







- 论文:https://arxiv.org/pdf/2410.18050
- 代码:https://github.com/QingFei1/LongRAG
- 机构:BAAI,中国科学院,清华大学
- 领域:长上下文检索
- 发表:arxiv

研究背景
-
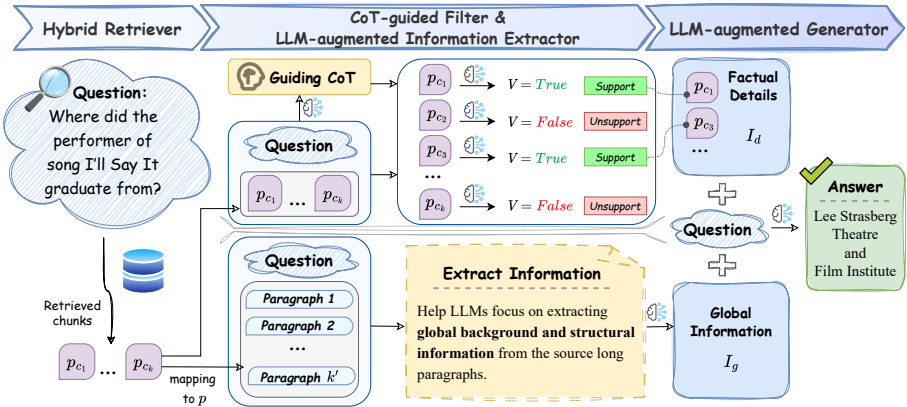
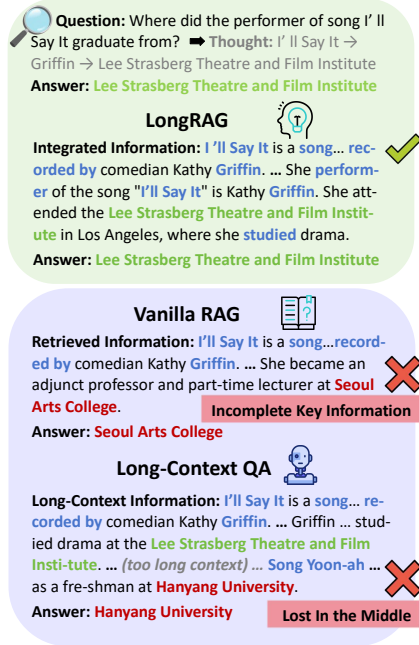
研究问题:这篇文章要解决的问题是长上下文问答(Long-Context Question Answering, LCQA),即通过推理长文档或多个文档来准确回答问题的任务。现有的长上下文大型语言模型(LLMs)在处理长上下文时常常遇到“中间丢失”和“关键信息不完整”的问题。
-
研究难点:该问题的研究难点包括:长上下文分割策略会破坏全局长上下文信息;长上下文中低证据密度导致检索质量低,LLM难以识别有效的事实细节。
-
相关工作:该问题的研究相关工作有:长上下文LLMs如Gemini和GPT-4-128k能够直接处理整个相关文档并生成答案,但容易遇到“中间丢失”问题;检索增强生成(RAG)系统通过固定长度分块策略缓解了这个问题,但仍存在全局信息和事实细节识别不足的问题。
研究方法
这篇论文提出了LongRAG,一种通用的、双视角的、鲁棒的基于LLMs的RAG系统范式,用于解决LCQA任务中的全局信息和事实细节识别问题。具体来说,
- 混合检索器:首先,使用双编码器结构进行粗粒度快速检索,然后使用交叉编码器进行细粒度深度语义交互检索。为了提高检索效率,使用了FAISS库。
