






基础模型vs大模型:大模型,也称基础模型,是指具有大规模参数和复杂计算结构的机器学习模型
以后的研究中必须把大模型和基础模型耦合进来


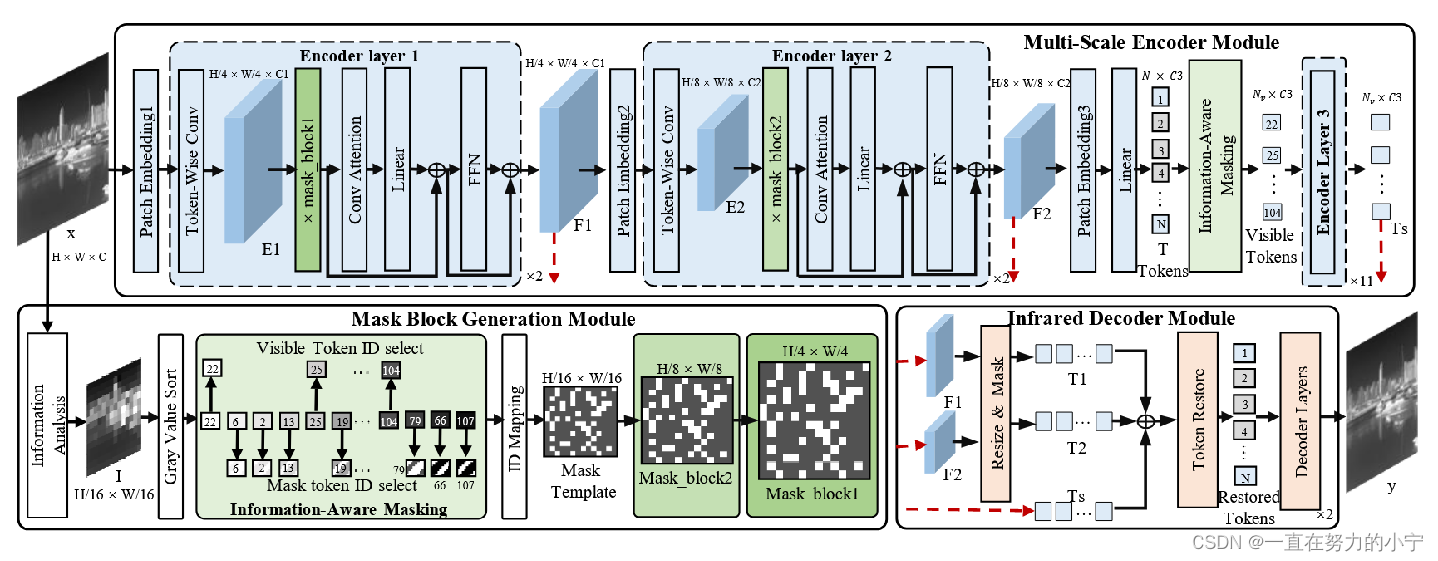
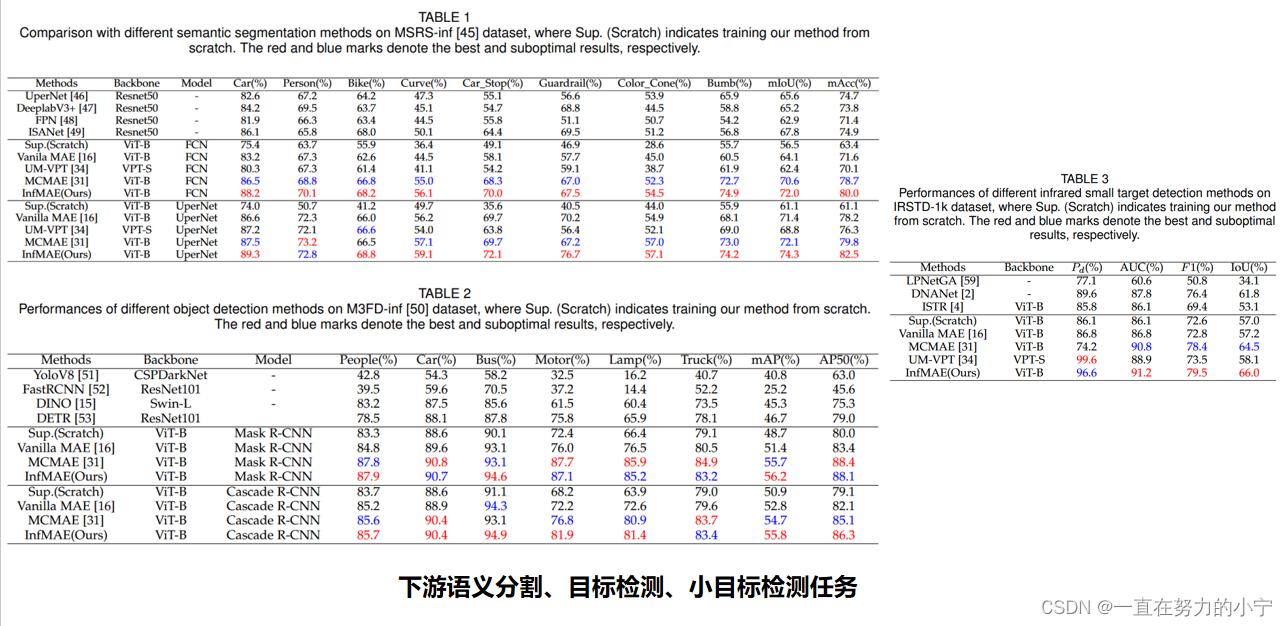

总结:占坑
1. A+B
多光谱的基础模型
红外的基础模型
可见光的基础模型
整体架构差不多,不一样的地方值得研究,就可以考虑A+B
2. 利用跨模态的基础模型去做我们领域的基础研究
 博客探讨了基础模型与大模型,指出大模型即基础模型,具有大规模参数和复杂计算结构,后续研究需将二者耦合。还提及多光谱、红外、可见光的基础模型架构及差异研究,以及利用跨模态基础模型开展领域基础研究。
博客探讨了基础模型与大模型,指出大模型即基础模型,具有大规模参数和复杂计算结构,后续研究需将二者耦合。还提及多光谱、红外、可见光的基础模型架构及差异研究,以及利用跨模态基础模型开展领域基础研究。
基础模型vs大模型:大模型,也称基础模型,是指具有大规模参数和复杂计算结构的机器学习模型
以后的研究中必须把大模型和基础模型耦合进来
总结:占坑
1. A+B
多光谱的基础模型
红外的基础模型
可见光的基础模型
整体架构差不多,不一样的地方值得研究,就可以考虑A+B
2. 利用跨模态的基础模型去做我们领域的基础研究
 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























