






信道编码-Hamming编码【附MATLAB完整代码】
信道编码又称差错控制编码、可靠性编码、抗干扰编码或纠错码,它是提高数字信号传输可靠性的有效方法之一。它产生于20世纪50年代初,发展到20世纪70年代趋向成熟。
1 概述
数字信号在传输过程中,加性噪声、码间串扰等都可能引起误码。为了提高系统的抗干扰性能,可以加大发送功率,降低接收设备本身的噪声,以及合理选择调制、解调方法等。此外,还可以采用信道编码技术。信道编码是为了降低误码率,提高数字通信的可靠性而采取的编码,它按一定的规则人为引入冗余度。具体地讲,信道编码就是在发送端的信息码元序列中,以某种确定的编码规则,加入监督码元,在接收端再利用该规则进行检查识别,从而发现错误、纠正错误。
能发现错误的编码叫检错码;能纠正错误的编码叫纠错码。一般说来,纠错码一定能检错;反之,检错码不一定能纠错;或者说,同一个码,检错能力比纠错能力强。
1.1 差错控制方式
在数字通信系统中,利用纠错码或检错码进行差错控制的方式有三种:检错重发、前向纠错和混合纠错,它们的系统构成如图1所示,图中有斜线的方框图表示在该端检出错误。
1 检错控制方式
检错重发又称自动请求重传方式,记作ARQ(Automatic Repeat Request)。发送端发出能够发现(检测)错误的码,接收端收到通过信道传来的码后,在译码器根据该码的编码规则,判决收到的码序列中有无错误产生,如果发现错误,则通过反向信道把这一判决结果反馈给发端。
2 前向纠错方式
前向纠错方式记作FEC(Forword Eror Correction)。发送端发送能够被纠错的码,接收端收到这些码后,通过纠错译码器不仅能够自动地发现错误,而且能自动地纠正接收码字传输中的错误。这种方式的优点是不需要反馈信道,能进行一个用户对多个用户的同播通信,译码实时性较好。其缺点是译码设备比较复杂,所选用的纠错码必须与信道的干扰情况相匹配,因此,对信道的适应性较差。在移动通信系统中,几乎都采用前向纠错的差错控制方式。
3 混合纠错码
混合纠错方式记作HEC(Hybrid Eror Corection)是FEC和ARQ方式的结合,这种方式是发送端发送的码不仅能够被检测出错误,而且还具有一定的纠错能力。接收端收到码后,首先检查差错情况,如果在纠错码的纠错能力范围以内,则自动纠错,如果错误过多,超过了码的纠错能力,但能检测出来,则接收端通过反馈信道,要求发送端重新传送有错的消息。这种方式具有自动纠错和检错重发的优点,并可达到较低的误码率。因此,在实际中的应用越来越广。
1.2 纠错码的分类
按照不同的分类方法,纠错码可以分为线性码与非线性码、分组码与卷积码、检错码和纠错码等。本文重点介绍线性分组码中的Hamming码。
根据纠错码各码组信息和监督元的函数关系,可分为线性码和非线性码。如果函数关系是线性的,即满足一组线性方程式,则称为线性码,否则为非线性码。线性码集合中的所有码字在加法和乘法运算时是封闭的,而非线性码则不封闭。换言之,线性码实际上就是 n n n 维线性空间的一个 k ( k < n ) k(k<n) k(k<n) 维子空间。目前大量使用的均为线性码。
1.3 编码效率
采用差错控制编码提高了通信系统的可靠性,但是以降低有效性为代价换来的。通常定义编码效率
R
R
R 来衡量有效性,即:
R
=
k
/
n
(1)
R=k/n \tag{1}
R=k/n(1)
式中,
k
k
k 为一个码组中信息元的个数,
n
n
n 为码长。
