







颜孙炜 2024.7
鸢尾花数据集(Iris dataset)是一个经典的多变量分类问题的数据集,常用于机器学习算法的演示和教学。逻辑回归作为一种广义的线性模型,通过引入Sigmoid函数将线性回归的输出映射到0和1之间,从而适用于二分类问题。在鸢尾花数据集的分类问题中,我们可以通过逻辑回归模型来预测鸢尾花的种类。
通过使用逻辑回归进行鸢尾花数据集的分类问题,我们可以发现逻辑回归模型在处理这类多变量分类问题时具有较好的表现。然而,逻辑回归模型也有一些局限性,例如对于非线性关系的处理能力较弱。在未来的研究中,我们可以尝试使用其他更复杂的模型(如支持向量机、决策树或神经网络等)来解决这个问题,并比较不同模型在鸢尾花数据集分类问题上的性能表现。同时,我们还可以进一步探索特征选择和特征工程的方法,以提高模型的分类性能。 总之,使用逻辑回归进行鸢尾花数据集的分类问题是一个很好的实践案例,它有助于我们深入理解逻辑回归模型的原理和应用,并为我们解决其他分类问题提供了有益的参考。


 鸢尾花数据集的基本特征和数据结构。数据集包含150条记录,每条记录有四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和一个标签(花的种类)。这为后续的分类任务奠定了基础。
