




KNN算法怎么来的?
1、猜猜看:最后一行未知电影属于什么类型的电影。
| 电影名称 | 打斗次数 | 接吻次数 | 电影类型 |
| California Man | 3 | 104 | Romance |
| He’s Not Really into Dudes | 2 | 100 | Romance |
| Beautiful Woman | 1 | 81 | Romance |
| Kevin Longblade | 101 | 10 | Action |
| Robo Slayer 3000 | 99 | 5 | Action |
| Amped II | 98 | 2 | Action |
| 未知 | 18 | 90 | Unknown |
2、猜猜看:最后一行未知点属于什么类型的点。
| 点 | X坐标 | Y坐标 | 点类型 |
| A点 | 3 | 104 | Romance |
| B点 | 2 | 100 | Romance |
| C点 | 1 | 81 | Romance |
| D点 | 101 | 10 | Action |
| E点 | 99 | 5 | Action |
| F点 | 98 | 2 | Action |
| G点 | 18 | 90 | Unknown |
3、想一想:下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类?

1968年,Cover和Hart提出了最初的近邻法。
最近邻算法
提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类。由此,我们引出最近邻算法的定义:为了判定未知样本的类别,以全部训练样本作为代表点,计算未知样本与所有训练样本的距离,并以最近邻者的类别作为决策未知样本类别的唯一依据。但是,最近邻算法明显是存在缺陷的,我们来看一个例子。
问题:有一个未知形状X(图中绿色的圆点),如何判断X是什么形状?
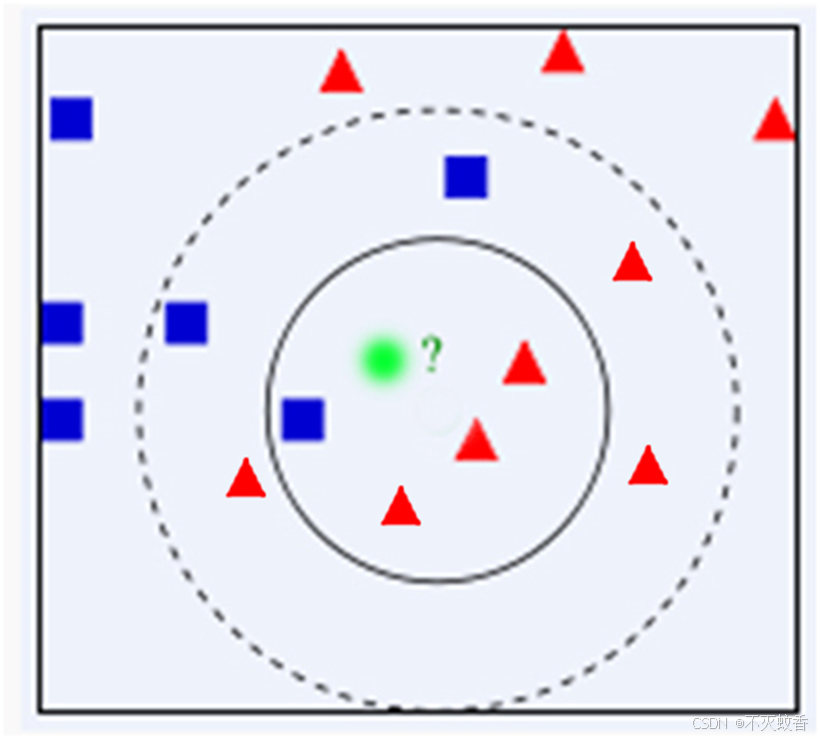
显然,通过上面的例子我们可以明显发现最近邻算法的缺陷——对噪声数据过于敏感,为了解决这个问题,我们可以可以把位置样本周边的多个最近样本计算在内,扩大参与决策的样本量,以避免个别数据直接决定决策结果。由此,我们引进K-最近邻算法。
KNN算法是用来干什么的
K-最近邻算法是最近邻算法的一个延伸。基本思路是:选择未知样本一定范围内确定个数的K个样本,该K个样本大多数属于某一类型,则未知样本判定为该类型。
下面借助图形解释一下。
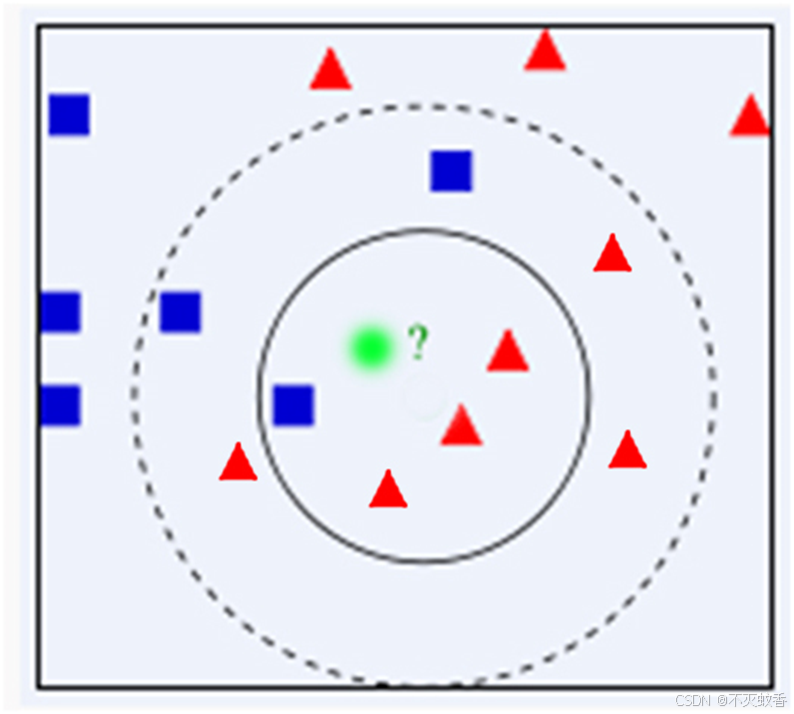
算法步骤:
step.1---初始化距离为最大值
step.2---随机选择一个训练样本,计算未知样本和该训练样本的距离dist
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近 邻样本(如果最邻近样本数小于3个,直接作为最近邻样本)
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的 距离都算完
step.6---统计K个最近邻样本中每个类别出现的次数
step.7---选择出现频率最大的类别作为未知样本的类别
