




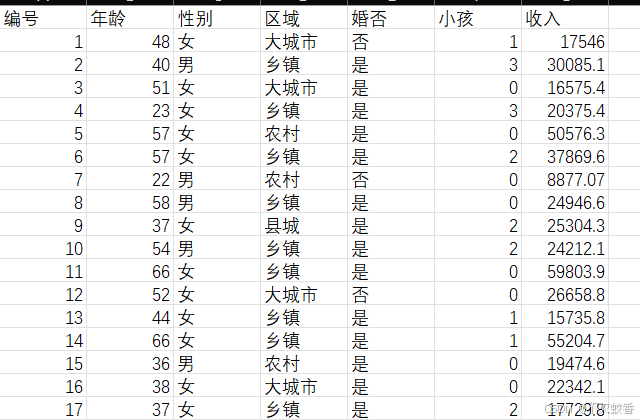
题目:现有一张数据表格,要求通过年龄、性别、区域、婚否、小孩等预测收入。
依赖库:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pdstep1:处理数据
将表中数据读取出来并存进数据结构里面
def data_preprocessing(path):
data = pd.read_csv(path, encoding='gbk')
y = data['收入'] / 1000
x1 = data['年龄']
x2 = data.apply(lambda x: 2 if x['性别'] == '男' else 1, axis=1)
area = {'大城市': 4, '县城': 3, '乡镇': 2, '农村': 1}
x3 = data.apply(lambda x: area[x['区域']] if x['区域'] in area else 0, axis=1)
x4 = data.apply(lambda x: 2 if x['婚否'] == '是' else 1, axis=1)
x5 = data['小孩']
# 追加1列初始值为1做为矩阵运算的偏置项
data['偏置项'] = 1
res = np.column_stack([y, data['偏置项'], x1, x2, x3, x4, x5])
return resstep2:构造损失函数(均方差)
这里本来应该构造模型函数f(x),再构建损失函数Loss(w)的,但多元线性函数较为简单就直接构建损失函数了。
def loss(w, data):
"""
计算损失函数值
:param w: 参数w
:param data: 数据集
:return: 损失函数值
"""
y = data[..., 0: 1]
x = data[..., 1:]
return np.mean(np.square(np.matmul(x, w) - y)) / 2step3:对损失函数求导,得到偏导函数(梯度函数)
以一个一元线性方程为例求偏导数为例
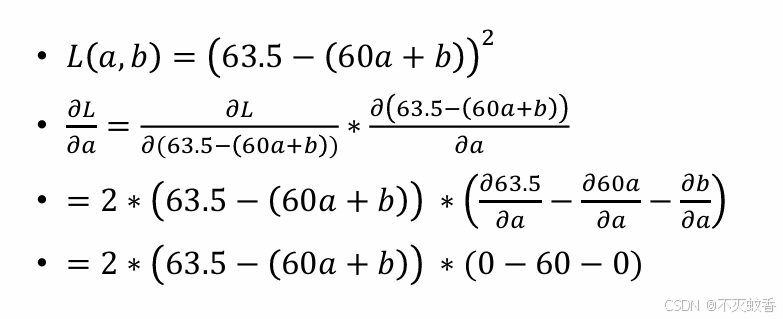
进而得出多元偏导也是一样的:
def loss_dw(w, data):
"""
计算损失函数对w的偏导数
:param w: 参数w
:param data: 数据集
:return: 损失函数对w的偏导数
"""
y = data[..., 0: 1]
x = data[..., 1:]
return np.matmul(np.transpose(x), np.matmul(x, w) - y)step4:梯度下降算法训练优化参数w
这里以Adam为例:
def get_batches(data, batch_size=40):
"""
按batch_size划分小批量数据
:param data: 全部样本
:param batch_size: 划分大小
:return: 分好的样本数据
"""
for i in range(0, data.shape[0], batch_size):
yield data[i:i + batch_size]
def Adam(w, data, batch_size, epochs = 100, alpha=1e-6, beta=1e-10, epsilon=1e-10, beta1=0.9, beta2=0.999, learning_rate=0.001):
"""
使用Adam算法优化参数w
:param w: 初始参数
:param data: 样本数据
:param alpha: 梯度阈值
:param beta: 损失值变化阈值
:param epsilon: 防止除零的小常数
:param beta1: 一级动量因子
:param beta2: 二级动量因子
:param learning_rate: 学习率
:return: 优化后的参数w,步数列表和损失列表
"""
k = 0
m = 0
v = 0
list_loss, list_i = [], [] # 用于存储损失值和步数
for _ in range(epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size):
k += 1
gradient = loss_dw(w, batch) # 计算梯度
gradient_modlue = np.sqrt(np.sum((np.square(gradient)))) # 计算梯度的范数
loss_ab = loss(w, batch) # 计算当前损失函数值
list_loss.append(loss_ab)
list_i.append(k)
print(f'Step {k:02d}: \nw={w}\tloss={loss_ab:.18f}\tgrad={gradient_modlue:.18f}')
if gradient_modlue <= alpha:
return w, list_i, list_loss # 如果梯度的范数小于阈值,停止迭代
# 更新一阶动量
m = beta1 * m + (1 - beta1) * gradient
# 更新二阶动量
v = beta2 * v + (1 - beta2) * np.square(gradient)
# 偏差校正
M = m / (1 - beta1 ** k)
V = v / (1 - beta2 ** k)
# 更新参数
w = w - learning_rate * M / (np.sqrt(V) + epsilon)
if abs(loss(w, batch) - loss_ab) <= beta:
