



不多说,直接开始
一、安装ollama
ollama官网:https://ollama.com/
下载地址:https://ollama.com/download
打开以后注册并下载即可
找到自己的系统安装即可
二、下载模型并运行ollama
Ollama在Windows系统上默认安装在C:\Users\<username>\\AppData\Local\Programs\Ollama路径下。这里的<username>是你的Windows用户名。
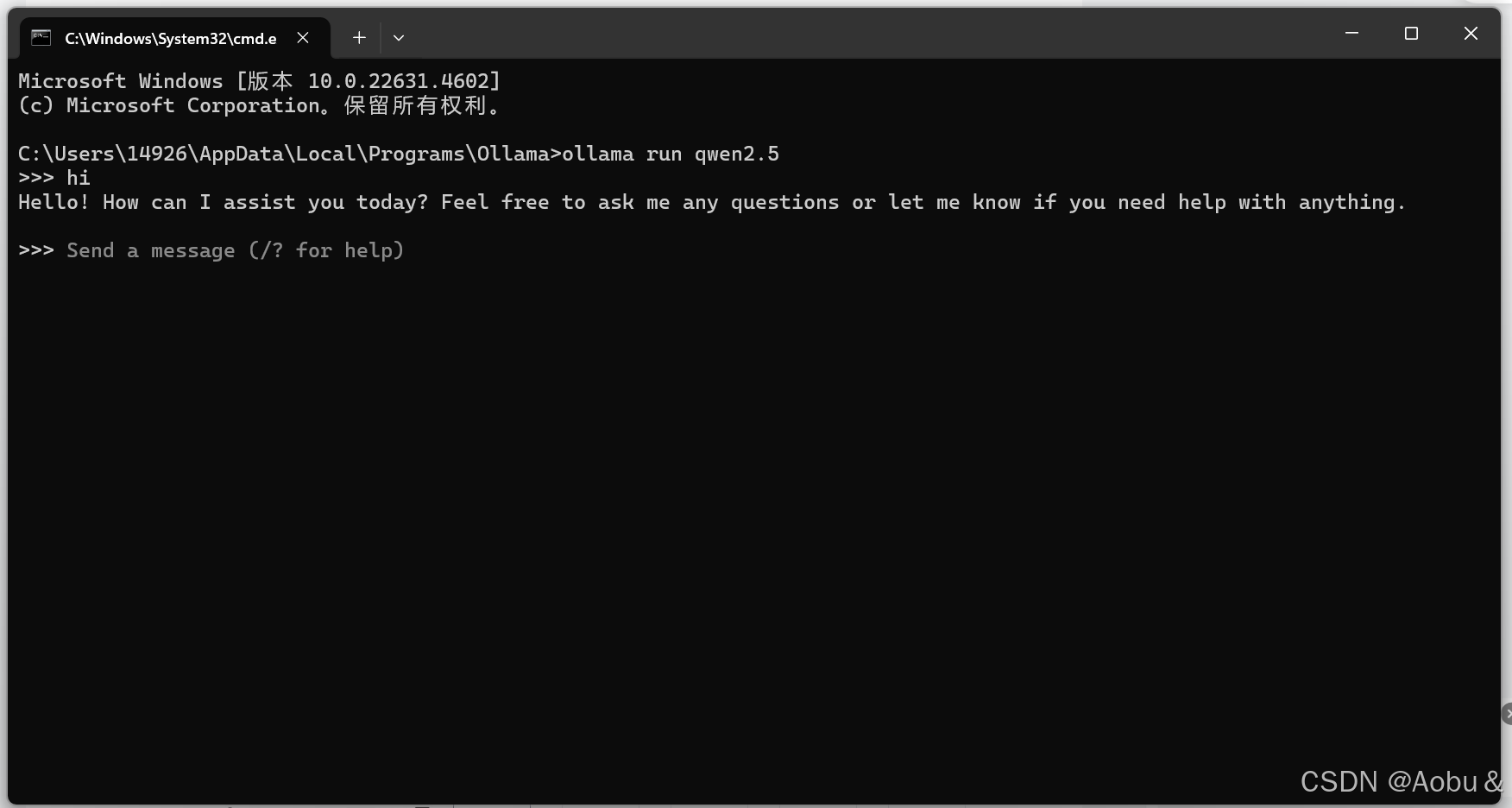
安装ollama以后,在这个路径下安装的默认路径下进入cmd,然后输入指令:ollama run qwen2.5
