







逻辑回归主要用于解决分类问题(二分类、多分类)。
什么是分类问题?
分类问题(Classification Problem)是机器学习中的一种常见问题类型,目的是根据输入数据的特征将数据划分为多个预定义的类别(标签)之一。简单来说,分类问题的目标是预测一个实例属于哪个类别。
分类问题的特点:
-
离散的标签:分类问题的输出是离散的类别标签,而不是连续的数值。例如,垃圾邮件分类(垃圾邮件或非垃圾邮件)或图像识别(猫、狗、鸟等类别)。
-
训练数据与标签配对:分类问题的训练数据是由样本特征(输入)和对应的类别标签(输出)组成。机器学习算法通过学习这些数据,构建一个模型,用于预测未知数据的标签。
常见的分类问题类型:
-
二分类问题(Binary Classification):当输出只有两个类别时。例如:
- 垃圾邮件分类:邮件要么是垃圾邮件(1),要么不是垃圾邮件(0)。
- 疾病预测:病人要么患病(1),要么不患病(0)。
-
多分类问题(Multiclass Classification):当输出有三个或更多类别时。例如:
- 手写数字识别:识别数字图像,类别可能是从0到9的数字。
- 图像分类:将图片分类为猫、狗、鸟等不同种类。
-
多标签分类问题(Multilabel Classification):一个实例可以属于多个类别。例如:
- 电影标签:一部电影可以同时属于“动作”、“科幻”和“冒险”。
- 新闻分类:一篇新闻文章可以同时属于“政治”、“经济”、“国际”类别。
逻辑回归是如何解决分类问题的?
以二分类为例:

看上图不难发现,y只有两个取值0和1,而非线性连续取值。遇到这种问应该如何求解呢?
step1:设y=f(x).
用一个什么样的f(x)来表示X和Y 之间的关系比较合适?换句话说f(x)应该长什么样子呢?
f(x)=w0*x0+w1*x1+…+w10*x10,线性表达式,明显不合适,
S函数(Sigmoid),取值范围:0~1,关于(0,0.5)对称并且单调递增,非常满足我们的需求。
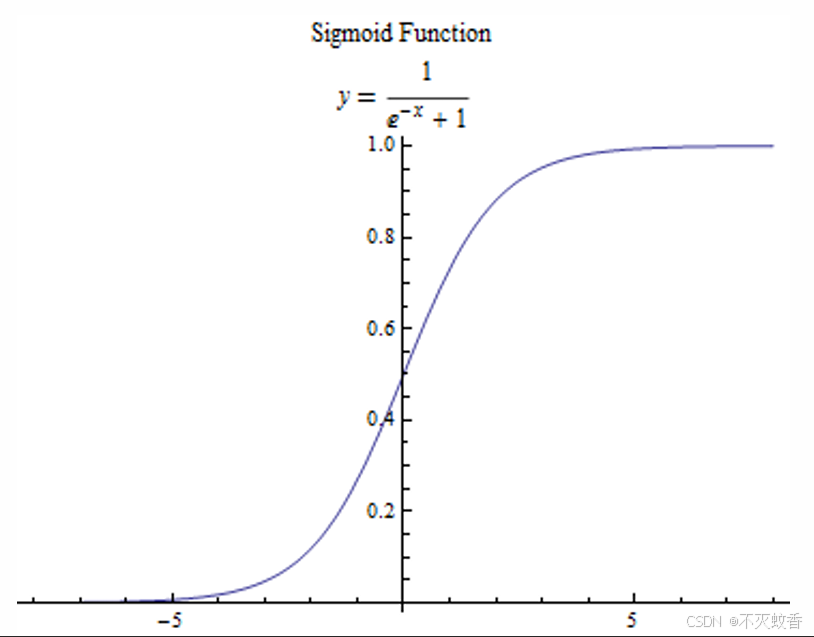
改造S函数:
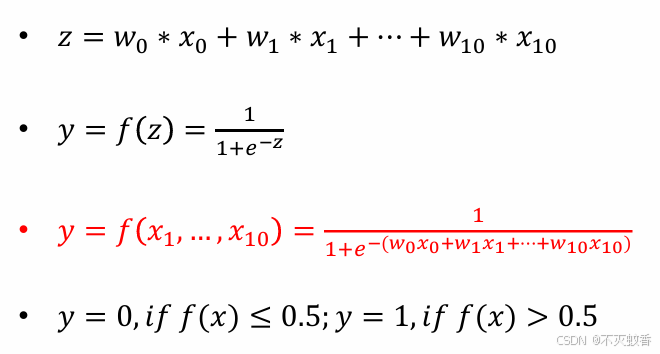
step2:构造损失函数
回归问题:均方差
分类问题:交叉熵/最大似然函数
这里为什么分类问题不用均方差?
1. 值域很小,梯度很小,不好求极值
2. S函数表示一个概率,y=1这 件事情的概率
最大似然函数是什么?


