







目录
三、重点剪枝方法:Channel Pruning, ThiNet, Network Slimming

前言
深度学习模型就像一位“知识渊博”的大块头,能力强但占空间、跑得慢。在资源有限的设备(如手机、嵌入式系统)上部署时,模型的庞大参数量和高计算复杂度是个大问题。模型剪枝(Pruning)就像给模型“修枝剪叶”,去掉不重要的部分,减少参数和计算量,让模型更轻巧、运行更快,同时尽量保持性能。本文将深入浅出地介绍模型剪枝的两种主要方式:非结构化剪枝和结构化剪枝,重点讲解Channel Pruning、ThiNet和Network Slimming,并通过表格和可视化示例帮你快速理解。
一、为什么需要模型剪枝?
深度学习模型(像ResNet、BERT)动辄数百万参数,导致以下问题:
-
存储占用大:模型文件大,边缘设备存不下。
-
计算复杂度高:推理慢,耗电多。
-
部署困难:在手机、物联网设备上运行卡顿。
剪枝通过移除模型中对性能贡献小的部分(如权重、通道或层),大幅降低模型体积和计算量。就像修剪一棵大树,去掉多余枝叶,树更轻盈但仍能开花结果。
为什么需要模型剪枝?
深度学习模型(像ResNet、BERT)动辄数百万参数,导致以下问题:
-
存储占用大:模型文件大,边缘设备存不下。
-
计算复杂度高:推理慢,耗电多。
-
部署困难:在手机、物联网设备上运行卡顿。
剪枝通过移除模型中对性能贡献小的部分(如权重、通道或层),大幅降低模型体积和计算量。就像修剪一棵大树,去掉多余枝叶,树更轻盈但仍能开花结果。
二、剪枝的两种方式:非结构化 vs 结构化
剪枝主要分为非结构化剪枝和结构化剪枝,各有特点和适用场景。以下是详细对比:
| 剪枝类型 | 粒度 | 优点 | 缺点 | 硬件支持 | 典型方法 |
|---|---|---|---|---|---|
| 非结构化剪枝 | 连接级(细粒度) | 精度高,压缩率高 | 需要专用硬件/算法库支持 | 专用硬件 | Deep Compression |
| 结构化剪枝 | 通道/层级(粗粒度) | 硬件友好,通用框架支持 | 精度可能略低 | 通用硬件(如GPU) | Channel Pruning, Network Slimming |
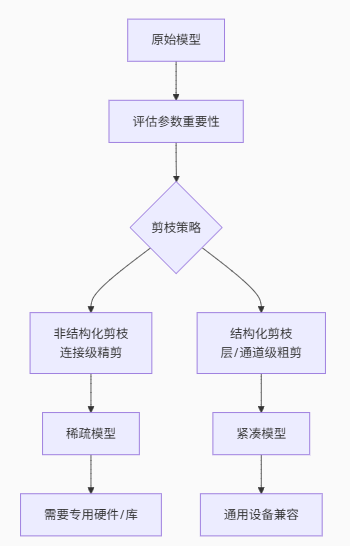
2.1 非结构化剪枝:细致但挑硬件
非结构化剪枝像用小剪刀一点点修剪树叶,针对单个权重(连接级)进行裁剪,生成稀疏矩阵。
-
怎么做? 将权重值低于某个阈值的连接设为0(如Deep Compression方法),减少参数量。
-
优点:
-
压缩率高,可减少50倍以上参数。
-
精度损失小,适合高精度场景。
-
-
缺点:
-
稀疏矩阵运算需要专用硬件(如NVIDIA的Sparse Tensor Core)或算法库支持。
-
通用硬件(CPU/GPU)加速效果有限。
-
-
场景:对精度要求高、硬件支持稀疏运算的场景,如服务器端推理。
可视化示例:
假设一个全连接层有100个权重,非结构化剪枝可能将其中60个权重设为0,生成稀疏矩阵:
原始权重矩阵:
[0.5, -0.2, 0.8, 0.1, ...]
