







推荐系统的一些基本知识
在学习协同过滤推荐算法之前,我认为有必要了解以下推荐系统大致的分类的知识。
推荐系统可以分为(根据是否使用深度学习算法)
- 前深度学习时代推荐算法
- 深度学习时代推荐算法
传统推荐系统算法(前深度学习时代推荐系统)的类别可以分为:
- 协同过滤推荐:依赖用户的交互数据,如评分、购买、点击等。协同过滤不需要物品的任何内容特征,只需要用户行为数据。
- 基于内容的推荐:依赖物品的内容特征,如文本描述、标签、类别等。它需要对物品进行特征提取,以便进行内容匹配。
- 混合推荐:结合了多种推荐方法(例如,协同过滤、基于内容的推荐等),以弥补单一推荐方法的不足。
( 协同过滤推荐 和 基于内容的推荐 两者最明显的区别:它们所需的数据不同,最终的推荐效果也会因为用作推荐的依据不同而导致推荐的效果相差异,各自有各自的适用场景)
协同过滤推荐
协同过滤的含义:协同大家的反馈、评价和意见一起对海量信息进行过滤。(而不关注用户和物品本身可能具有的特征)
协同过滤推荐算法分类:
- 基于用户的协同过滤推荐
- 基于物品的协同过滤推荐
以上两者分类的的依据是它们如何计算相似度和依据相似度做推荐的部分。(听到这你可能还有点懵😳,先别急~,继续往后面看😊)
🌟基本思想:
- 基于用户的协同过滤推荐:通过计算用户相似度,找到与目标用户行为相似的其他用户,推荐相似用户正反馈交互过的物品。
- 基于物品的协同过滤推荐:通过计算物品相似度,找到与用户交互过的物品相似的其他物品,推荐相似物品给目标用户。
🌟算法流程:
- 根据用户和物品交互记录构建有向图(有向图的弧表示用户对物品的互动记录)(下图中(b))
- 根据有向图构建共现矩阵(横纵坐标分别表示用户和物品,交叉地方表示某用户对某物品的交互记录)(下图中(c))
- 问题转变为预测共现矩阵中空缺值的问题(下图中(c))
- 根据共现矩阵计算用户(物品)相似度,并构建相似度矩阵(横纵坐标分别表示用户(或物品),交叉地方表示某用户(物品)跟某用户(物品)的相似度)
- 根据最相似的用户(物品)群以及它们对应的评价记录计算空缺值(下图中(e))
(现在你应该对算法的大致流程熟悉啦,但你可能还是会疑惑 相似度怎么计算捏?怎么通过用户(物品)相似度进行推荐呢?请见下文😏)
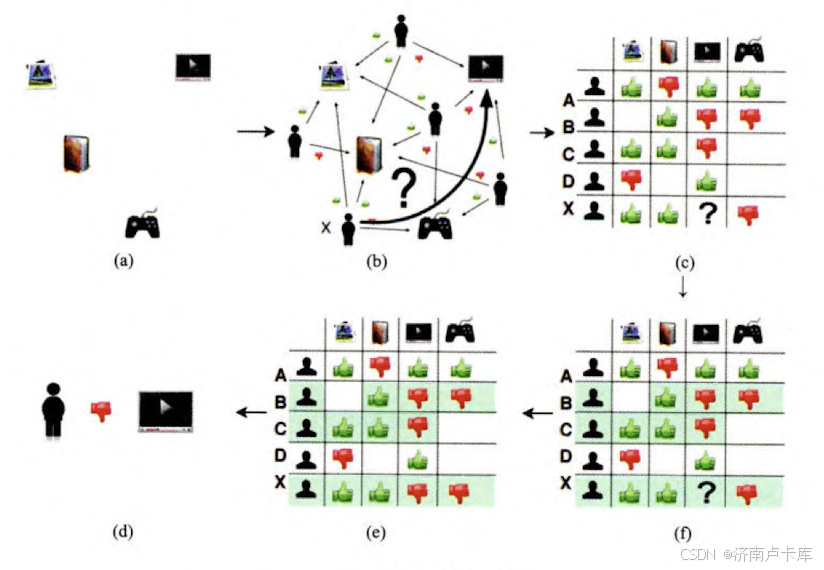
基于用户的协同过滤(User CF)
用户相似度计算方法
余弦相似度
定义:衡量了用户向量i和用户向量j之间的夹角大小。(用户向量:实际上对应的是上图共现矩阵中(c)中的一行)
(相似度越高,夹角越小,余弦相似度越高)
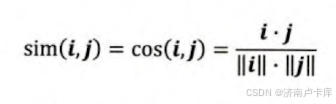
(要是只是想大概了解,后面 皮尔逊相关系数 就不用管啦😎)
皮尔逊相关系数
余弦相似度 存在的问题:存在用户之间打分标准不同的可能。例如:一个用户给所有物品都打了较高的分数,则预先相似度会计算出来他与其他用户相似度都较高。
因此引入皮尔逊相关系数
定义:通过用户平均分对各独立评分进行修正,减少了用户评分偏置的影响。
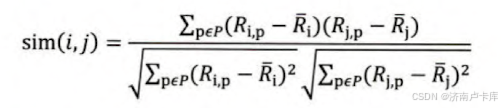