- LLM增强信息提取器:将短分块映射回源长上下文段落,利用LLM的零样本上下文学习(ICL)能力提取全局信息。公式如下:
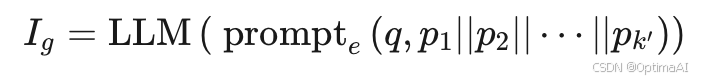
其中,p表示分块,p表示源长上下文段落,q表示问题。

3. CoT引导过滤器:使用Chain of Thought(CoT)提供全局线索,指导LLM逐步关注相关知识点。公式如下:
![]()
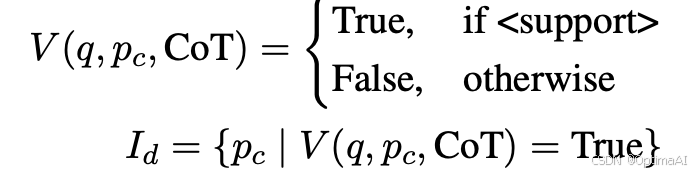
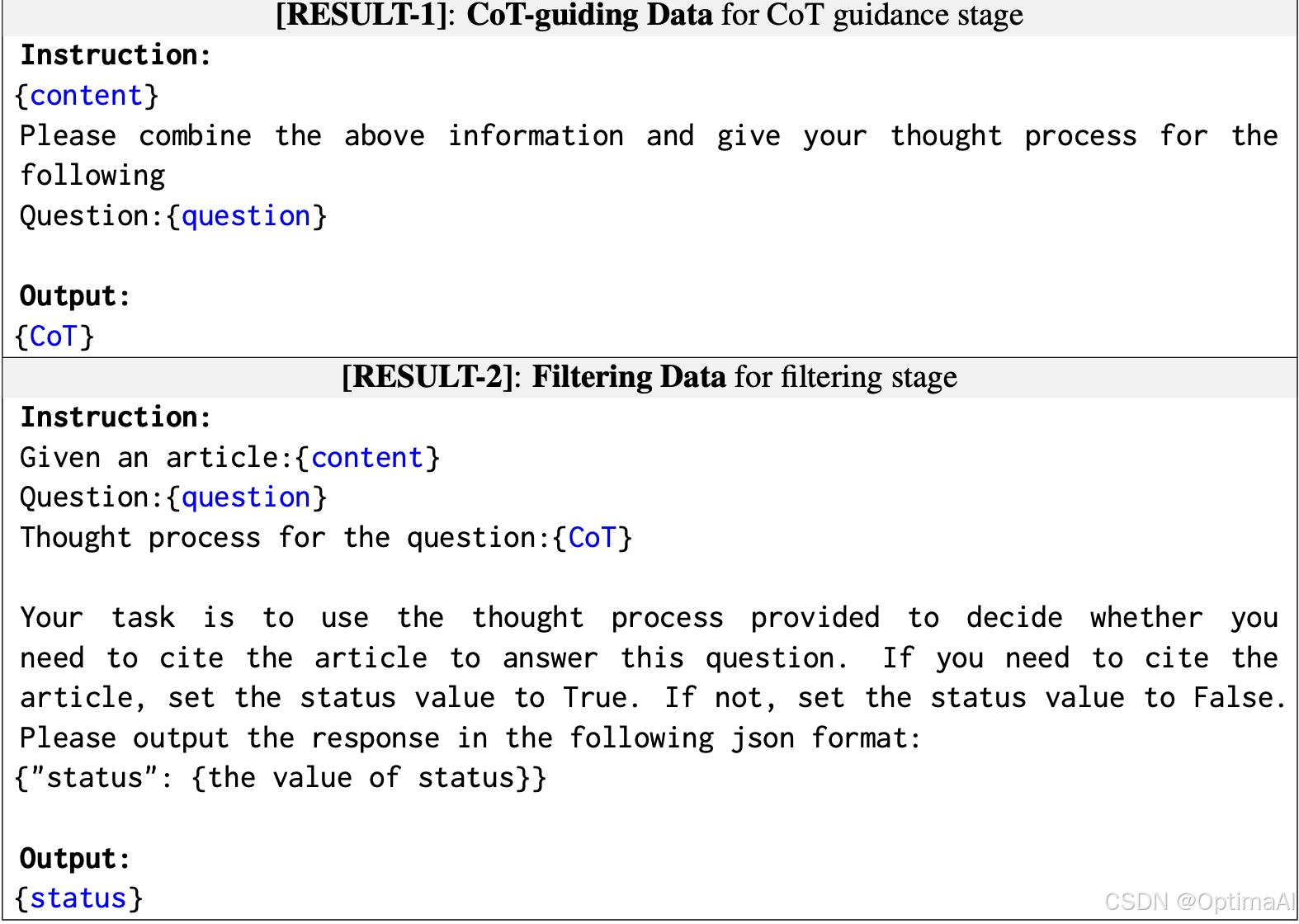
4. LLM增强生成器:促进全局信息和事实细节之间的知识交互,生成最终答案。公式如下:
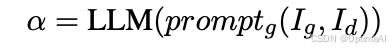

其中,Ig表示全局信息,Id表示事实细节,LLM表示LLM模型,promptg表示生成器的提示模板。
实验设计
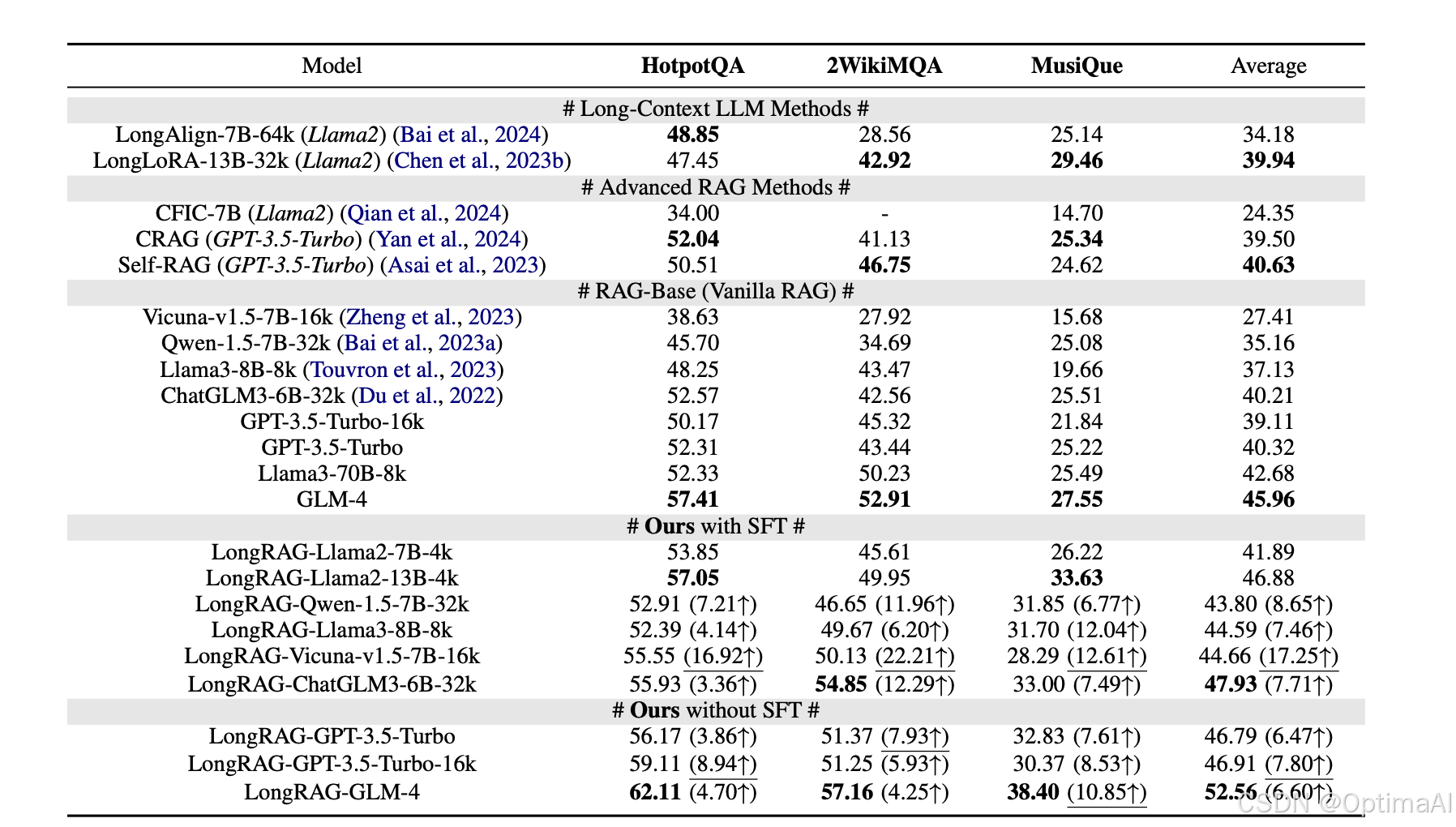
- 数据集选择:选择了三个多跳数据集HotpotQA、2WikiMultiHopQA和MusiQue进行评估。这些数据集经过标准化处理以适应RAG任务。
- 基线和方法:对比了三种类型的基线方法:长上下文LLMs方法(如LongAlign和LongLoRA)、高级RAG方法(如CFIC和CRAG)以及基于各种LLMs的Vanilla RAG。