鸢尾花数据集的基本特征和数据结构。数据集包含150条记录,每条记录有四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和一个标签(花的种类)。这为后续的分类任务奠定了基础。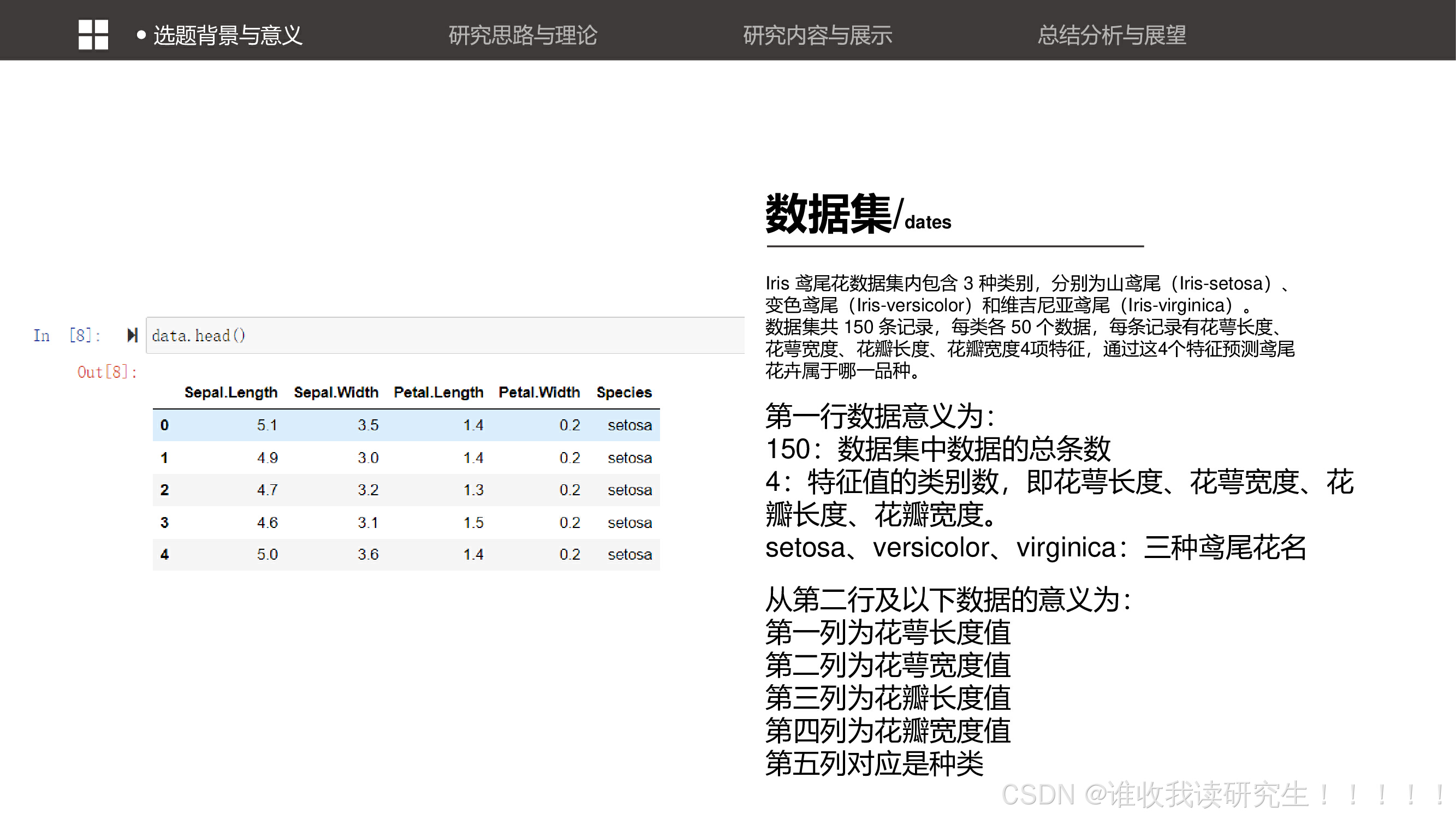 进一步解释了数据集中每一列的具体含义,包括花萼和花瓣的尺寸以及对应的花的种类。这有助于理解数据集的组成和如何利用这些特征进行分类。
进一步解释了数据集中每一列的具体含义,包括花萼和花瓣的尺寸以及对应的花的种类。这有助于理解数据集的组成和如何利用这些特征进行分类。