对纠错码的基本要求是:检错和纠错能力尽量强;编码效率尽量高;编码规律尽量简单。实际中要根据具体指标要求,保证有一定纠、检错能力和编码效率,并且易于实现。
2 线性分组码
在 ( n , k ) (n,k) (n,k)分组码中,若每一个监督元都是码组中某些信息元按模2和得到的,即监督元是信息元按线性关系相加而得到的,则称为线性分组码。或者说,可用线性方程组表述码规律性的分组码称为线性分组码。线性分组码是一类重要的纠错码,应用很广泛,其中Hamming 码、循环码、BCH 码和 RS 码都可以看作线性分组码的特例。
2.1 Hamming码
MATLAB提供了生成Hammming码的函数hammgen,以及用Hamming码进行编码,解码的encode和decode函数。
h=hammgen(m);
h=hammgen(m)产生一个 m × n m \times n m×n的 Hamming 校验矩阵 h,其中, n = 2 m − 1 n=2^{m}-1 n=2m−1。需要注意的是,产生的校验矩阵h=[I P]的形式,其中,I是 m × n m \times n m×n的单位矩阵。
[h,g]=hammgen(m)
[h,g]=hammgen(m)产生一个 m × n m\times n m×n的 Hamming 校验矩阵h和与h相对应的生成矩阵。其中, n = 2 m − 1 n=2^{m}-1 n=2m−1。h=[I P],I是 m × m m\times m m×m的单位矩阵。而g=[P I],其中,I是 ( n − m ) × ( n − m ) (n-m)\times(n-m) (n−m)×(n−m)单位矩阵,这与前面讨论的生成的矩阵形式不同。
code = encode(msg,n,k,'type/fmt’)或 code = encode(msg,n,k)
code =encode(msg,n,k,‘type/fmt’)可以进行一般的线性分组编码、循环编码和 Hammimng多码。所选用的编码方式由type指定。它的值可以是linear、cyclic或hamming,分别对应上面提到的3种编码方式,fmt参数取值可以是binary或decimal,分别用来说明输入待编码数是二进制还是十进制。当使用 code=encode(msg,n,k)时,默认的是使用 Hamming 编码。
msg = decode(code,n,k,'type/fmt')
msg = decode(code,n,k,'ype/fmt)用来对编码数据进行译码,其type/fmt 的取值与encod 函数的 type/fmt 的取值相对应。当使用 msg=decode(code,n,k)时,默认的是对 Hamming编进行译码。
2.2 仿真示例
例:仿真未编码和进行(7,4)Hamming编码的QPSK调制通过AWGN信道后的误比特率性能。
clear;clc;clf;
N=100000; %信息比特行数
M=4; %QPSK调制
n=7; %Hamming编码码组长度
m=3; %Hamming码监督位长度
graycode=[0 1 3 2];
msg=randi([0 1],N,n-m); %信息比特
msg1=reshape(msg.',log2(M),N*(n-m)/log2(M)).';
msg1_de=bi2de(msg1,'left-msb'); %信息比特转换为10进制形式
msg1=graycode(msg1_de+1); %Gray编码