求最大的事件发生概率,推导出p=0.7,所以这个函数叫最大似然函数。
如何用最大似然函数来构造逻辑回归的损 失函数?
假设有28831个样本,都有标签0/1
做一个类比,取球事件
Y=1,表示取到白球
Y=0,表示取到黑球
白球的占比p, 类比f(x)=p(y=1)
这件事情发生的概率是:
(1−𝑓(𝑥 ))∗ (1-𝑓(𝑥)) ∗⋯∗𝑓(x)∗⋯
共有28831项相乘
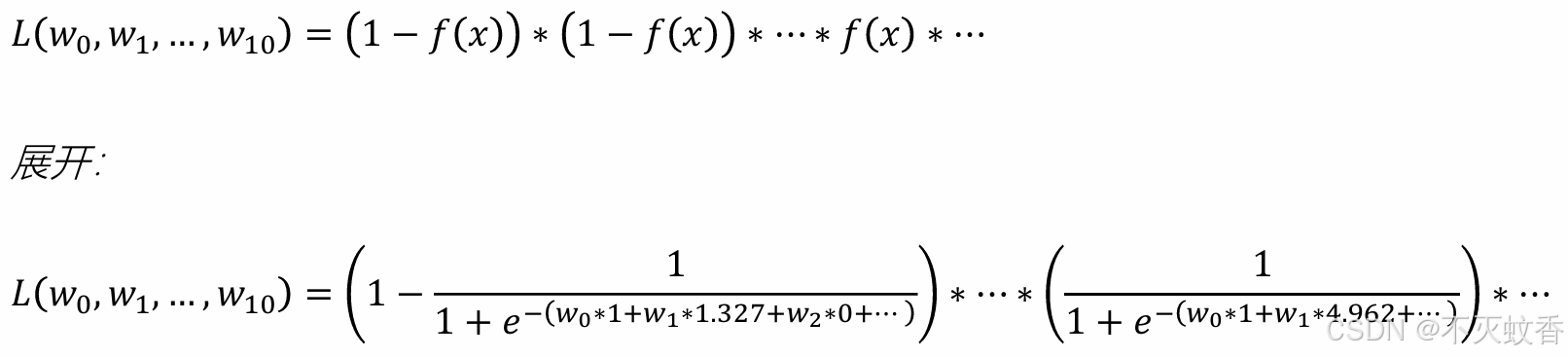
整理得到:
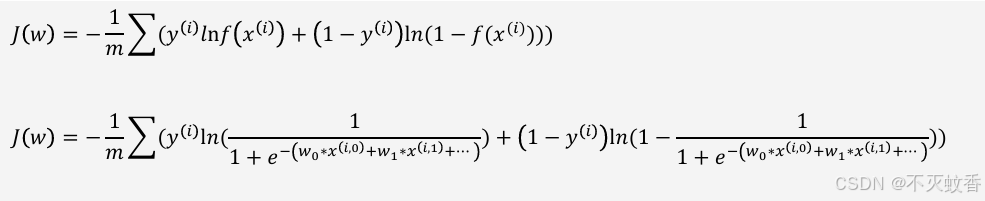
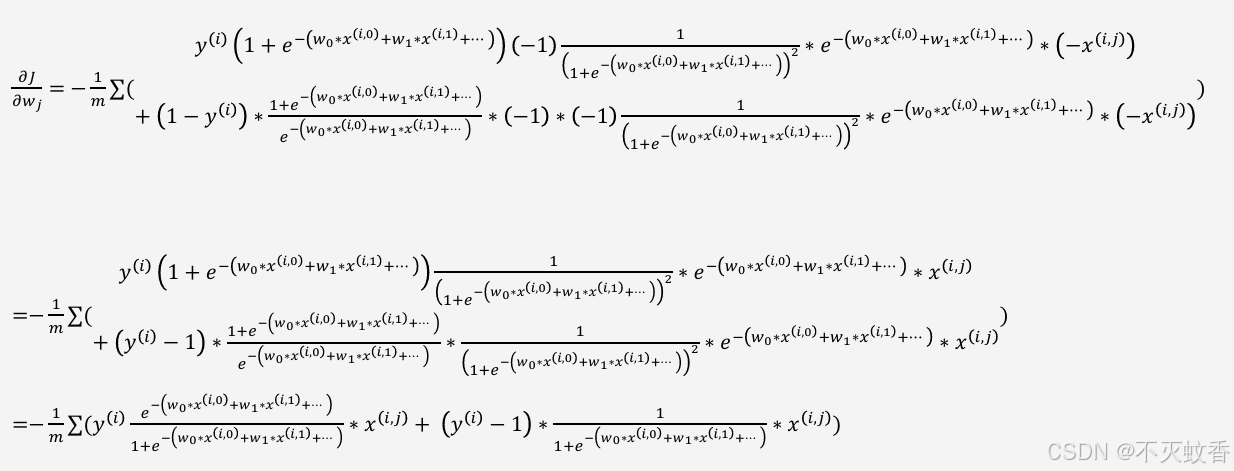

最终推理得到交叉熵公式:
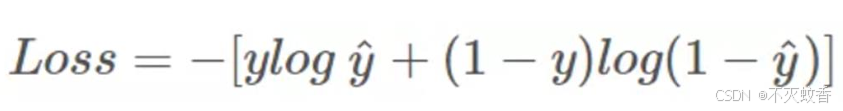
损失函数,表达预测值与真 实值之间的差距
◆相差越大,L越大
◆相差越小,L越小
step3:用梯度下降求w
这里上一章有具体将梯度下降怎么用,不明白的可以查看什么是梯度下降算法-优快云博客



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









