 RAG技术:检索增强生成模型解析
RAG技术:检索增强生成模型解析




RAG
什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术和 AI 内容生成的混合架构,可以解决大模型的知识时效性限制和幻觉问题。
传统大语言模型的生成依赖于训练时 “记住” 的知识,但存在两个明显问题:一是知识可能过时(比如训练数据截止到 2024 年,无法回答 2025 年的新事件);二是可能 “编造” 事实(即 “幻觉”,比如虚构不存在的文献、数据)。
而 RAG 的思路是:在生成回答前,先 “检索” 外部可靠的知识库(比如企业文档、学术论文、实时新闻等),把检索到的相关事实性信息 “喂” 给模型,再让模型基于这些真实信息生成回答。相当于给模型加了一个 “实时查资料” 的能力,既不用重新训练模型,又能让回答锚定在真实数据上。
RAG的工作流程
主要包含四个核心步骤,前两个步骤主要是用于将相关的知识库转换成向量存储,为后续的检索增强提供基础。
- 文档收集与切割
- 向量转换与存储
- 文档检索
- 提示词构建与生成
1、文档收集与切割

文档收集:从网页、数据库等多种数据源来收集原始数据
文档预处理:清洗原始文档、进行标准化
文档切割:将文档切分成合适的片段(基于语义分割、固定大小)
2、向量转换和存储
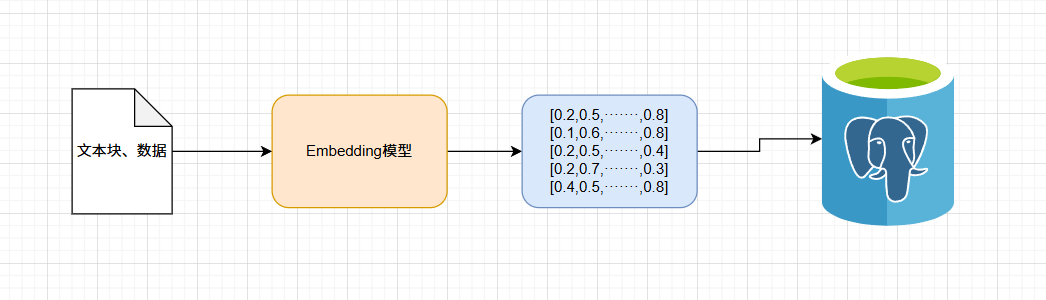
向量转换:将文本块通过Embedding模型转换成向量
向量存储:通过向量数据库进行存储,方便后续进行相似度计算匹配
3、文档检索
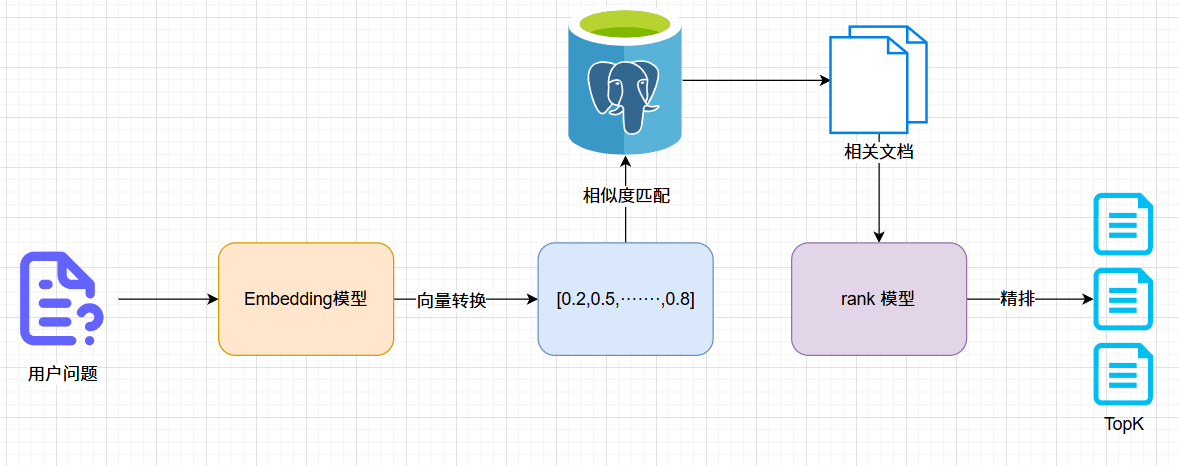
向量转换:将用户问题转换成向量表示
相似度匹配:根据相似度匹配算法(余弦相似度、欧式距离等)在向量数据库中搜索出相关文档
精排:通过rank模型得出最符合的TopK个相关文档
4、提示词构建与生成
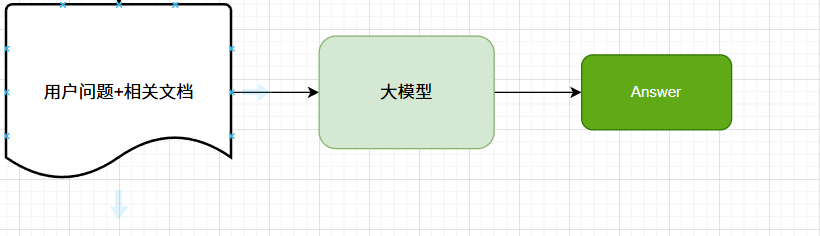
提示词组装:将用户问题与向量数据库中检索的文档进行组合成增强提示词
输入到大模型:大模型根据增强后的提示词生成最终的回答
完整流程
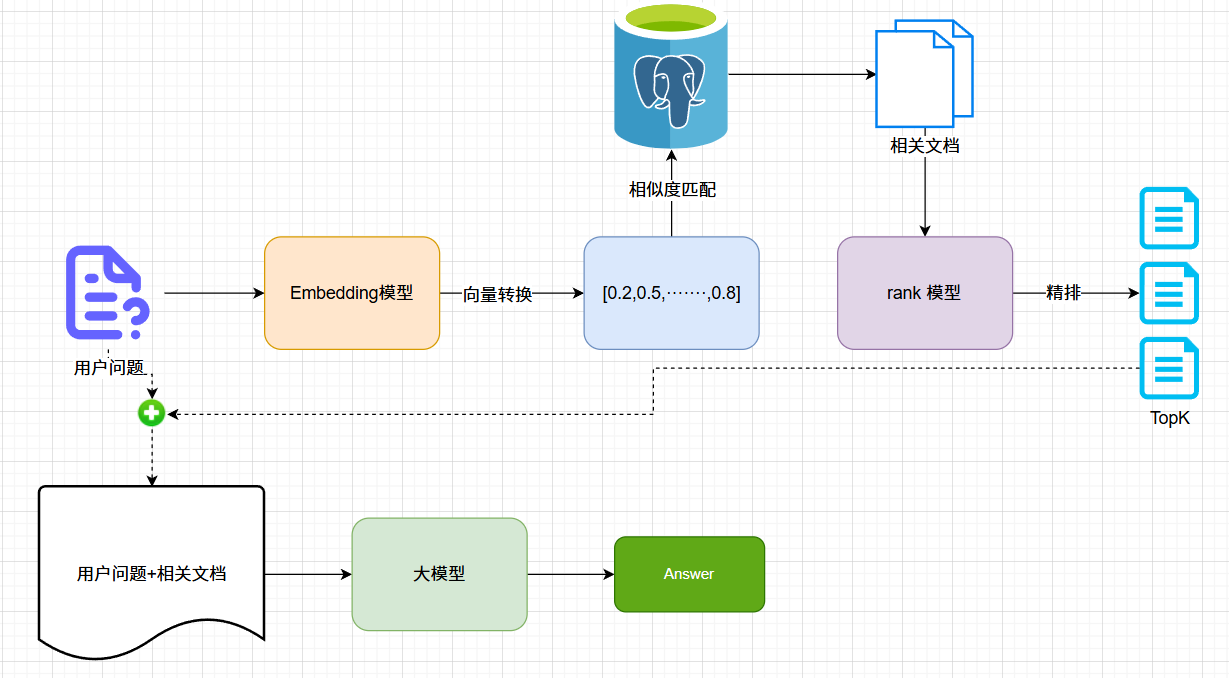
RAG相关技术
1、Embedding技术
技术核心:通过预训练模型将文本(文本块、用户问题、关键词等)映射为高维向量,使 “语义相似的文本” 对应 “向量距离更近”(如余弦相似度更高),为后续检索提供 “可计算的语义特征”。