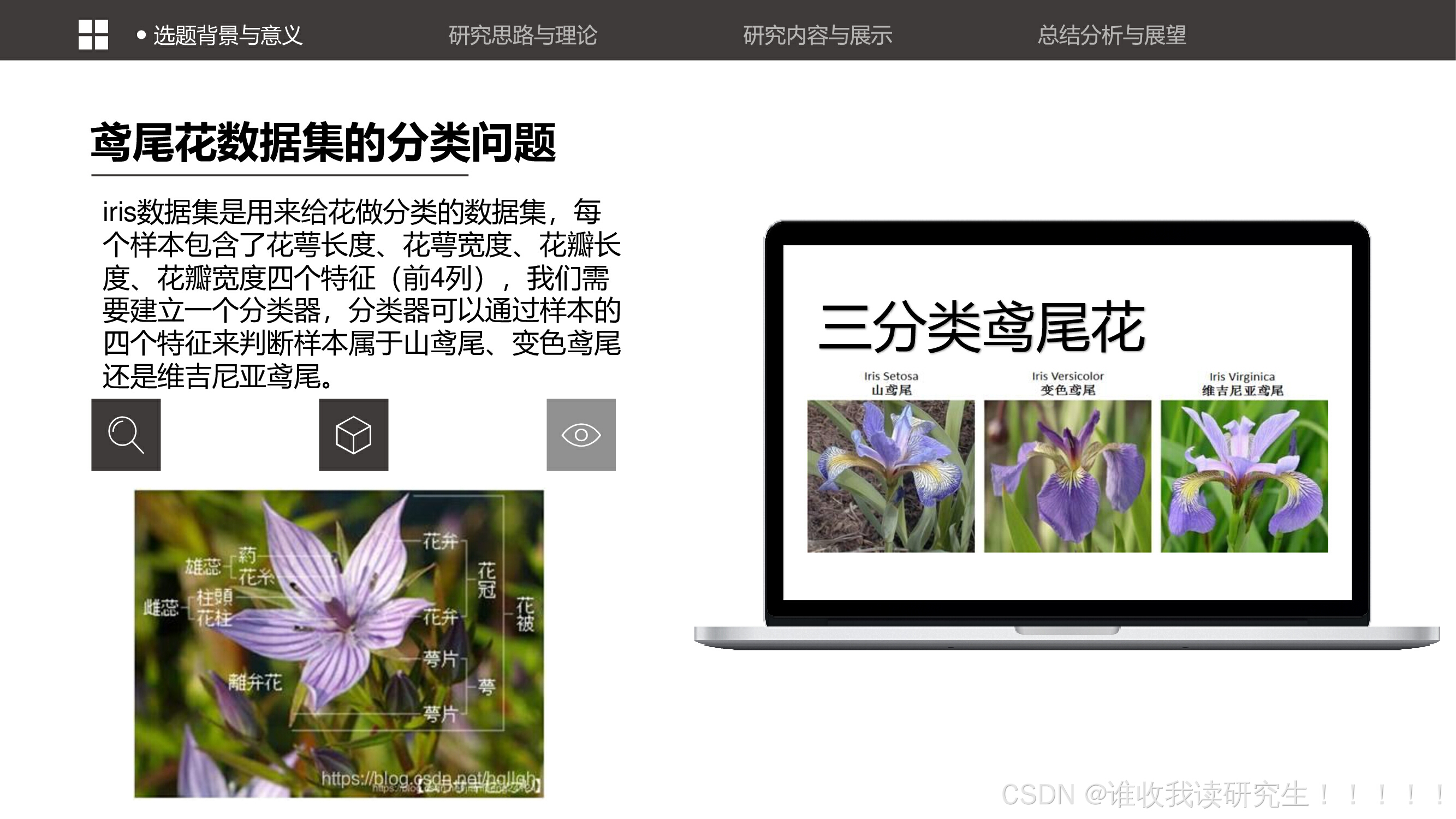
 逻辑回归的基本原理,包括其在分类问题中的应用。逻辑回归通过Sigmoid函数将线性模型的输出映射到0和1之间,实现分类。
逻辑回归的基本原理,包括其在分类问题中的应用。逻辑回归通过Sigmoid函数将线性模型的输出映射到0和1之间,实现分类。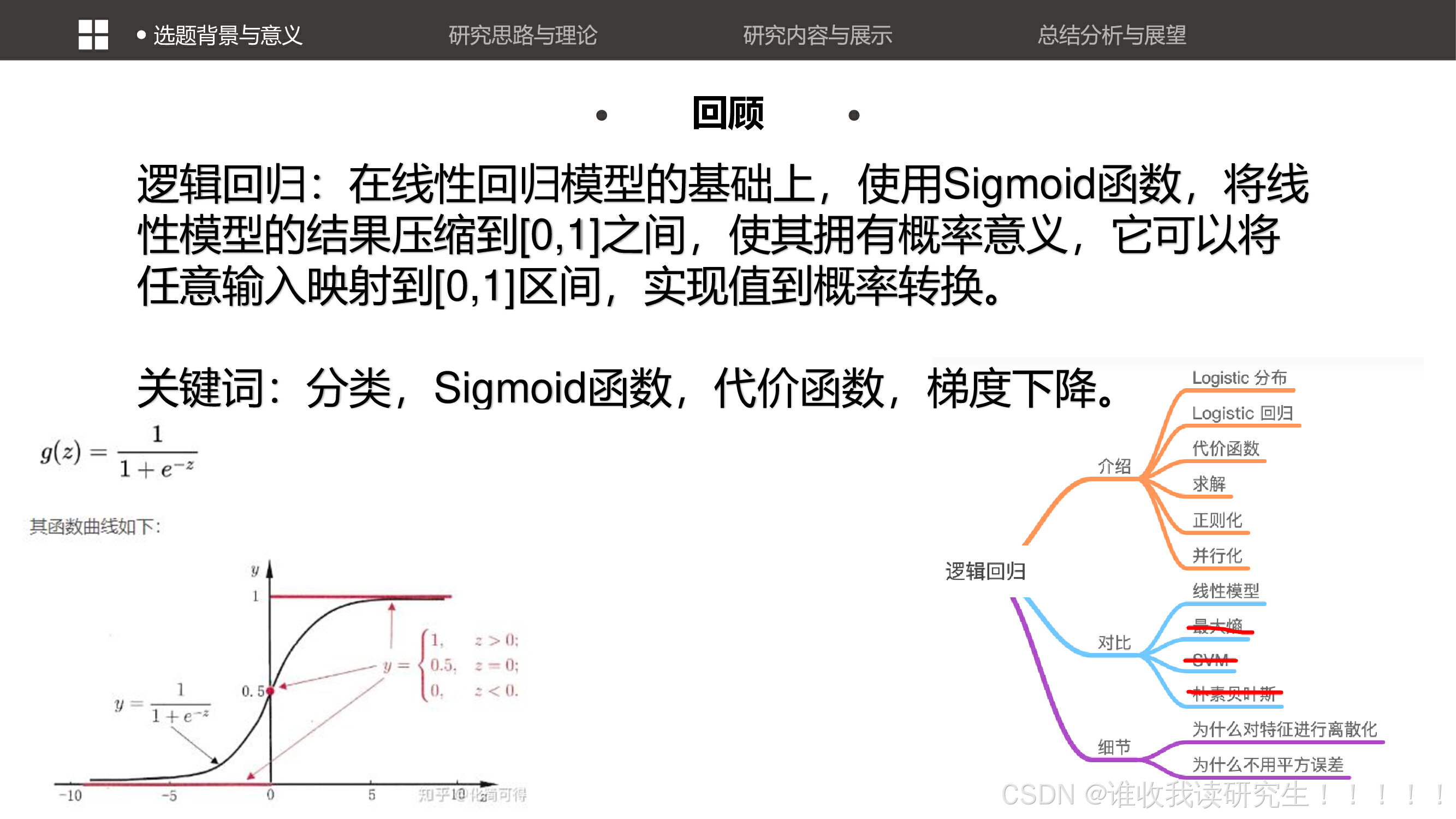
 解决鸢尾花分类问题的步骤,包括分析问题、查看数据集、数据清洗、数据可视化、特征工程、特征选择、机器学习组织和交叉检验。