return w, list_i, list_loss # 如果损失函数值的变化小于阈值,停止迭代
return w, list_i, list_lossstep5:整理整个流程,在main函数调用
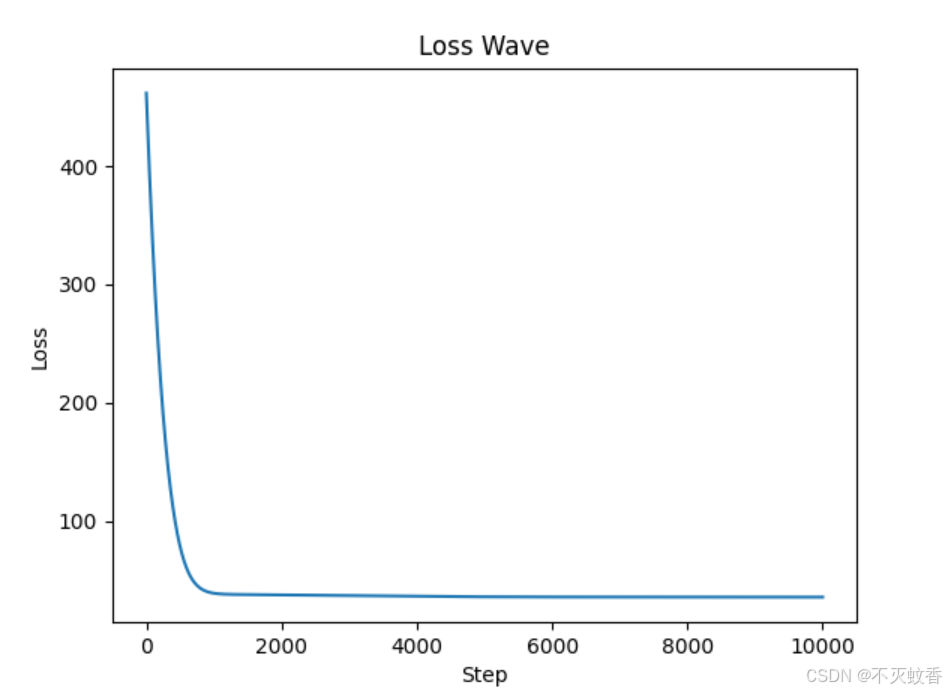
def draw(steps, losses):
"""
绘制损失函数随步数变化的图
:param steps: 步数
:param losses: 损失函数值
"""
plt.plot(steps, losses)
plt.xlabel('Step')
plt.ylabel('Loss')
plt.title('Loss Wave')
plt.show()
if __name__ == '__main__':
# 获取样本数据
data = data_preprocessing('多元线性回归数据.csv')
# 初始化参数
w = np.zeros([6, 1])
batch_size = 600
# 使用Adam算法进行优化
w_opt, steps, losses = Adam(w, data, batch_size, epochs=10000)
# 打印优化后的参数
print(f'Optimized parameters: \nw = {w_opt} loss = {loss(w, data)}')
# 绘制损失函数随步数变化的图
draw(steps, losses)得出训练结果:
注:附上其他六种梯度下降算法源码
SGD:
def SGD(w, data, batch_size=-1, learning_rate=0.00000001, epochs=1000, alpha=1e-8,
beta=1e-8, loss=loss, loss_dw=loss_dw):
"""
使用随机梯度下降算法优化参数w
:param w: 初始参数w
:param learning_rate: 学习率
:param data: 样本数据
:param alpha: 梯度阈值
:param beta: 损失值变化阈值
:param loss: 损失函数
:param loss_dw: 损失函数对w的偏导数
:return: 优化后的参数a和b,步数列表和损失列表
"""
k = 0
list_loss, list_i = [], [] # 用于存储损失值和步数
for _ in range(epochs):
for batch in get_batches(data, batch_size):
k += 1
gradient = loss_dw(w, batch) # 计算梯度
gradient_modlue = np.sqrt(np.sum((np.square(gradient)))) # 计算梯度的范数
loss_ab = loss(w, batch) # 计算当前损失函数值
list_loss.append(loss_ab)
list_i.append(k)
print(f'Step {k:02d}: loss={loss_ab:.18f}\tgrad={gradient_modlue:.18f}')
if gradient_modlue <= alpha and alpha != -1:
return w, list_i, list_loss # 如果梯度的范数小于阈值,停止迭代
# 更新参数
w = w - learning_rate * gradient
if abs(loss(w, batch) - loss_ab) <= beta and beta != -1:
return w, list_i, list_loss # 如果损失函数值的变化小于阈值,停止迭代
return w, list_i, list_lossMomentum:
def Momentum(w, data, batch_size=-1, learning_rate=0.000000002, epochs=1000, alpha=1e-8,
beta=1e-8, gamma=0.5, loss=loss, loss_dw=loss_dw):
"""
使用动量随机梯度下降算法优化参数w
:param w: 初始参数(w0, w1)
:param learning_rate: 学习率
:param data: 样本数据
:param alpha: 梯度阈值
:param beta: 损失值变化阈值
:param gamma: 动量因子
:param loss: 损失函数
:param loss_dw: 损失函数对w的偏导数
:return: 优化后的参数w,步数列表和损失列表
"""
k = 0
v = 0
list_loss, list_i = [], [] # 用于存储损失值和步数
for _ in range(epochs):
for batch in get_batches(data, batch_size):
k += 1
gradient = loss_dw(w, batch) # 计算损失函数的梯度
gradient_modlue = np.sqrt(np.sum((np.square(gradient)))) # 计算梯度的范数
loss_w = loss(w, batch) # 计算当前损失函数值
list_loss.append(loss_w)
list_i.append(k)
print(f'Step {k:02d}: \tloss={loss_w:.18f}\tgrad={gradient_modlue:.18f}')
if gradient_modlue <= alpha and alpha != -1:
return w, list_i, list_loss # 如果梯度的范数小于阈值,停止迭代
