







 本文介绍了SparkSQL的使用方法,包括数据读取、查询操作和临时表创建,并通过实例展示了如何执行SQL语句进行数据过滤、聚合等操作。此外,还简述了SparkStreaming的基本概念及其在实时数据处理中的应用。实验过程涵盖了数据加载、DataFrame转换和SQL查询,为读者提供了深入理解SparkSQL和SparkStreaming的实践经验。
本文介绍了SparkSQL的使用方法,包括数据读取、查询操作和临时表创建,并通过实例展示了如何执行SQL语句进行数据过滤、聚合等操作。此外,还简述了SparkStreaming的基本概念及其在实时数据处理中的应用。实验过程涵盖了数据加载、DataFrame转换和SQL查询,为读者提供了深入理解SparkSQL和SparkStreaming的实践经验。
目录
学习目标:
熟悉 Spark SQL 的使用方法。
学习内容:
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2, a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过 程中的Result、DataSource、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。 执行Spark SQL语句的顺序为: 1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如 SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source 等,从而判断SQL语句是否规范; 2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如 果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行 的; 3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据 库会在这些计划中选择一个最优计划(Optimize); 4.计划执行(Execute),按Operation-->Data Source-->Result的次序来进行 的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运 行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果
实验环境:
操作系统:Linux
开发环境:pyspark 交互式命令行
基本概念:
Spark SQL的特点:容易整合,统一的数据访问方式,兼容Hive,标准的数据连接。
Spark SQL与Hive SQL的区别:Hive SQL通过转换成MapReduce任务,然后提交到集群上执行,简化了编写MapReduce的程序的复杂性。但由于MapReduce这种计算模型执行效率比较慢,Spark SQL的应运而生。SparkSQL是一个SQL解析引擎,SQL解析成特殊RDD(DataFrame),然后在Spark集群中运行
Spark Streaming介绍:
什么是 Spark Streaming
Spark Streaming用于流式数据的处理,使得构建可扩展容错流应用程序变得容易。Spark Streaming具有易于使用、高容错性、高吞吐量等特点,它能够胜任实时的流计算,Spark Streaming 可以接收从 Socket、文件系统、Kafka、 Flume等数据源产生的数据,并对其进行实时处理。同时Spark Streaming 也能和机器学习库(MLlib)以及图计算库(Graphx)进行无缝衔接、实时在线分析。

流数据加载:
初始化StreamingContext
from pyspark import SparkContext #导入SparkContext包
from pyspark.streaming import StreamingContext
#导入Spark Streaming包
sc = SparkContext(master,appName) #创建SparkContext对象
ssc = StreamingContext(sc,1)#创建DStream
#scc为DStream,可以通过type查看
type(ssc )