我是已经装好了,所以输入指令是直接运行这个模型,如果没有下载的话就是直接下载。
要下载其他的模型也可以在网站中找:https://ollama.com/library
常用的命令有:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
可以看到页面中让执行ollama run qwen2.5即可
一般来说run是用来跑模型的,但是如果本地没有这个模型的话,ollama会自动下载
PS:国内的网络问题不知道有没有解决,下载模型的时候偶尔速度很快,但是很多时候速度很慢以至于提示TLS handshake timeout,这种情况建议重启电脑或者把ollama重启一下(我下载的时候挂了梯子,下载速度还比较正常)
下载完成以后我们输入ollama list可以查下载了哪些模型

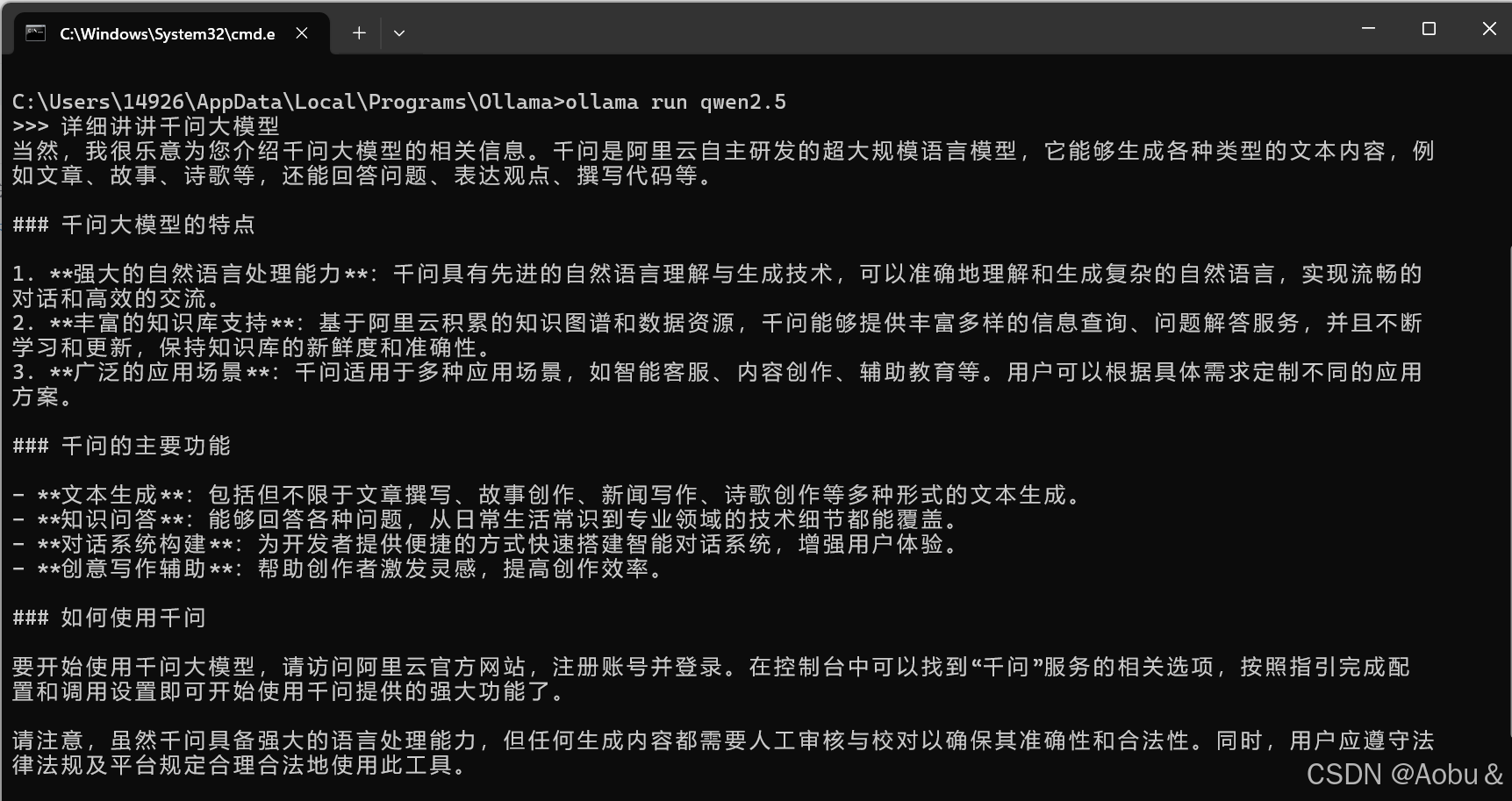
这里我们直接输入ollama run qwen2.5,就可以开始对话了
三、下载并配置AngthingLLM
AngthingLLM官网:https://useanything.com
下载链接:https://useanything.com/download
同样的选择对应的系统版本即可
在使用前,需要启动Ollama服务
执行ollama serve,ollama默认地址为:http://127.0.0.1:11434
然后双击打开AngthingLLM
