameter(torch.ones(C))
def forward(self, x):
x = torch.tanh(self.α * x)
return self.γ * x + self.β
# 替换 LN 为 DyT
def replace_ln_with_dyt(model, init_α):
for name, module in model.named_modules():
if isinstance(module, nn.LayerNorm):
layer_index = int(name.split('.')[-1])
setattr(model, name, DyT(module.normalized_shape[0], init_α))
return model
# 训练函数
def train_model(model, train_loader, criterion, optimizer, epochs):
model.train()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(epochs):
running_loss = 0.0
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')
# 定义数据转换
transform = Compose([
Resize((224, 224)),
ToTensor()
])
# 加载数据集
train_dataset = CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 初始化超参数
epochs = 5
init_α = 0.5
# 使用 LN 的 ViT 模型
vit_model_with_ln = vit_b_16()
criterion_ln = nn.CrossEntropyLoss()
optimizer_ln = optim.AdamW(vit_model_with_ln.parameters(), lr=4e-3)
print("Training ViT model with Layer Normalization:")
train_model(vit_model_with_ln, train_loader, criterion_ln, optimizer_ln, epochs)
# 使用 DyT 替换 LN 的 ViT 模型
vit_model_with_dyt = vit_b_16()
vit_model_with_dyt = replace_ln_with_dyt(vit_model_with_dyt, init_α)
criterion_dyt = nn.CrossEntropyLoss()
optimizer_dyt = optim.AdamW(vit_model_with_dyt.parameters(), lr=4e-3)
print("\nTraining ViT model with Dynamic Tanh (DyT):")
train_model(vit_model_with_dyt, train_loader, criterion_dyt, optimizer_dyt, epochs)代码解释
- DyT 层定义:
DyT类实现了 Dynamic Tanh 层,包含可学习的参数、
和
。
- 替换函数:
replace_ln_with_dyt函数用于将 ViT 模型中的所有层归一化(LN)层替换为 DyT 层。 - 训练函数:
train_model函数用于训练模型,包括前向传播、计算损失、反向传播和参数更新。 - 数据集加载:使用
CIFAR10数据集作为示例,将其加载到DataLoader中。 - 训练对比:首先训练使用层归一化(LN)的 ViT 模型,然后训练使用 DyT 替换 LN 的 ViT 模型,并打印每个 epoch 的损失。
(二)实验结果(各位可以自行运行上述的代码试一试)
- 在监督学习的视觉任务中,DyT 在不同架构和模型大小上的性能略优于 LN。
- 在视觉自监督学习、扩散模型、大语言模型、语音自监督学习和 DNA 序列建模等任务中,DyT 与 LN 的性能相当。
- 效率方面,DyT 层相比 RMSNorm 层显著减少了计算时间,在推理和训练阶段都有明显的时间缩减,表明 DyT 可能是面向效率的网络设计的有前途的选择。
七、结果分析
(一)效率分析
对 LLaMA 7B 模型的基准测试也表明,DyT 层在推理和训练过程中的计算时间显著低于 RMSNorm 层。这是因为 DyT 的计算相对简单,不需要像归一化层那样计算复杂的统计量,从而减少了计算开销。
(二)tanh 和 α 的作用分析
- tanh 函数的作用:通过实验将 tanh 替换为其他压缩函数(如 hardtanh 和 sigmoid),发现 tanh 函数在保持模型训练稳定性和性能方面表现最佳。这可能归因于 tanh 函数的平滑性和零中心特性,有助于梯度的稳定传播。
- α 的作用:去除可学习的 α 会导致模型性能下降,表明 α 在增强模型性能方面起着关键作用。在训练过程中,α 紧密跟踪激活的标准差的倒数,其值在训练初期下降,然后上升,但始终与输入激活的标准差波动一致。这表明 α 部分起到了归一化机制的作用,通过学习近似于输入激活标准差倒数的值,使模型能够稳定有效地训练。
(三)α 的初始化分析
- 非 LLM 模型:非 LLM 模型对
(α 的初始值)相对不敏感,在广泛的
设置为非 LLM 模型的默认值。
- LLM 模型:调整
(四)与其他方法的比较
与其他使 Transformer 无需归一化层进行训练的方法(如 Fixup、SkipInit 和 σReparam)相比,DyT 在不同配置下始终表现出更优的性能。尽管这些方法通过调整初始参数值或对网络权重施加约束来实现无归一化训练,但 DyT 在简单性和性能方面具有明显优势。
八、研究结论
通过引入大神发布的 Dynamic Tanh(DyT),证明了 Transformer 等现代神经网络可以在不使用归一化层的情况下进行有效训练。DyT 通过简单的结构调整,成功模拟了归一化层的行为,在多种任务和领域中,使用 DyT 的模型与使用传统归一化层的模型性能相当甚至更优。这一发现挑战了归一化层在神经网络中不可或缺的传统观念,为神经网络的设计和优化提供了新的思路和方法。同时,研究还发现 DyT 在提高训练和推理效率方面具有潜力,为未来高效网络的设计提供了新的方向。然而,DyT 在替代某些经典网络(如 ResNets)中的批量归一化层时存在困难,这为后续研究留下了探索空间,有待进一步深入研究如何使 DyT 更好地适应不同类型的网络架构和归一化需求。


















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