关键技术细节:
- 向量的 “语义颗粒度” 控制:Embedding 模型的输出向量需匹配检索需求 —— 若需 “细粒度匹配”(如区分 “RAG 的检索步骤” 和 “RAG 的生成步骤”),需选 “语义分辨力强” 的模型(如 BGE-large、text-embedding-ada-002);若仅需 “粗粒度召回”(如筛选 “RAG 相关文档”),轻量模型(如 M3E-base、Sentence-BERT)即可满足,且推理速度更快。
- 长文本 Embedding 的适配:常规模型对长文本(如超过 512token)处理有限(会截断或语义失真),需结合 “分段嵌入 + 融合” 策略:
- 先将长文本切分成子块(如每 200token 一块),分别生成向量;
- 再通过 “加权融合”(如按子块与核心语义的关联度赋权)或 “摘要嵌入”(先让模型生成文本摘要,再对摘要 Embedding),得到整个长文本的向量(避免因截断丢失关键信息)。
- 领域适配优化:通用 Embedding 模型在垂直领域(如医疗、法律)可能 “语义偏移”(如 “剂量” 在医疗中是 “用药量”,通用模型可能仅理解为 “数量”),需通过 “领域数据微调” 优化:用领域内标注数据(如医疗文本对)微调模型参数,让向量更贴合领域语义。
2、混合检索技术
技术核心:通过 “向量检索(抓语义关联)” 与 “关键词检索(抓字面匹配)” 的协同,弥补单一检索的缺陷 —— 向量检索可能漏检 “关键词明确但语义表述特殊” 的内容(如用户问 “RAG 的 Chunking 步骤”,向量模型若未强化 “Chunking” 一词,可能漏检含该词的文档);关键词检索则无法处理 “同义不同词”(如用户问 “文本分块方法”,关键词检索若仅搜 “分块”,可能漏检含 “Chunking” 的文档)。
核心实现方式:
- “关键词召回 + 向量精排” 两步法(常用)
- 先用关键词检索(基于 Elasticsearch等传统搜索引擎):通过 “倒排索引” 快速召回含 “用户问题核心词” 的文本块(如用户问 “2025 年 AI 政策”,核心词 “2025”“AI 政策”,召回所有含这些词的块);
- 再对召回的文本块做向量检索:用 Embedding 模型计算这些块与用户问题的向量相似度,按相似度排序,保留 Top3-5 个最相关的块(过滤掉 “仅含关键词但语义无关” 的块,如含 “2025”“AI” 但讲 “AI 产品” 的文档)。
3、多轮检索技术