剪枝后(阈值0.3):
[0.5, 0, 0.8, 0, ...] 2.2 结构化剪枝:粗犷但硬件友好
结构化剪枝像用大剪刀直接砍掉整根树枝,移除整个通道(Filter)或层,保持模型结构规整。
-
怎么做? 识别对模型输出贡献小的通道或层,直接移除(如Channel Pruning)。
-
优点:
-
硬件友好,兼容现有深度学习框架(如PyTorch、TensorFlow)。
-
加速明显,适合通用硬件(CPU/GPU)。
-
-
缺点:
-
精度可能比非结构化剪枝略低。
-
需要重新训练或微调以恢复性能。
-
-
场景:边缘设备、移动端推理,如手机、自动驾驶系统。
可视化示例:
一个卷积层有10个Filter,结构化剪枝移除3个贡献小的Filter:
原始卷积层:10个Filter → 输出10个特征图
剪枝后:7个Filter → 输出7个特征图 三、重点剪枝方法:Channel Pruning, ThiNet, Network Slimming
3.1 Channel Pruning:逐层最小化重建误差
✅ 原理
在每一层中选取冗余的通道(feature maps)进行裁剪,保持层的结构不变
通常使用输出特征图(feature map)重建误差最小化作为优化目标
📘 代表方法:
ThiNet:基于输出重建损失函数,逐层优化剪枝通道集合
Discrimination-aware Pruning:考虑通道对分类判别能力的重要性
📈 图示建议:

Channel Pruning是一种局部结构化剪枝方法,通过逐层(Layer-by-Layer)分析,移除对输出特征图(Feature Map, FM)贡献小的通道,目标是最小化重建误差。
-
怎么做?
-
评估每个通道对输出的重要性(通常通过特征图的重建误差)。
-
移除贡献最小的通道,保留重要结构。
-
微调模型以恢复精度。
-
-
优点:
-
局部优化,计算效率高。
-
硬件友好,推理加速明显。
-
-
场景:实时推理场景,如自动驾驶、视频监控。
可视化:
假设一个卷积层有4个通道,Channel Pruning分析发现通道2贡献最小:
输入 → [通道1, 通道2, 通道3, 通道4] → 输出特征图
剪枝后:输入 → [通道1, 通道3, 通道4] → 输出特征图 3.2 ThiNet:判别性通道剪枝
**ThiNet(Discrimination-aware Channel Pruning)**是Channel Pruning的改进版,强调通道的“判别性”,即对分类任务的贡献。
-
怎么做?
-
通过分析通道对分类结果的影响,优先保留高判别性的通道。
-
基于贪心算法或优化方法选择要剪的通道。
-
微调确保性能稳定。
-
-
优点:
-
更关注任务性能,精度损失小。
-
适合分类任务(如图像分类)。
-
-
场景:高精度要求的边缘设备,如手机图像识别。
3.3 Network Slimming:全局正则化剪枝
✅ 原理
利用 BatchNorm 中的缩放因子 γ(Gamma) 作为通道重要性指标
在训练阶段对 γ 施加 L1 正则,促使不重要通道 γ 变为 0
剪掉 γ 近零的通道,实现结构剪枝
📘 优点:
全局可控性强,不依赖具体任务损失函数
一次性剪完再微调,简洁高效
🧠 图示建议:
训练时 Loss = 原始Loss + λ × ||BN_Gamma||₁ 剪掉 γ ≈ 0 的通道
Network Slimming是一种全局结构化剪枝方法,通过在训练期间对BN层(Batch Normalization)的Gamma系数施加L1正则约束,自动识别不重要的通道。
-
怎么做?
-
在训练时,对BN层的Gamma系数加L1正则,鼓励部分系数趋于0。
-
剪掉Gamma系数接近0的通道,生成更“瘦”的网络。
-
微调恢复精度。
-
-
优点:
-
全局优化,整体压缩效果好。
-
自动化程度高,剪枝策略简单。
-
-
缺点:需要额外正则化训练,计算成本稍高。
-
场景:通用模型压缩,如ResNet在移动端部署。
可视化:
BN层Gamma系数:
原始:[1.2, 0.01, 0.8, 0.05, ...]
