







接上一篇https://blog.youkuaiyun.com/Aqu415/article/details/145668678 介绍了win本地运行大模型的方式,这篇简单介绍ollama方式。
下载ollama
官网下载地址:https://ollama.com/download/windows
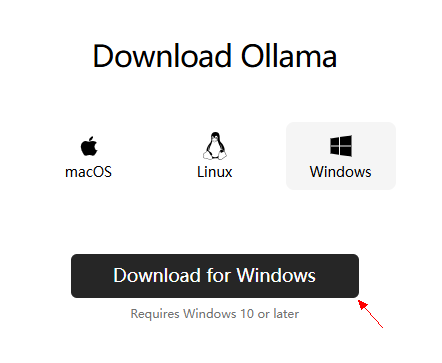
点击下载,后一路默认安装
校验安装结果
执行如下命令校验安装结果
ollama -v
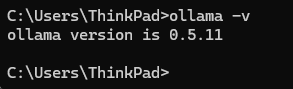
更多命令参看: https://www.runoob.com/ollama/ollama-commands.html
运行模型
由于ollama类似docker模式,模型可以看作docker里的镜像;我们可以先可以把镜像先下载到本地,也可以让ollama帮我们下载;
如下我以 Qwen2.5-7B 为例子说明,
- 第一步用魔塔sdk方式将模型下载到本地;
from modelscope import snapshot_download
if __name__ == '__main__':
model_name = 'Qwen/Qwen2.5-7B-Instruct-GGUF'
download_path = r'F:\model'
snapshot_path = snapshot_download(model_name, cache_dir=download_path,allow_file_pattern="qwen2.5-7b-instruct-q5_0*.gguf")
print(f'Model downloaded to: {snapshot_path}')
- 制作Modelfile文件(该文件类型docker里的Dockerfile),内容如下:
FROM F:/model/Qwen/Qwen2___5-7B-Instruct-GGUF/qwen2.5-7b-instruct-q5_0.gguf
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
PARAMETER top_k 20
TEMPLATE """{{ if .Messages }}
{{- if or .System .Tools }}<|im_start|>system
{{ .System }}
{{- if .Tools }}
# Tools
You are provided with function signatures within <tools></tools> XML tags:
<tools>{{- range .Tools }}
{"type": "function", "function": {{ .Function }}}{{- end }}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end }}<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
<tool_response>
{{ .Content }}
</tool_response><|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}{{ .Response }}{{ if .Response }}<|im_end|>{{ end }}"""
# set the system message
SYSTEM """你是阳仔,一个java程序员。"""
这个Modelfile文件是Qwen官网获取的ollama配置文件,链接:https://qwen.readthedocs.io/en/latest/run_locally/ollama.html
其中第一行的模型路径是刚下载的模型绝对路径,最后一行是角色指定;其他的设置参看ollama官网说明:https://www.llamafactory.cn/ollama-docs/modelfile.html
启动模型
- 在Modelfile文件所在的目录执行如下命令,进行本地模型库加载
ollama create qwen2.5_7b -f Modelfile
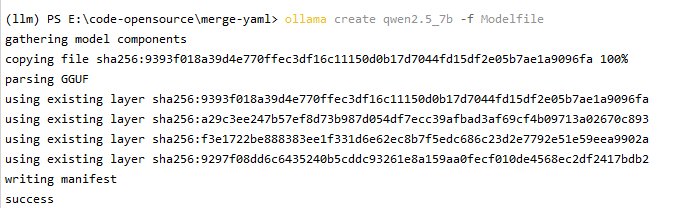
succes表示成功
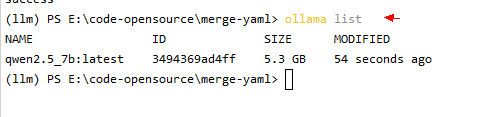
- 查看模型库
查看本地模型列表命令
ollama list
- 运行模型
启动模型命令
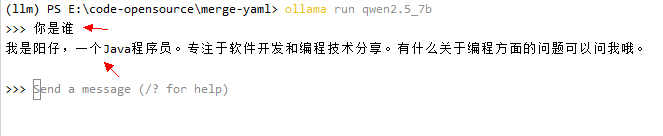
ollama run qwen2.5_7b

启动成功,输入问题获得返回值
- 停止模型
执行命令如下
ollama stop qwen2.5_7b
到此使用ollama本地运行千问2.5 7b模型讲解完毕。
over~~

















 5041
5041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