触发逻辑:当首轮检索结果无法满足 “回答需求” 时自动触发,核心是通过 “动态调整检索策略” 填补信息缺口,常见触发条件包括:
- 检索召回率低(如向量检索仅召回 1 个相关块,或关键词检索无结果);
- 检索结果 “信息碎片化”(如多个块各含部分信息,但未形成完整逻辑);
- 生成的回答 “模糊 / 存疑”(如模型判断 “基于现有信息无法明确回答”,反馈 “信息不足”)。
策略:
- Query 改写与优化:用大模型对用户原始问题 “二次加工”,生成更精准的检索词。例如:
原始问题:“RAG 最近有什么新应用?”→ 首轮检索结果多为 2023 年案例→ 改写后检索词:“2024-2025 年 RAG 在企业 / 医疗 / 教育领域的应用案例”(补充时间范围、领域,缩小检索范围);
原始问题:“如何解决 RAG 的检索漏检?”→ 改写后检索词:“RAG 检索漏检原因及解决方案、RAG 混合检索 / 重排序优化方法”(拆分问题为核心子主题,扩大检索维度)。 - 检索范围动态调整:若首轮在 “内部文档库” 检索无果,自动扩展至 “外部公开库”(如学术论文库、行业报告库);若检索结果冗余(如含大量重复信息),则缩小范围(如限定 “近 6 个月文档”“权威来源文档”)。
- 结合上下文的多轮联动:若用户有 “追问行为”,检索时关联历史对话。例如:
用户首轮问:“RAG 需要向量数据库吗?”→ 回答后用户追问:“那用什么向量数据库好?”→ 检索时自动关联 “RAG 场景”,优先召回 “RAG 适配的向量数据库对比”“中小规模 RAG 的向量数据库选型” 等内容。
4、知识增量更新技术
技术目标:在不重建整个知识库的前提下,高效纳入新文档、更新旧内容,同时避免 “旧数据冗余”“新数据检索延迟” 等问题(若每次更新都重新分块、Embedding、建索引,会导致系统卡顿,尤其在百万级文档场景)。
核心实现方案:
- 文档级增量更新:对新增文档单独处理,不影响存量数据:
- 为新增文档打 “时间戳标签”(如 “2025-08-28 新增”),按常规流程分块、Embedding;
- 直接将新文本块的向量 “追加写入” 向量数据库(如 Milvus 支持 “分区写入”,新增数据写入独立分区,不影响存量分区检索);
- 若需删除旧文档,通过 “标签过滤” 批量删除(如删除 “2023 年前文档”),无需遍历整个数据库。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