# 更新动量
v = v * gamma + learning_rate * gradient
# 更新参数
w = w - v
if abs(loss(w, batch) - loss_w) <= beta and beta != -1:
return w, list_i, list_loss # 如果损失函数值的变化小于阈值,停止迭代
return w, list_i, list_lossNAG:
def NAG(w, data, batch_size=-1, learning_rate=0.000000003, epochs=1000, alpha=1e-8,
beta=1e-8, gamma=0.5, loss=loss, loss_dw=loss_dw):
"""
使用Nesterov加速梯度下降算法优化参数w
:param w: 初始参数(w0, w1)
:param learning_rate: 学习率
:param data: 样本数据
:param alpha: 梯度阈值
:param beta: 损失值变化阈值
:param gamma: 动量因子
:param loss: 损失函数
:param loss_dw: 损失函数对w的偏导数
:return: 优化后的参数w,步数列表和损失列表
"""
k = 0
v = 0
list_loss, list_i = [], [] # 用于存储损失值和步数
for _ in range(epochs):
for batch in get_batches(data, batch_size):
k += 1
w_pred = w - gamma * v # 计算预测参数
gradient = loss_dw(w_pred, batch) # 计算预测参数损失函数的梯度
gradient_modlue = np.sqrt(np.sum((np.square(gradient)))) # 计算梯度的范数
loss_w = loss(w, batch) # 计算当前损失函数值
list_loss.append(loss_w)
list_i.append(k)
print(f'Step {k:02d}: loss={loss_w:.18f}\tgrad={gradient_modlue:.18f}')
if gradient_modlue <= alpha and alpha != -1:
return w, list_i, list_loss # 如果梯度的范数小于阈值,停止迭代
# 更新动量
v = gamma * v + learning_rate * gradient
# 更新参数
w = w - v
if abs(loss(w, batch) - loss_w) <= beta and beta != -1:
return w, list_i, list_loss # 如果损失函数值的变化小于阈值,停止迭代
return w, list_i, list_lossAdagrad:
def Adagrad(w, data, batch_size=-1, learning_rate=0.03, epochs=1000, alpha=1e-8,
beta=1e-8, epsilon=1e-6, loss=loss, loss_dw=loss_dw):
"""
使用Adagrad算法优化参数w
:param w: 初始参数(w0, w1)
:param learning_rate: 学习率
:param data: 样本数据
:param alpha: 梯度阈值
:param beta: 损失值变化阈值
:param epsilon: 防止除零的小常数
:param loss: 损失函数
:param loss_dw: 损失函数对w的偏导数
:return: 优化后的参数w,步数列表和损失列表
"""
k = 0
E_g = 0 # 初始化累积梯度平方
list_loss, list_i = [], [] # 用于存储损失值和步数
for _ in range(epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size):
k += 1
gradient = loss_dw(w, batch) # 计算损失函数的梯度
gradient_modlue = np.sqrt(np.sum((np.square(gradient)))) # 计算梯度的范数
loss_w = loss(w, batch) # 计算当前损失函数值
list_loss.append(loss_w)
list_i.append(k)
print(f'Step {k:02d}: \tloss={loss_w:.18f}\tgrad={gradient_modlue:.18f}')
if gradient_modlue <= alpha and alpha != -1:
return w, list_i, list_loss # 如果梯度的范数小于阈值,停止迭代
# 更新累积梯度平方
E_g = E_g + np.square(gradient)
# 更新参数
w = w - (learning_rate / np.sqrt(E_g + epsilon)) * gradient
if abs(loss(w, batch) - loss_w) <= beta and beta != -1:
return w, list_i, list_loss # 如果损失函数值的变化小于阈值,停止迭代
return w, list_i, list_loss
RMSprop:
def RMSprop(w, data, batch_size=-1, learning_rate=0.001, epochs=1000, alpha=1e-8,