KNN算法的缺陷
观察下面的例子,我们看到,对于位置样本X,通过KNN算法,我们显然可以得到X应属于红点,但对于位置样本Y,通过KNN算法我们似乎得到了Y应属于蓝点的结论,而这个结论直观来看并没有说服力。
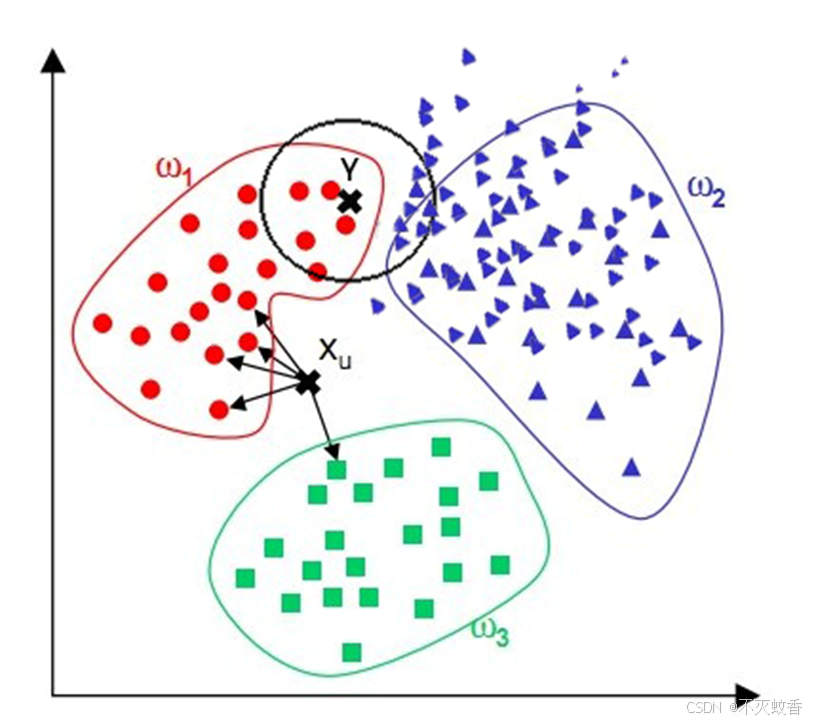
由上面的例子可见:该算法在分类时有个重要的不足是,当样本不平衡时,即:一个类的样本容量很大,而其他类样本数量很小时,很有可能导致当输入一个未知样本时,该样本的K个邻居中大数量类的样本占多数。 但是这类样本并不接近目标样本,而数量小的这类样本很靠近目标样本。这个时候,我们有理由认为该位置样本属于数量小的样本所属的一类,但是,KNN却不关心这个问题,它只关心哪类样本的数量最多,而不去把距离远近考虑在内,因此,我们可以采用权值的方法来改进。和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,由此,将距离远近的因素也考虑在内,避免因一个样本过大导致误判的情况。
KNN算法的改进:分组快速搜索近邻法
从算法实现的过程大家可以发现,该算法存两个严重的问题,第一个是需要存储全部的训练样本,第二个是需要进行繁重的距离计算量。对此,提出以下应对策略。
其基本思想是:将样本集按近邻关系分解成组,给出每组质心的位置,以质心作为代表点,和未知样本计算距离,选出距离最近的一个或若干个组,再在组的范围内应用一般的knn算法。由于并不是将未知样本与所有样本计算距离,故该改进算法可以减少计算量,但并不能减少存储量。

KNN算法的改进:压缩近邻算法