msg1=pskmod(msg1,M); %QPSK调制
Eb1=norm(msg1).^2/(N*(n-m)); %计算比特能量
msg2=encode(msg,n,n-m); %Hamming编码
msg2=reshape(msg2.',log2(M),N*n/log2(M)).';
msg2=bi2de(msg2,'left-msb');
msg2=graycode(msg2+1); %Hamming编码后的比特序列转换为10进制形式
msg2=pskmod(msg2,M); %Hamming编码数据进行QPSK调制
Eb2=norm(msg2).^2/(N*(n-m)); %计算比特能量
EbNo=0:2:10; %信噪比
EbNo_lin=10.^(EbNo/10); %信噪比的线性值
for indx=1:length(EbNo_lin)
indx;
sigma1=sqrt(Eb1/(2*EbNo_lin(indx))); %未编码的噪声标准差
rx1=msg1+sigma1*(randn(1,length(msg1))+1i*randn(1,length(msg1))); %加入高斯白噪声
y1=pskdemod(rx1,M); %未编码QPSK解调
y1_de=graycode(y1+1); %未编码的Gray逆映射
[err, ber1(indx)]=biterr(msg1_de.',y1_de,log2(M)); %未编码的误比特率
sigma2=sqrt(Eb2/(2*EbNo_lin(indx))); %编码的噪声标准差
rx2=msg2+sigma2*(randn(1,length(msg2))+1i*randn(1,length(msg2))); %加入高斯白噪声
y2=pskdemod(rx2,M); %编码QPSK解调
y2=graycode(y2+1); %编码Gray逆映射
y2=de2bi(y2,'left-msb'); %转换为二进制形式
y2=reshape(y2.',n,N).';
y2=decode(y2,n,n-m); %译码
[err, ber2(indx)]=biterr(msg,y2); %编码的误比特率
end
semilogy(EbNo,ber1,'-ko',EbNo,ber2,'-k*');
legend('未编码','Hamming(7,4)编码');
title('未编码和Hamming(7,4)编码的QPSK在AWGN下的性能');
xlabel('Eb/No');ylabel('误比特率');
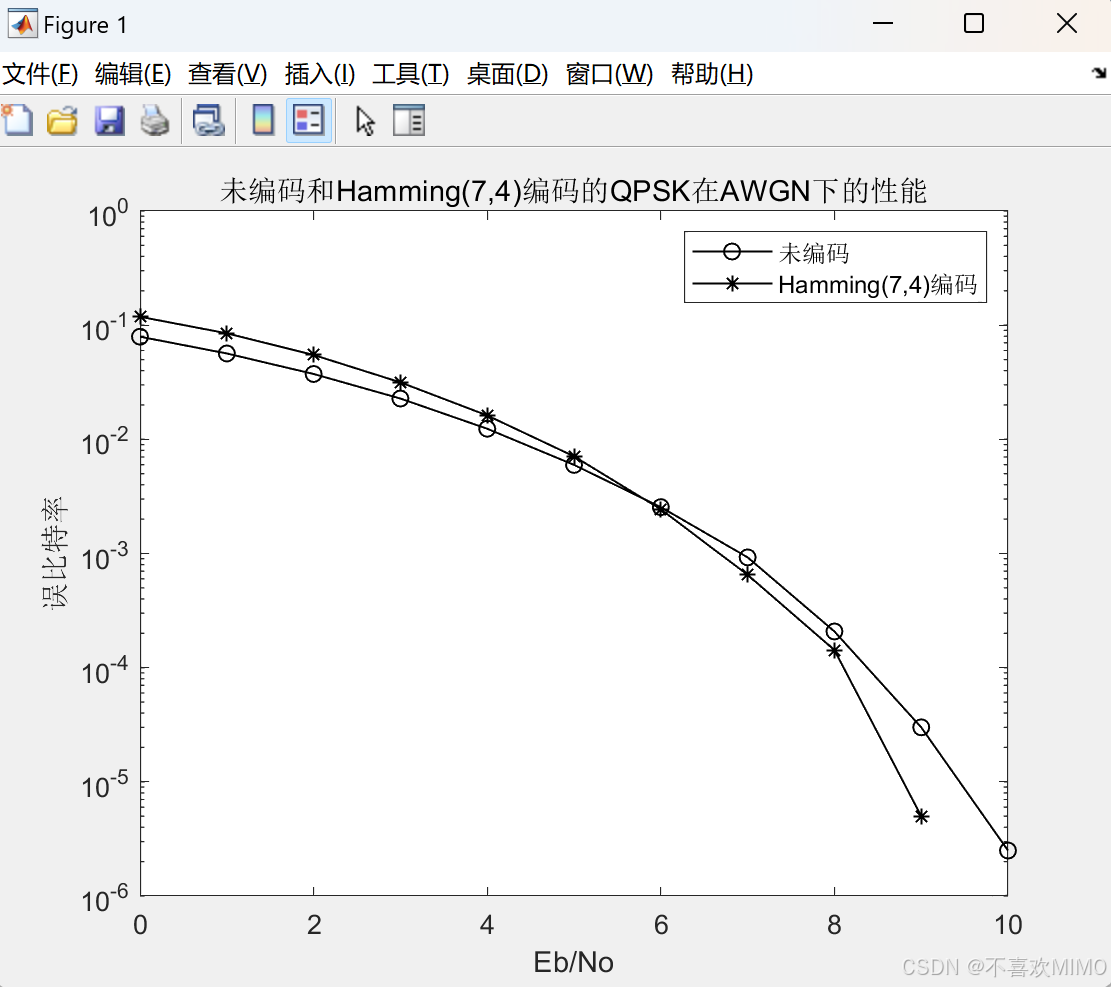
从仿真结果可以看出,在信噪比较低时(
E
b
/
N
0
E_{b}/N_{0}
Eb/N0<6dB),不编码的误比特率要好于编码的误比特率,这是因为编码虽然可以带来编码增益,但在传输总能量不变的情况下,由于传每个编码码字中的比特能量减少,信噪比降低,由于信噪比降低而使误码率升高,而此时码增益很小,因此,编码结果反而不如不编码的结果。而在信噪比较高时,编码增益要大信噪比降低而导致的性能损失,因此,在(
E
b
/
N
0
E_{b}/N_{0}
Eb/N0>6dB)时,编码结果要优于不编码的结果。


















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