- 参数配置:使用ChatGLM3-6B-32k、Qwen1.5-7B-32k、Vicuna-v1.5-7B-16k、Llama2和Llama3作为基础LLMs,并使用2600个高质量数据进行微调。训练参数设置为批量大小8,梯度累积步数12,共3个epoch(共81步)。
结果与分析
-
整体性能:在三个数据集上的实验结果表明,LongRAG显著优于长上下文LLMs、高级RAG方法和Vanilla RAG。具体来说,LongRAG在HotpotQA数据集上平均提高了6.94%,在2WikiMultiHopQA数据集上平均提高了6.16%,在MusiQue数据集上平均提高了17.25%。
-
-
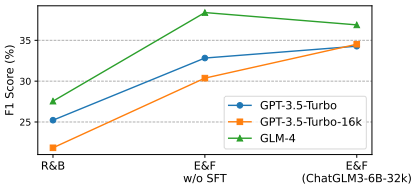
消融研究:通过消融研究分析了信息提取器和CoT引导过滤器的有效性。结果表明,信息提取器和CoT引导过滤器的联合策略(E&F)在所有数据集上均表现最佳,显著提高了系统的性能。
-
组件可迁移性:E&F组件在不同数据集上的迁移性分析表明,使用低成本本地模型(如ChatGLM3-6B-32k)替代昂贵的在线API资源,仍能取得优异的性能。
总体结论
这篇论文构建了一个有效且鲁棒的RAG系统范式LongRAG,通过双信息视角增强了RAG在LCQA任务中的性能。LongRAG解决了现有方法中存在的全局信息收集不完整和事实细节识别困难的问题。通过多维实验验证了LongRAG的优越性和所提出组件及微调策略的有效性。LongRAG显著优于长上下文LLMs、高级RAG方法和Vanilla RAG,并成功使用小参数规模LLMs替代昂贵的在线API资源。此外,提供了自动化微调指令数据构建管道,极大地方便了将该范式应用于其他特定领域数据。