解决鸢尾花分类问题的步骤,包括分析问题、查看数据集、数据清洗、数据可视化、特征工程、特征选择、机器学习组织和交叉检验。 展示了数据的可视化图表,如饼状图、柱形图和散点图,帮助观众更直观地理解数据的分布和特征之间的关系。讨论了特征选择的重要性,并展示了如何通过选择不同的特征(如花萼或花瓣)来提高分类器的性能。
展示了数据的可视化图表,如饼状图、柱形图和散点图,帮助观众更直观地理解数据的分布和特征之间的关系。讨论了特征选择的重要性,并展示了如何通过选择不同的特征(如花萼或花瓣)来提高分类器的性能。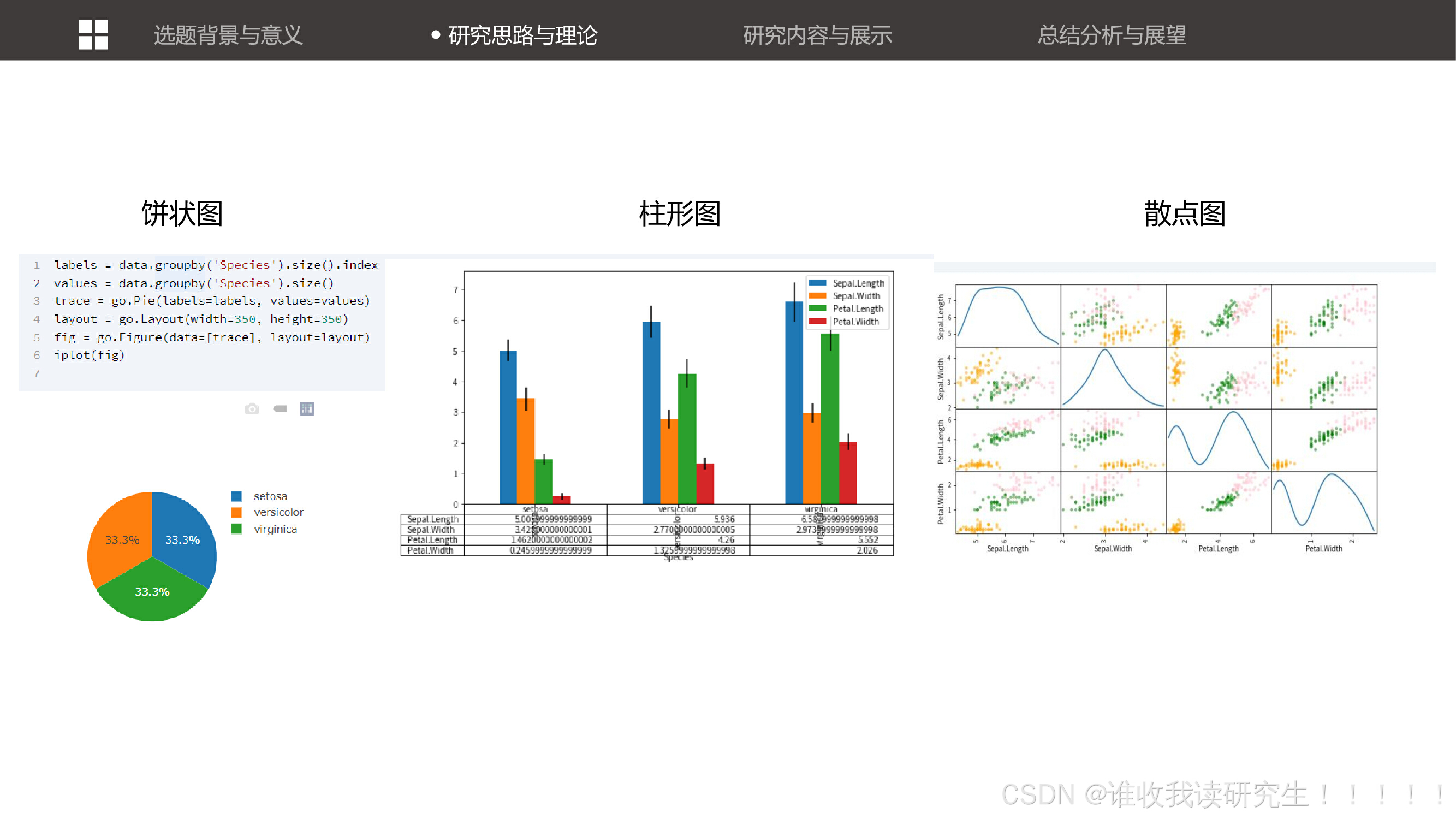 讨论了特征选择的重要性,并展示了如何通过选择不同的特征(如花萼或花瓣)来提高分类器的性能。