实验步骤:
#文件下载
wget http://10.90.45.135:8081/repository/hadoop/spark/book.txt
#输入代码
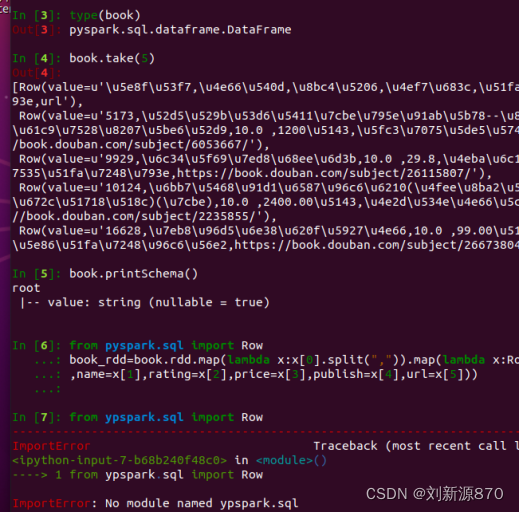
book=spark.read.text("file:///home/Desktop/book.txt")
#查看前五行book.take(5)
#查看类型
type(book)
#打印schema(表头和数据类型)
book.printSchema()
#将book的DataFrame转换为RDD操作
from pyspark.sql import Row
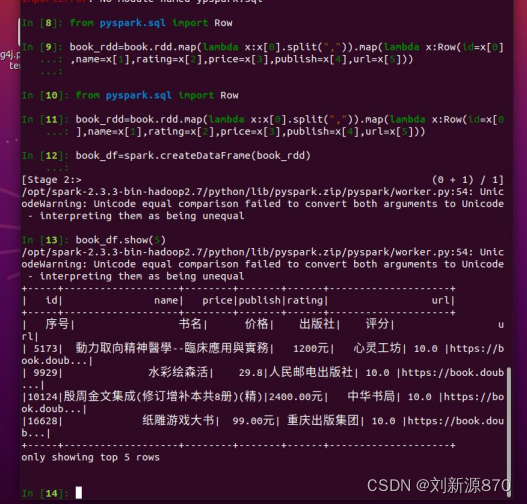
book_rdd=book.rdd.map(lambda x:x[0].split(",")).map(lambda x:Row(id=x[0],name=x[1],rating=x[2],price=x[3],publish=x[4],url=x[5]))#创建dataFrame
book_df=spark.createDataFrame(book_rdd)
#查询前五行数据
book_df.show(5)
#打印schema
book_df.printSchema()
#创建临时表
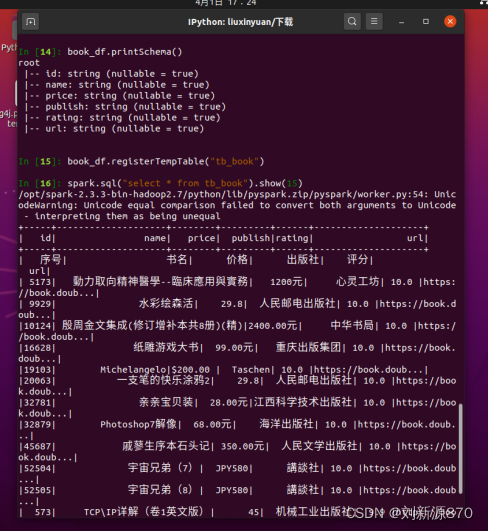
book_df.registerTempTable("tb_book")
#使用sql语句查询
spark.sql("select * from tb_book").show(15)
#模糊查询书名包含“微积分”的书
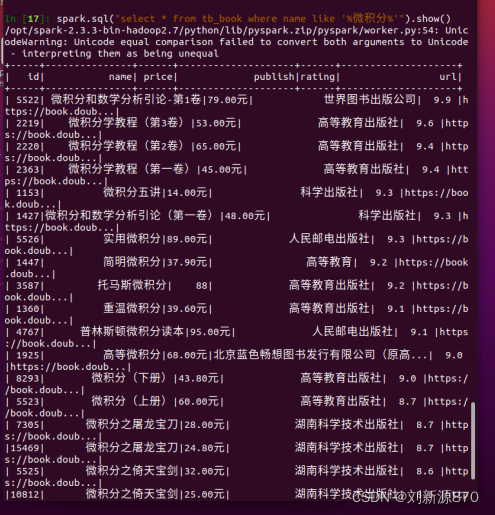
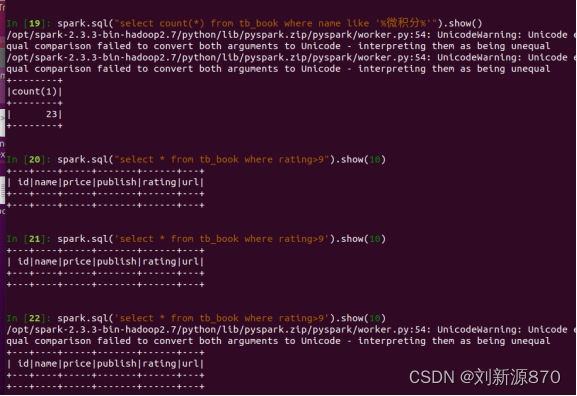
spark.sql("select * from tb_book where name like '%微积分%'").show()
#输出图书的前10行的name和price字段信息
spark.sql("select name,price from tb_book ").show(10)
#计算所有书名包含“微积分”的评分平均值
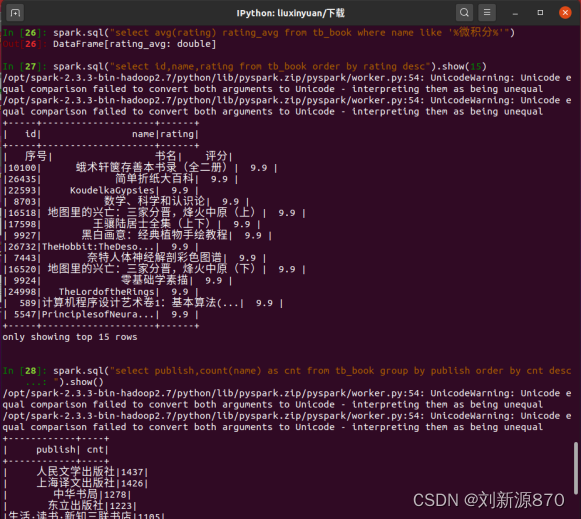
spark.sql("select avg(rating) rating_avg from tb_book where name like '%微积
分%'")#把书目按照评分从高到低进行排列
spark.sql("select id,name,rating from tb_book order by rating desc").show(15)
#把图书按照出版社进行分组
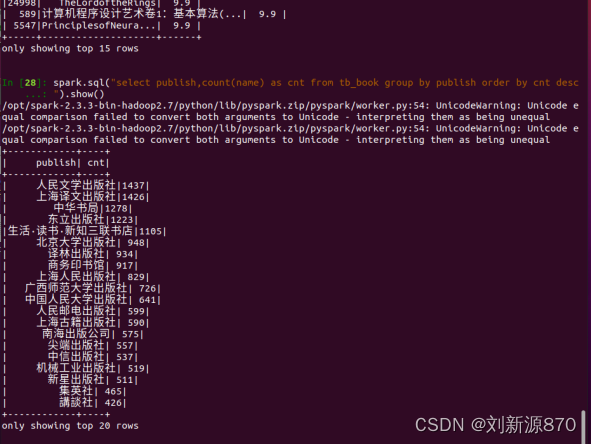
spark.sql("select publish,count(name) as cnt from tb_book group by publish order by cnt desc").show()
实验总结:
本次实验使我熟悉了Spark SQL 的使用方法,SparkSQL也是语句也是由Projection(a1,a2, a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过 程中的Result、DataSource、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。本次学习对以后sparksql的学习奠定了基础,有利于后续学习


















 2268
2268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