我已经配置过,所以不好截图最开始的配置界面了,不过都能在设置里面找到
首先是LLM 首选项,选择ollama,URL填写默认地址,后面的模型选择qwen2.5,token填4096
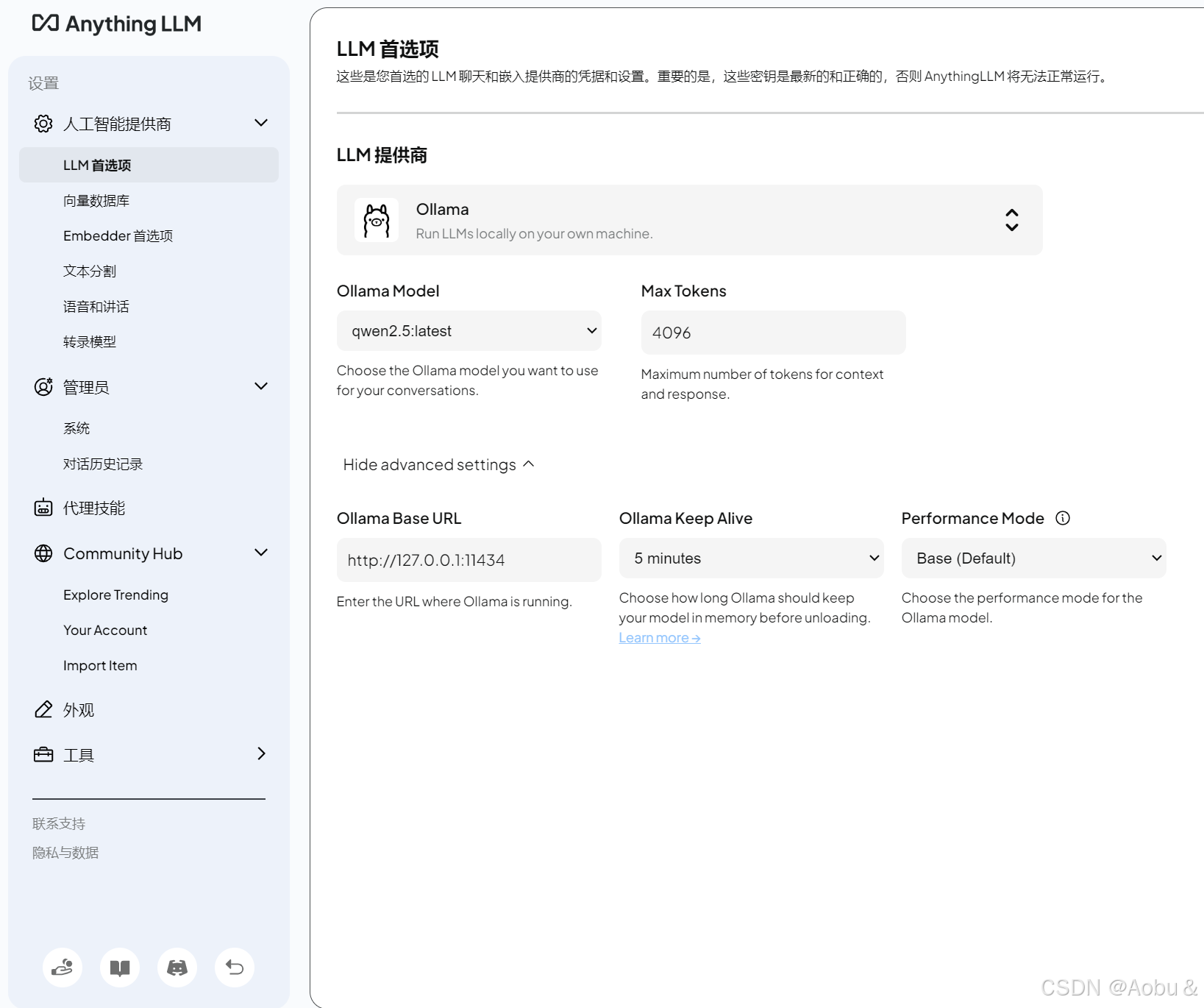
向量数据库就直接默认的LanceDB即可
此时我们新建工作区,名字就随便取,在右边就会有对话界面出现了
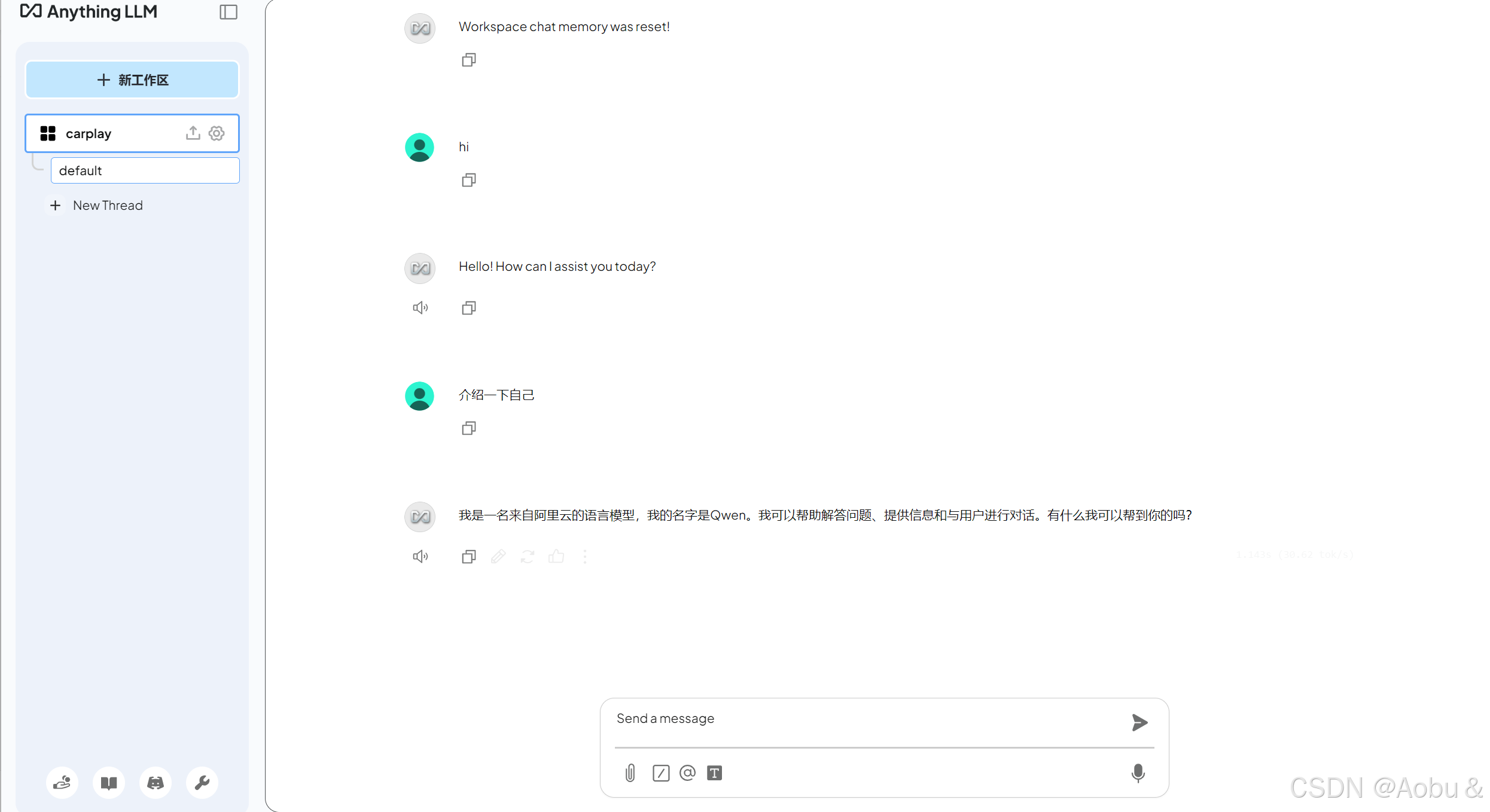
你就有了自己本地的语言模型了
接下来上传自己的数据搭建一个自己的知识库AI
点击上传键后,在My Documents中上传自己的数据文件,再Move to Workspace
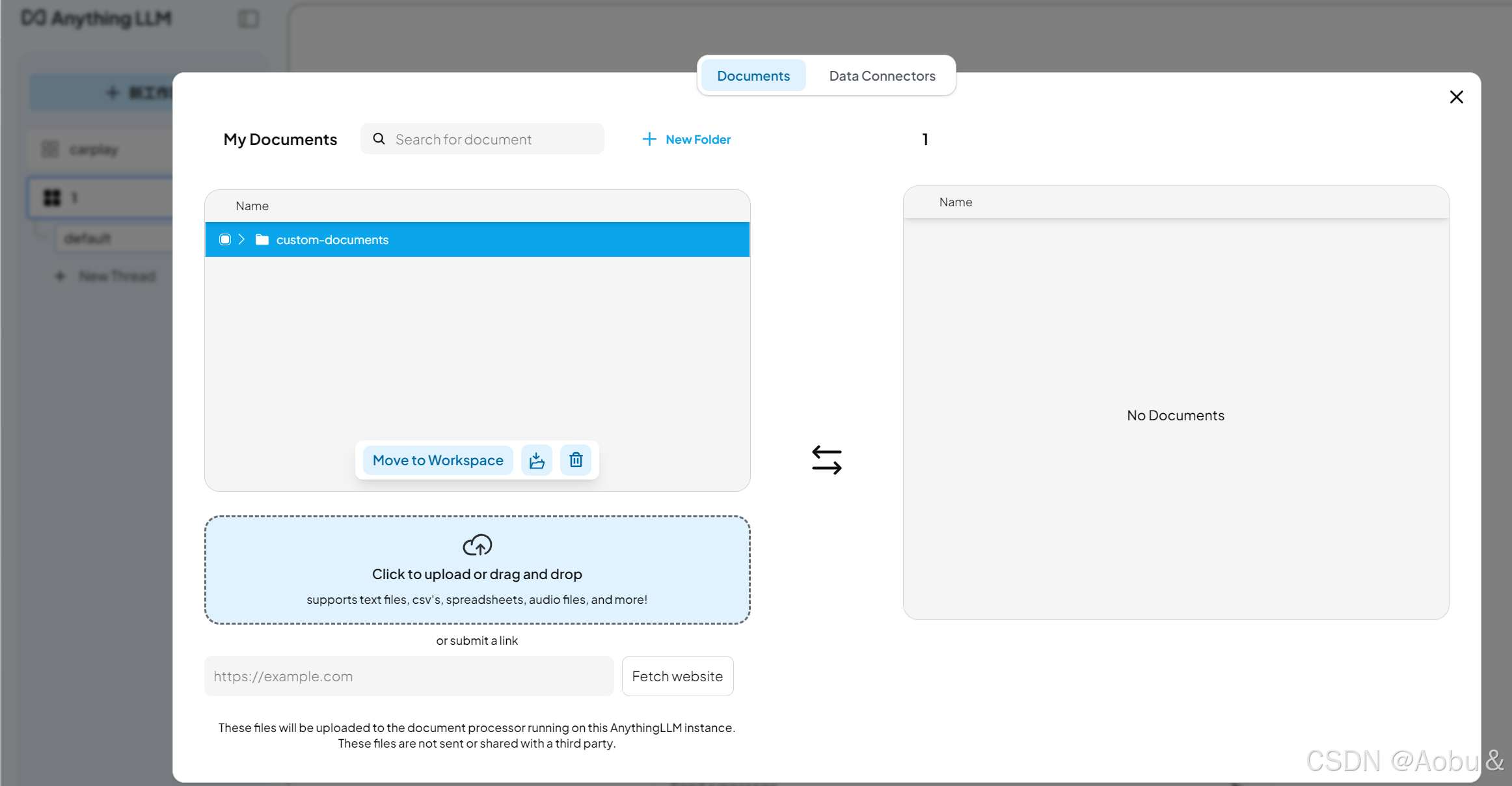
这样AI就能用知识库里的资料来回答你的问题,并在提供答案时注明所引用的信息来源。
其实整个过程并不复杂,唯一耗时的环节就是下载模型。我原本打算使用Open WebUI,但由于我的电脑上没有安装Docker,所以转而使用了AnythingLLM。等将来有时间了,我打算设置Docker环境,以便使用Open WebUI。
如果模型实在下不下来,也可以搞离线模型
Windows系统下ollama存储模型的默认路径是C:\Users\wbigo.ollama\models,一个模型库网址:魔搭社区


















 1万+
1万+





 到【灌水乐园】发言
到【灌水乐园】发言