讨论了特征选择的重要性,并展示了如何通过选择不同的特征(如花萼或花瓣)来提高分类器的性能。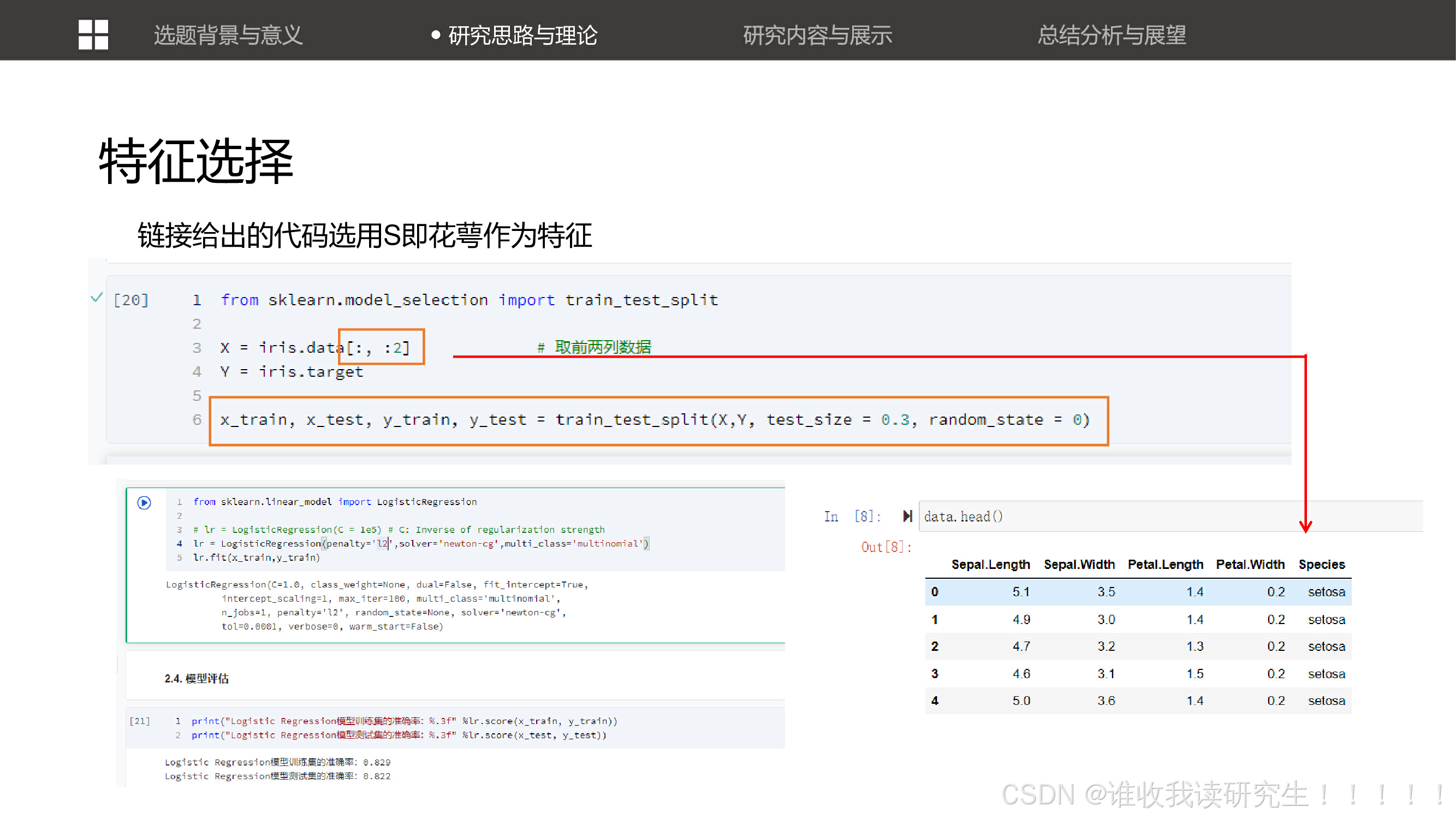 改进后的代码1.0,使用花瓣作为特征进行分类。这展示了如何通过调整特征选择来优化模型。
改进后的代码1.0,使用花瓣作为特征进行分类。这展示了如何通过调整特征选择来优化模型。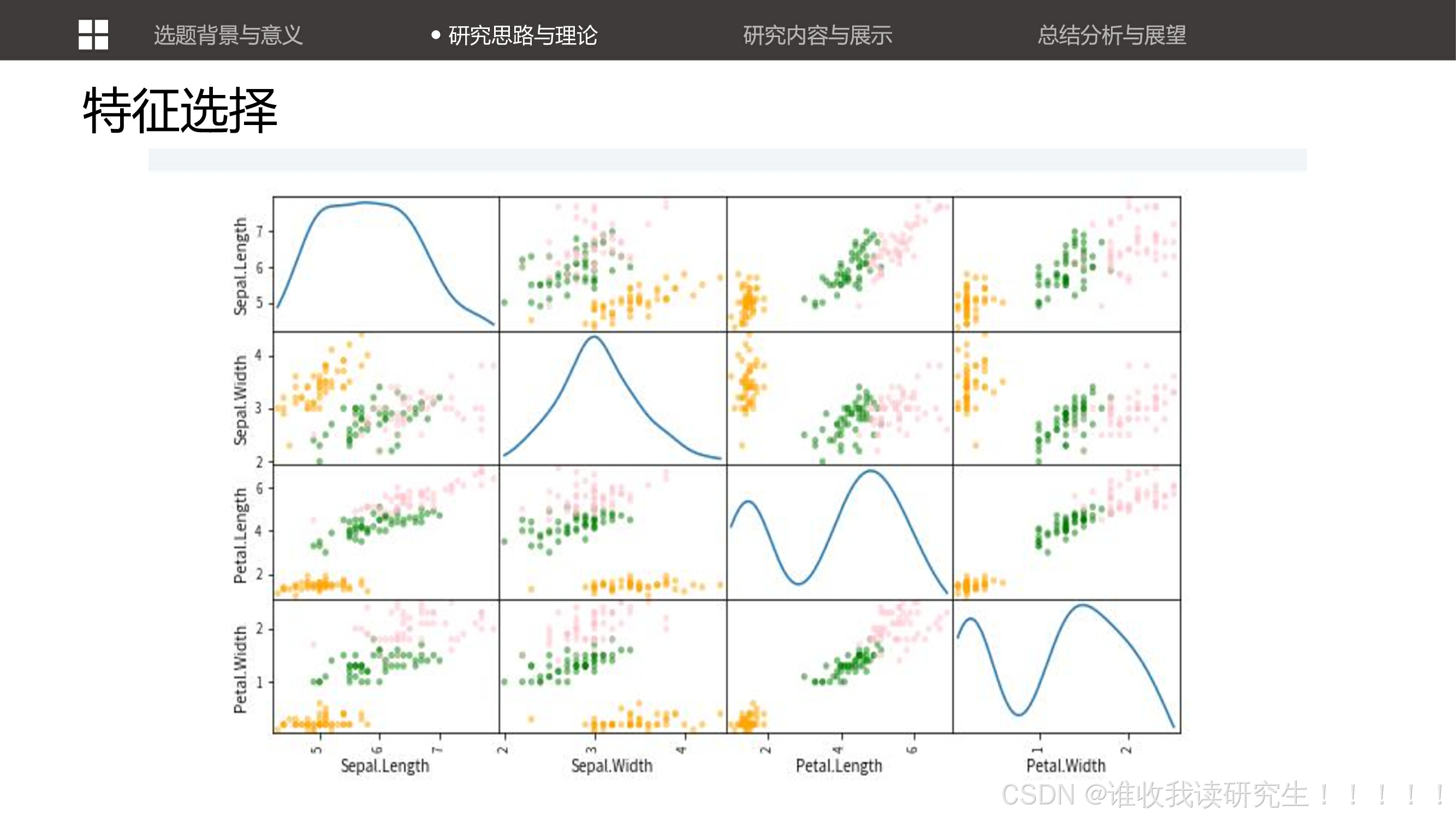 讨论了如何通过调整机器学习模型的参数(如损失函数和优化器)来提高模型的性能。