皮尔逊相关系数思路的另一种方式
存在问题:各个物品的平均评分存在偏差。
定义:通过物品平均分对各独立评分进行修正,减少了物品评分偏置的影响。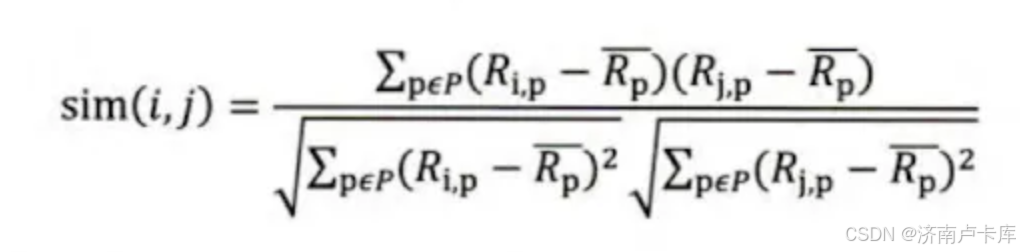
最终结果排序
最常用方法:利用用户相似度和相似用户的评价加权平均获得目标用户的评价预测。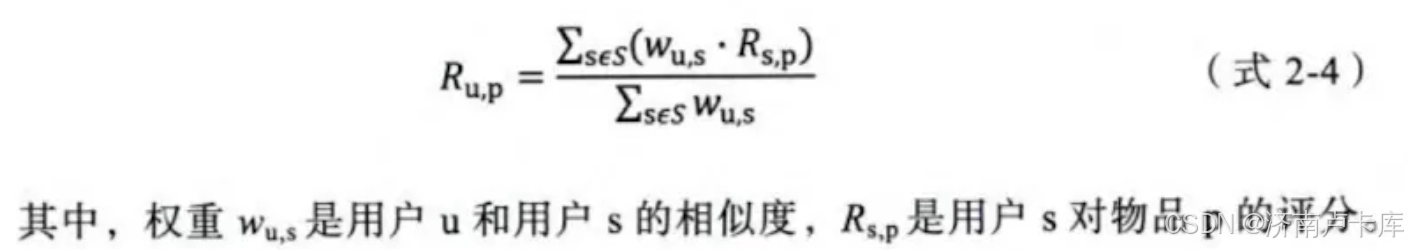
基于物品的协同过滤(Item CF)
相似度计算方式与UserCF相同,这里不过多介绍啦
最终结果评分预测也与UserCF类似: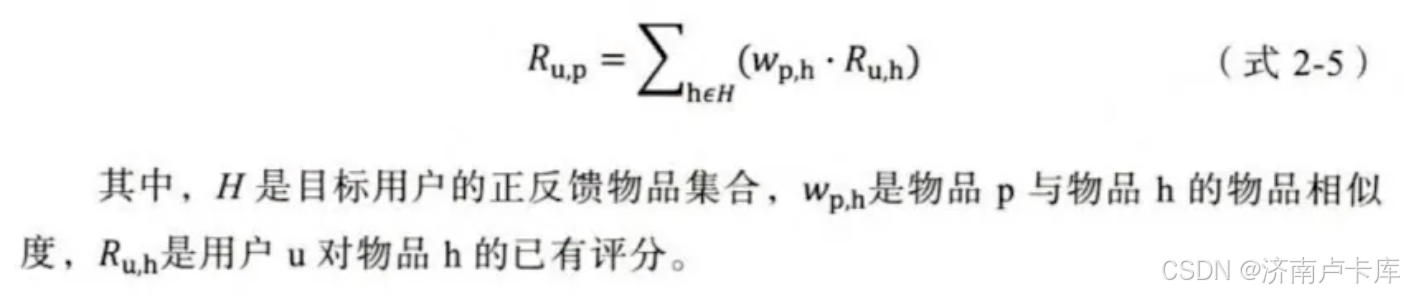
UserCF和ItemCF比较
| UserCF | ItemCF |
|---|---|
| 用户量大的时候计算量大 | 物品量大的时候计算量大 |
| 更强的社交特性 | 更稳定的兴趣点 |
| 适用于新闻推荐场景 | 适用于电商,视频推荐场景 |
协同过滤的缺点
无法将两个物品相似的信息推广到其他物品相似度的计算上,处理稀疏向量的能力弱
(个人理解,用户A对物品a和b评价,用户B对物品b和c评价,用户C对物品c和物品d评价,则协同过滤无法计算到物品a和d的相似度)
导致问题:热门物品具有很强的头部效应,容易与大量物品产生相似性。冷门物品则很难被推荐。
声明:本章内容主要源于王喆老师的《深度学习推荐系统》,是一本很好的推荐系统的书,强力推荐👍。
如果您觉得对您有帮助,请留下宝贵的赞赞吧🥺,我真的很需要。


















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