论文评价
优点与创新
- 提出了一个新的RAG系统范式:LongRAG通过双重信息视角显著提升了LCQA任务中RAG的性能。
- 解决了现有方法的两大问题:LongRAG解决了现有方法在长上下文信息收集不完整和在大量噪声中精确识别事实信息的困难。
- 组件的可插拔性:LongRAG设计了四个可插拔的组件,包括混合检索器、LLM增强的信息提取器、CoT引导的过滤器和LLM增强的生成器,便于适应不同领域和LLMs。
- 自动化指令数据构建管道:实现了一个新的自动化微调指令数据构建管道和多任务训练策略,便于将LongRAG应用于其他特定领域的数据。
- 广泛的实验验证:在三个多跳数据集上的广泛实验表明,LongRAG显著优于长上下文LLMs、高级RAG方法和传统的RAG方法。
- 组件的可迁移性:通过实验验证了提取器和过滤器的组件在不同数据集上的可迁移性,证明了其强大的鲁棒性和可转移性。
不足与反思
- 一次性检索依赖性:本研究仅调查了一次性检索场景下的信息提取器和CoT引导过滤器的性能,检索的质量依赖于单次检索的块的质量。未来可以通过与核心组件的交互开发自适应的多轮检索策略来改进。
- 数据集注释偏差:尽管使用了参数为320亿的ChatGLM3模型生成高质量的微调数据集,但这种规模的模型可能仍然容易受到自生成数据集中固有的注释偏差的影响。跨领域和多任务环境中不同规模LLMs的指令数据集的性能需要进一步研究。


















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