利用现在的样本集,采取一定的算法产生一个新的样本集,该样本集拥有比原样本集少的多的样本数量,但仍然保持有对未知样本进行分类的能力。
基本思路:定义两个存储器,一个用来存放生成的样本集,称为output样本集;另一个用来存放原来的样本集,称为original样本集。
1.初始化:output样本集为空集,原样本集存入original样本集,从original样本集中任意选择一个样本移动到output样本集中;
2.在original样本集中选择第i个样本,并使用output样本集中的样本对其进行最近邻算法分类,若分类错误,则将该样本移动到output样本集中,若分类正确,不做任何处理;
3.重复2步骤,直至遍历完original样本集中的所有样本,output样本集即为压缩后的样本集。
数据归一化
防止某一维度的数据的数值大小对距离就算产生影响。多个维度的特征是等权重的,所以不能被数值大小影响。

几种距离算法汇总:
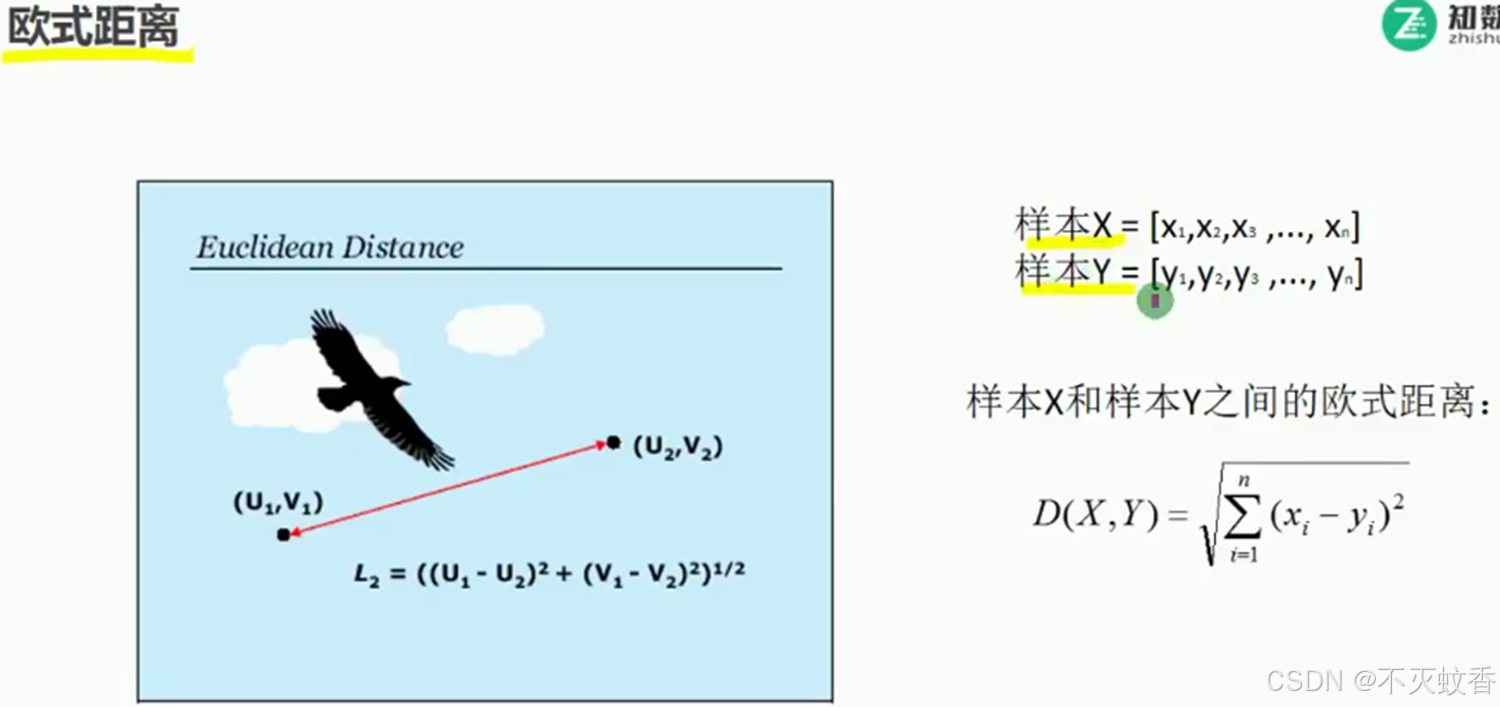
欧式距离:
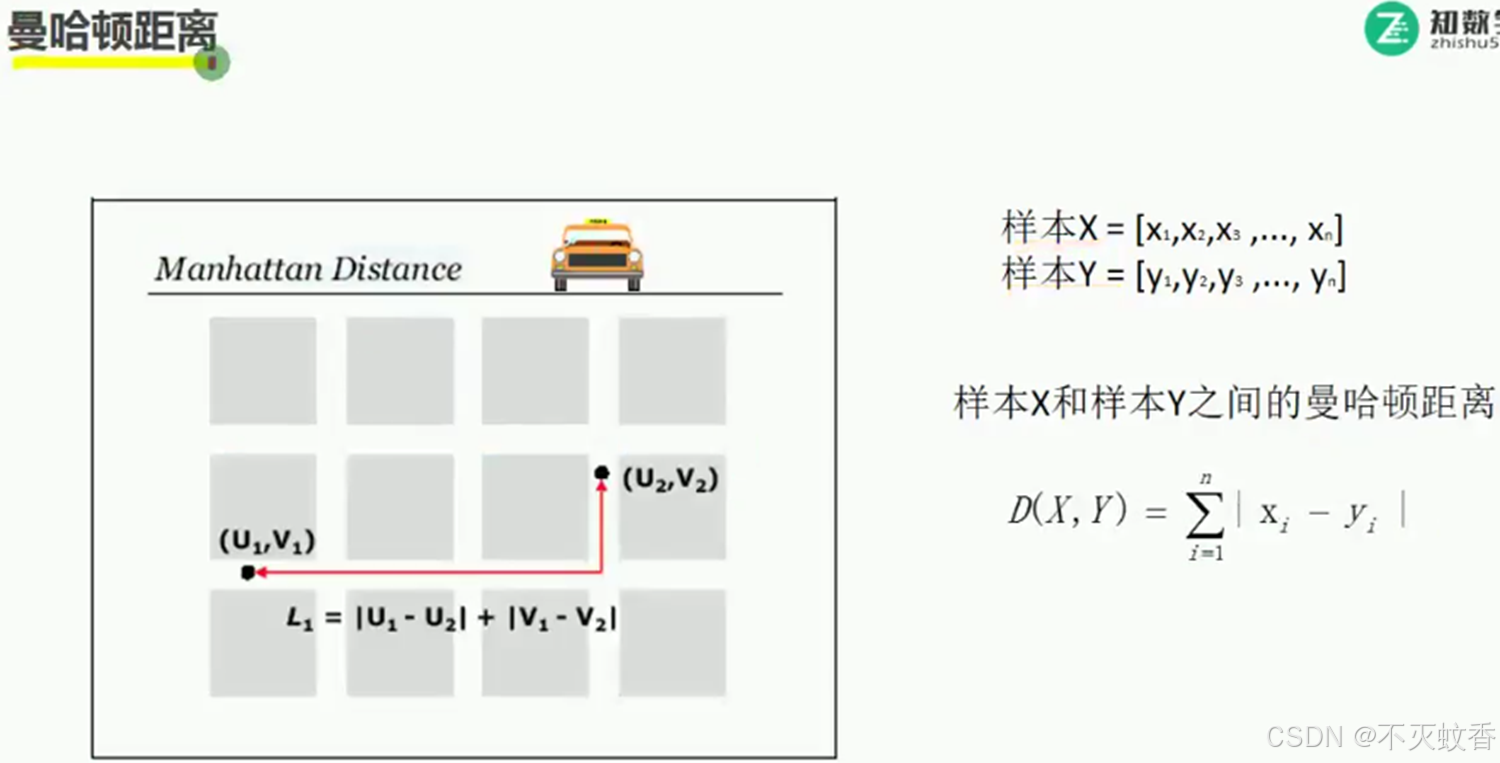
曼哈顿距离:
闵氏距离:

KNN优缺点总结
优点:
思想简单,易于理解,易于实现,无需估计参数,无需训练
适合对稀有类别进行分类
特别适合于多分类问题
缺点:
懒惰算法,进行分类时计算量大,要扫描全部训练样本计算距离,内存开销大,评分慢
可解释性较差,无法给出可理解的业务规则(类似决策树)
选择k需要一些trick(小技巧)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