讨论了如何通过调整机器学习模型的参数(如损失函数和优化器)来提高模型的性能。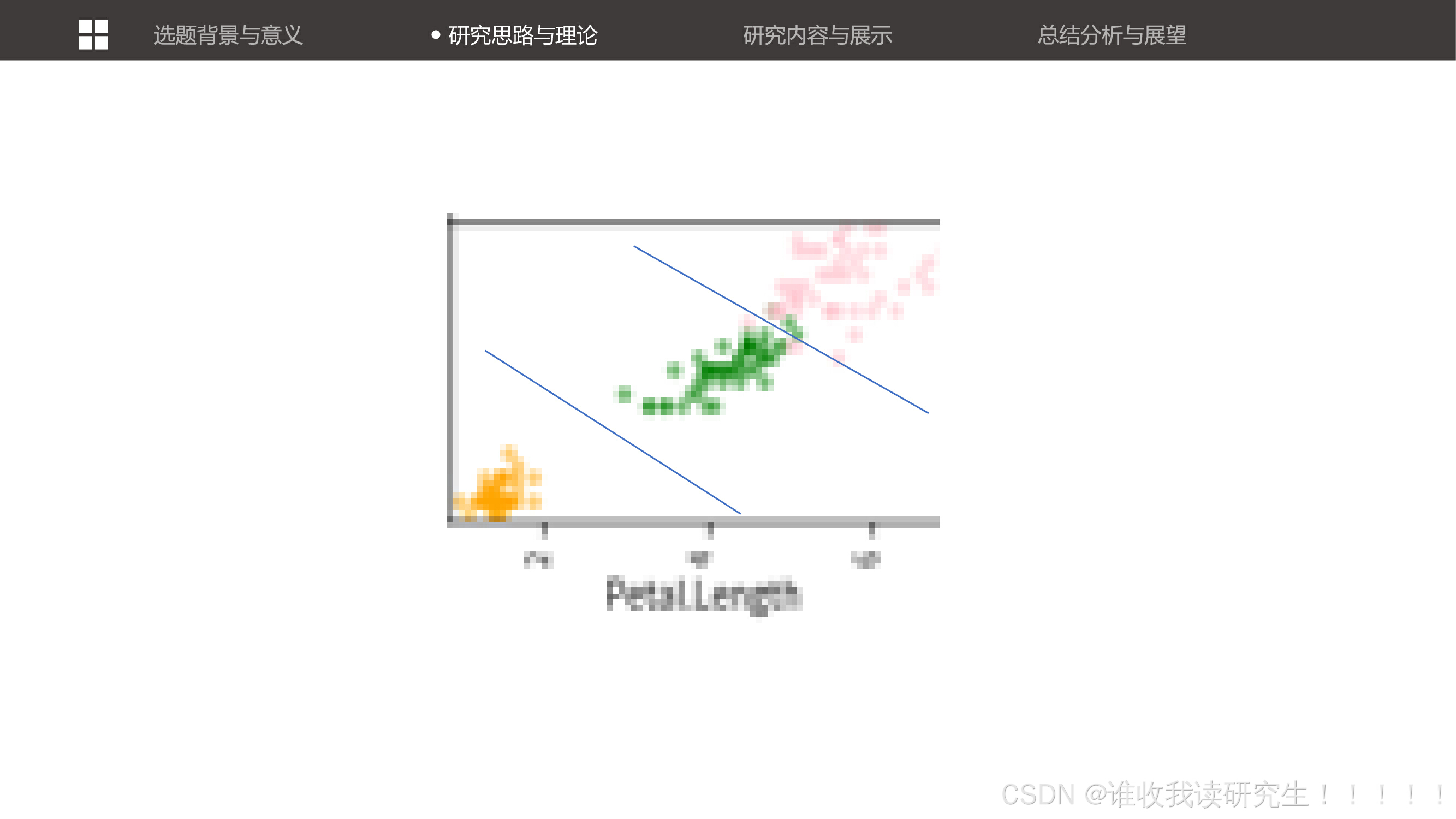 通过更换不同的机器学习模型(如k临近算法)来解决分类问题,并讨论了这些模型的性能。
通过更换不同的机器学习模型(如k临近算法)来解决分类问题,并讨论了这些模型的性能。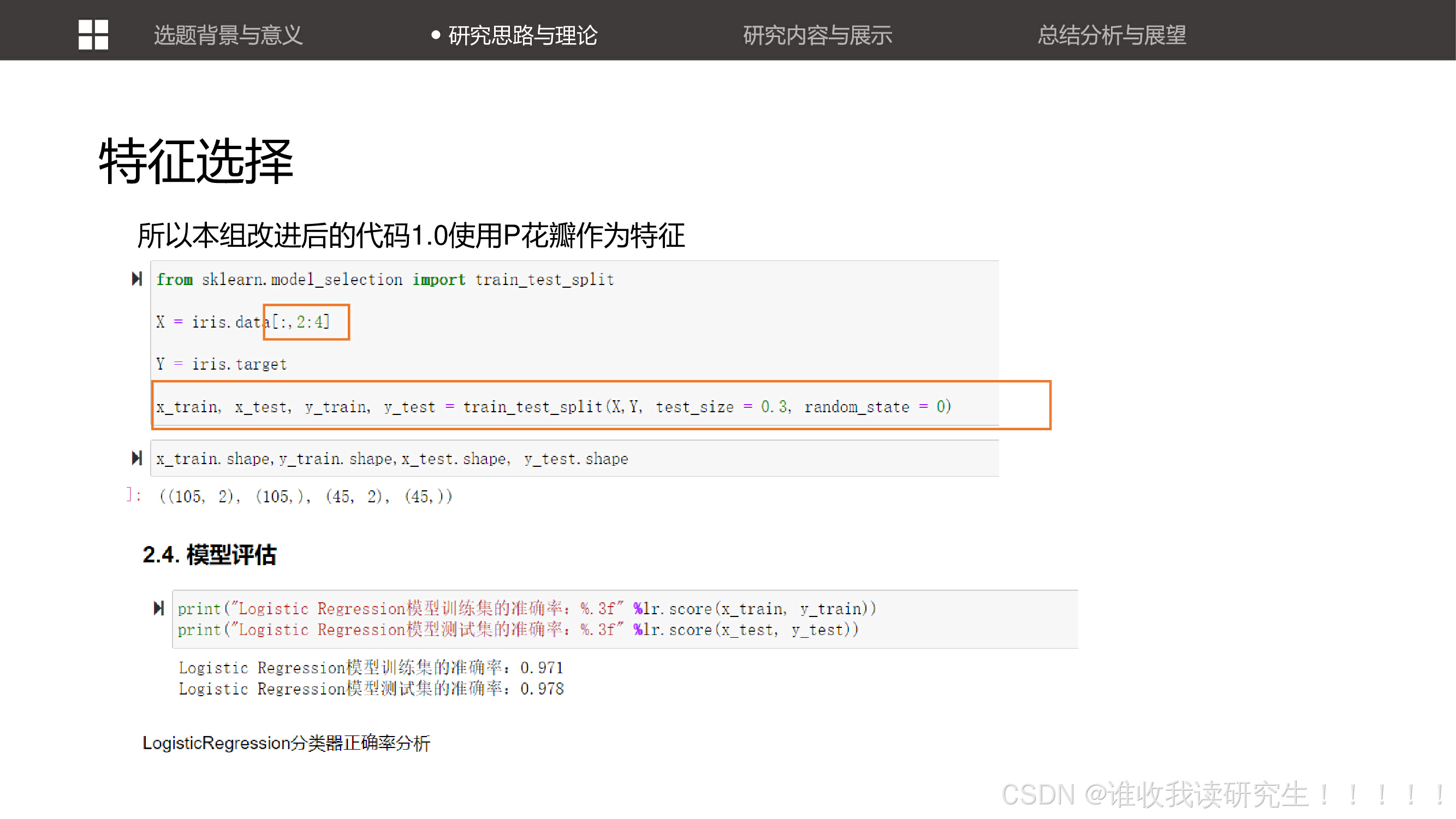 展示了使用逻辑回归对全部特征进行学习时模型的正确率,强调了模型在不同特征选择下的性能表现。