剪枝后(阈值0.1):保留[1.2, 0.8, ...]对应通道 四、剪枝过程全流程图解(可视化推荐)
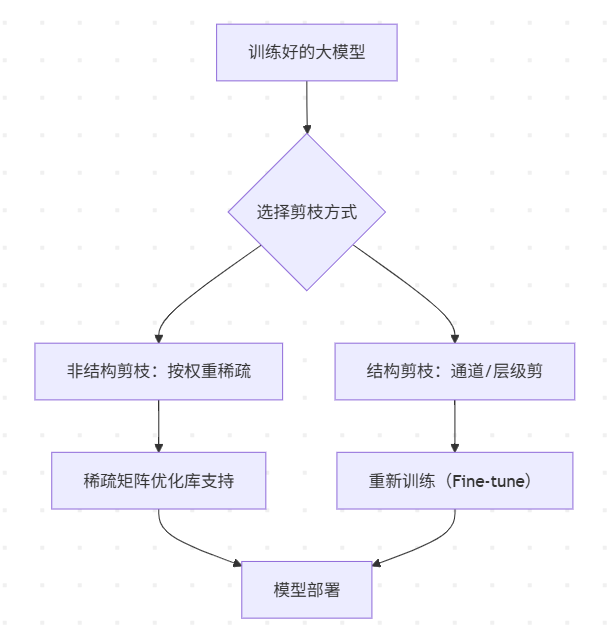
五、剪枝策略实践建议
✅ 是否剪枝?
-
建议在目标设备资源受限或模型体积/速度是瓶颈时采用剪枝
✅ 剪多少?
-
剪枝率(Pruning Ratio)需要平衡精度与加速目标,建议从小比例剪起(如 20-30%)
✅ 剪后是否再训?
-
必须!Fine-tuning 是恢复模型性能的关键步骤
✅ 与其他压缩方法结合?
-
剪枝 + 量化 + 蒸馏常常联合使用,效果最佳
六、为什么很少企业用剪枝?
尽管剪枝(Pruning)在学术界被广泛研究,也取得了显著成果,但在工业界/企业落地应用中确实使用得较少或较为谨慎。下面我们从多个维度分析这个现象:
6.1 剪枝后模型加速不明显
-
非结构化剪枝虽然参数量减少很多,但生成的稀疏矩阵对主流硬件(如 CPU/GPU)不友好,不容易实现真正的加速。
-
结构化剪枝虽然更硬件友好,但剪掉通道或层容易破坏模型性能,尤其是在大模型或复杂任务上,得不偿失。
🔍 举例:你剪掉了50%的参数,但推理速度也许只快了10%不到,甚至还可能变慢(稀疏运算低效)。
6.2 剪枝流程复杂,调参成本高
-
剪枝涉及多个阶段:剪枝策略设计 → 剪枝训练 → 精度评估 → 微调恢复 → 工程部署
-
很多方法(如 ThiNet、Network Slimming)需要逐层手动设置超参、剪枝率、Fine-tune 步骤,工程成本高、不稳定,且缺乏标准工具链支持
🧠 对比:量化(尤其是 int8)和蒸馏已经有成熟的工具,如 TensorRT、ONNX、PyTorch Quantization 等,剪枝工具则不够成熟;
6.3 剪枝不如直接用“轻量模型”
-
实际上,很多公司在推理部署上更倾向于直接选用轻量级模型,比如:
-
图像任务:MobileNetV3、EfficientNet、YOLO-Nano 等
-
NLP 任务:DistilBERT、TinyBERT、Qwen-Tiny 等
-
✅ 优势:这些模型结构天然为轻量设计,不需要后期剪枝,精度与效率已做了良好权衡。
6.4 剪枝易破坏模型鲁棒性
工业界对模型的稳定性要求极高,尤其在医疗、金融、自动驾驶等领域,任何小错误都可能酿成大祸:
-
剪枝风险:剪枝可能导致精度不稳定,尤其在边缘场景(edge cases,如低光照下的行人检测)中出错。非结构化剪枝的稀疏性或结构化剪枝的通道移除可能破坏模型的泛化能力。
-
后果:在医疗诊断中,模型漏诊一个罕见病例可能是灾难;在自动驾驶中,误判一个障碍物可能导致事故。
-
解决成本:虽然微调能缓解精度损失,但需要大量实验,增加工程负担。
例子:剪枝后的模型在正常场景表现OK,但在罕见场景(如金融欺诈检测中的异常交易)可能失灵。
6.5 产业更关注 end-to-end 部署效率
工业界更关心模型的端到端推理延迟和吞吐量,而不是单纯的参数量:
-