beta=1e-8, epsilon=1e-6, gamma=0.9, loss=loss, loss_dw=loss_dw):
"""
使用RMSprop算法优化参数w
:param w: 初始参数(w0, w1)
:param learning_rate: 学习率
:param data: 样本数据
:param alpha: 梯度阈值
:param beta: 损失值变化阈值
:param epsilon: 防止除零的小常数
:param gamma: 梯度平方的衰减率
:param loss: 损失函数
:param loss_dw: 损失函数对w的偏导数
:return: 优化后的参数w,步数列表和损失列表
"""
k = 0
E_g = 0 # 初始化累积梯度平方
list_loss, list_i = [], [] # 用于存储损失值和步数
for _ in range(epochs):
for batch in get_batches(data, batch_size):
k += 1
gradient = loss_dw(w, batch) # 计算损失函数的梯度
gradient_modlue = np.sqrt(np.sum((np.square(gradient)))) # 计算梯度的范数
loss_w = loss(w, batch) # 计算当前损失函数值
list_loss.append(loss_w)
list_i.append(k)
print(f'Step {k:02d}: \tloss={loss_w:.18f}\tgrad={gradient_modlue:.18f}')
if gradient_modlue <= alpha and alpha != -1:
return w, list_i, list_loss # 如果梯度的范数小于阈值,停止迭代
# 更新累积梯度平方
E_g = E_g * gamma + (1 - gamma) * np.square(gradient)
# 更新参数
w = w - (learning_rate / np.sqrt(E_g + epsilon)) * gradient
if abs(loss(w, batch) - loss_w) <= beta and beta != -1:
return w, list_i, list_loss # 如果损失函数值的变化小于阈值,停止迭代
return w, list_i, list_lossAdaDelta:
def AdaDelta(w, data, batch_size=-1, epochs=1000, alpha=1e-3, beta=1e-3,
epsilon=1e-6, decay_rate=0.95, loss=loss, loss_dw=loss_dw):
"""
使用AdaDelta算法优化参数w
:param w: 初始参数(w0, w1)
:param data: 样本数据
:param alpha: 梯度阈值
:param beta: 损失值变化阈值
:param epsilon: 防止除零的小常数
:param decay_rate: 梯度平方的衰减率
:param loss: 损失函数
:param loss_dw: 损失函数对w的偏导数
:return: 优化后的参数w,步数列表和损失列表
"""
k = 0
E_g = 0 # 初始化累积梯度平方
E_x = 0 # 初始化累积梯度平方
list_loss, list_i = [], [] # 用于存储损失值和步数
for _ in range(epochs):
for batch in get_batches(data, batch_size):
k += 1
gradient = loss_dw(w, batch) # 计算损失函数的梯度
gradient_modlue = np.sqrt(np.sum((np.square(gradient)))) # 计算梯度的范数
loss_w = loss(w, batch) # 计算当前损失函数值
list_loss.append(loss_w)
list_i.append(k)
print(f'Step {k:02d}: \tloss={loss_w:.18f}\tgrad={gradient_modlue:.18f}')
if gradient_modlue <= alpha and alpha != -1:
return w, list_i, list_loss # 如果梯度的范数小于阈值,停止迭代
# 累积梯度平方
E_g = E_g * decay_rate + (1 - decay_rate) * np.square(gradient)
# 计算w的RMS
RMS_w = np.sqrt(E_g + epsilon)
# 计算w的RMS更新量
RMS_x = np.sqrt(E_x + epsilon)
# 计算w的更新量x
x = RMS_x / RMS_w * gradient
# 更新w的更新量平方累积E_x
E_x = E_x * decay_rate + (1 - decay_rate) * np.square(x)
# 更新参数
w = w - x
if abs(loss(w, batch) - loss_w) <= beta and beta != -1:
return w, list_i, list_loss # 如果损失函数值的变化小于阈值,停止迭代
return w, list_i, list_loss


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