展示了使用逻辑回归对全部特征进行学习时模型的正确率,强调了模型在不同特征选择下的性能表现。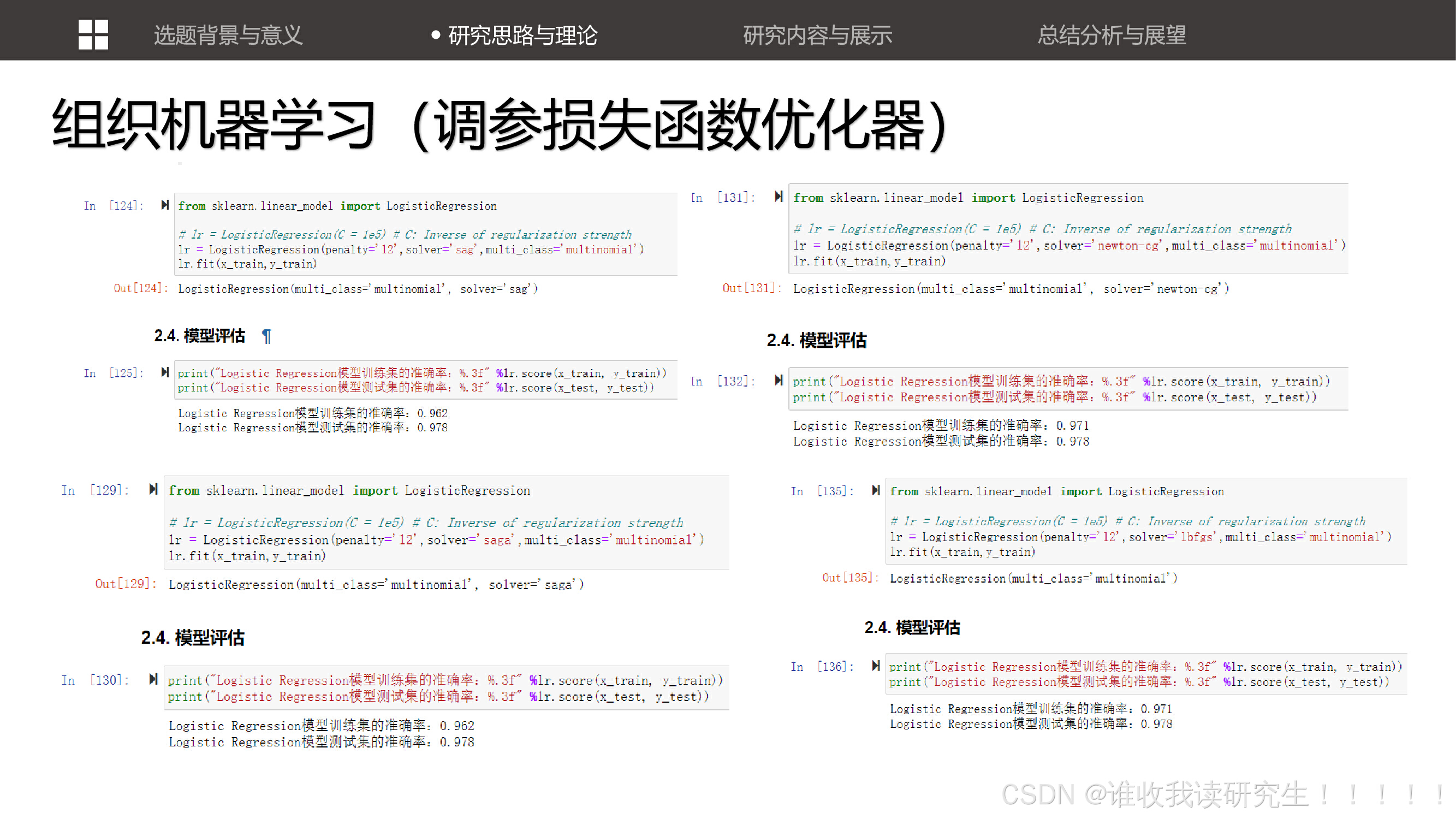 展示了使用逻辑回归对全部特征进行学习时模型的正确率,强调了模型在不同特征选择下的性能表现。
展示了使用逻辑回归对全部特征进行学习时模型的正确率,强调了模型在不同特征选择下的性能表现。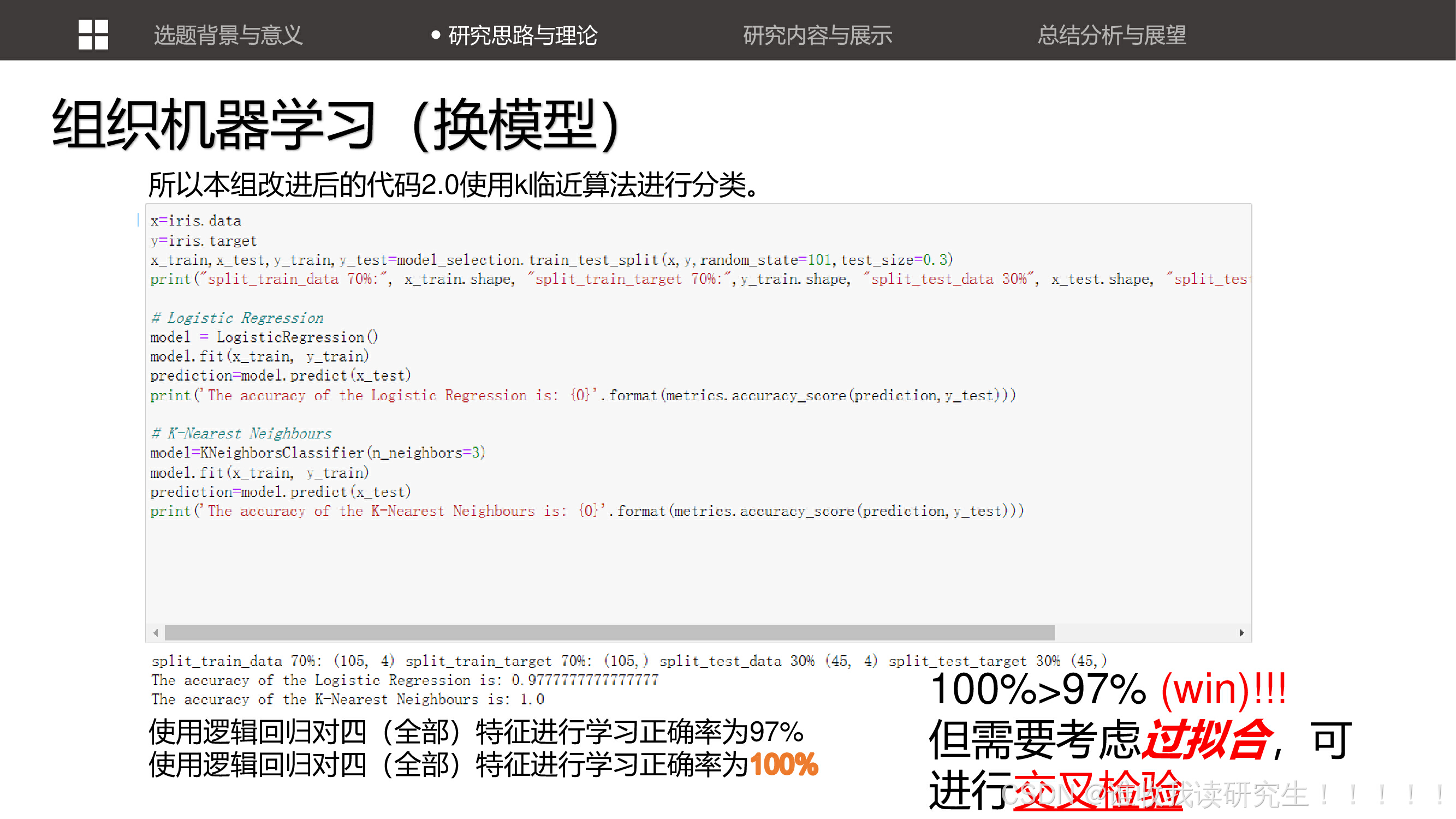




















 3087
3087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