兼容性差:非结构化剪枝生成的稀疏模型可能不兼容硬件加速库(如TensorRT),结构化剪枝也可能与量化(如INT8)流程冲突,导致整体pipeline效率降低。
-
实际效果:剪枝减少了参数,但如果不能无缝融入量化和硬件优化,推理速度可能不如预期,甚至拖慢部署流程。
例子:一个量化+剪枝的模型可能无法充分利用GPU的并行计算优势,导致吞吐量下降。
小结:剪枝 vs 其他方法
以下表格对比剪枝、量化、轻量模型在工业界的优劣:
| 方法 | 加速效果 | 工程复杂度 | 工具成熟度 | 鲁棒性 | 适用场景 |
|---|---|---|---|---|---|
| 剪枝 | 中等(硬件依赖) | 高(多阶段调参) | 低(工具不成熟) | 中等(可能不稳定) | 特定场景(如稀疏支持硬件) |
| 量化 | 高(硬件友好) | 低(工具成熟) | 高(TensorRT等) | 高(精度稳定) | 手机、边缘设备 |
| 轻量模型 | 高(天生高效) | 低(直接部署) | 高(社区支持) | 高(经过验证) | 移动端、物联网 |
七、什么时候可能会用剪枝?
虽然主流企业较少使用剪枝,但在以下场景中剪枝仍具有潜力:
7.1 模型过大但无法替代结构
如使用大模型(ResNet-152、GPT)进行定制任务,但无法轻易切换为轻量模型,此时剪枝是一种可行优化手段。
7.2 结合稀疏硬件(如定制 AI 芯片)
如用 NVIDIA SparseTensor Core、TPU/FPGA 等稀疏计算优化器时,非结构剪枝才能带来真正加速。
7.3 学术研究或模型探索
剪枝仍是分析神经网络冗余、结构优化的重要方法,在 AutoML、神经结构搜索(NAS)中仍有广泛应用。
八、剪枝 vs 工业界需求
| 项目 | 剪枝技术 | 工业界期望 |
|---|---|---|
| 加速效果 | 可能存在/依赖稀疏支持 | 稳定可测的加速效果 |
| 精度影响 | 易损坏性能,需精调 | 精度稳定,几乎不降 |
| 工程成本 | 高:多轮试验 + 微调 | 低:一键部署 + 平台支持 |
| 工具链成熟度 | 一般 | 越成熟越好(ONNX、TensorRT) |
| 替代方案 | 蒸馏、量化、轻量模型 | ✅ 更加主流且成熟 |
九、 未来趋势:剪枝还会“火”起来吗?
可能会,取决于两个因素:
稀疏计算硬件的成熟:当通用硬件支持稀疏矩阵高效运算时,剪枝将迎来新的发展机会。
自动化工具链的完善:AutoPruner、AutoSlim 等自动剪枝框架成熟后,剪枝的门槛和成本会降低,可能重新回到工程主流。
十、总结
模型剪枝虽然理论上能让模型“瘦身”,但在工业界因加速效果有限、流程复杂、工具不成熟、鲁棒性风险和端到端效率问题而受冷落。相比之下,量化和轻量模型更简单、可靠,成为主流选择。
模型剪枝虽能有效减小模型体积和加速推理,但因精度风险高、工程复杂、工具不成熟,当前在工业界应用仍不如量化与轻量模型广泛。


















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











