







♥ 创作不易,如果能帮助到你的话留下👍和⭐吧,欢迎同方向研究学者交流学习
目录

1. Motivation
论文提出了一种新的遥感图像生成模型(CRS-Diff),动机源于以下问题:
- 现有生成模型大多仅使用文本控制条件,无法稳定生成准确的遥感图像。
- 遥感图像与传统图像有显著差异(分辨率高、覆盖范围广、信息丰富),对生成模型提出了更高的要求。
- 单一控制信号(例如文本)的局限性导致生成图像细节失真,难以满足下游任务需求。
2. Contribution
论文的主要贡献包括:
- 模型创新:提出了CRS-Diff,这是首个支持多种条件(文本、元数据和图像)控制的遥感图像生成模型。 [25.1.12批:纯属扯淡]
- 控制机制:引入了一种新的多尺度特征融合机制,增强了生成过程中控制条件的引导能力。
- 实验验证:在单一条件和多种条件下,CRS-Diff生成的遥感图像在质量和一致性上均优于现有方法。此外,该模型可作为下游任务的数据引擎,用于生成高质量训练数据。 [25.1.12批:扯淡]
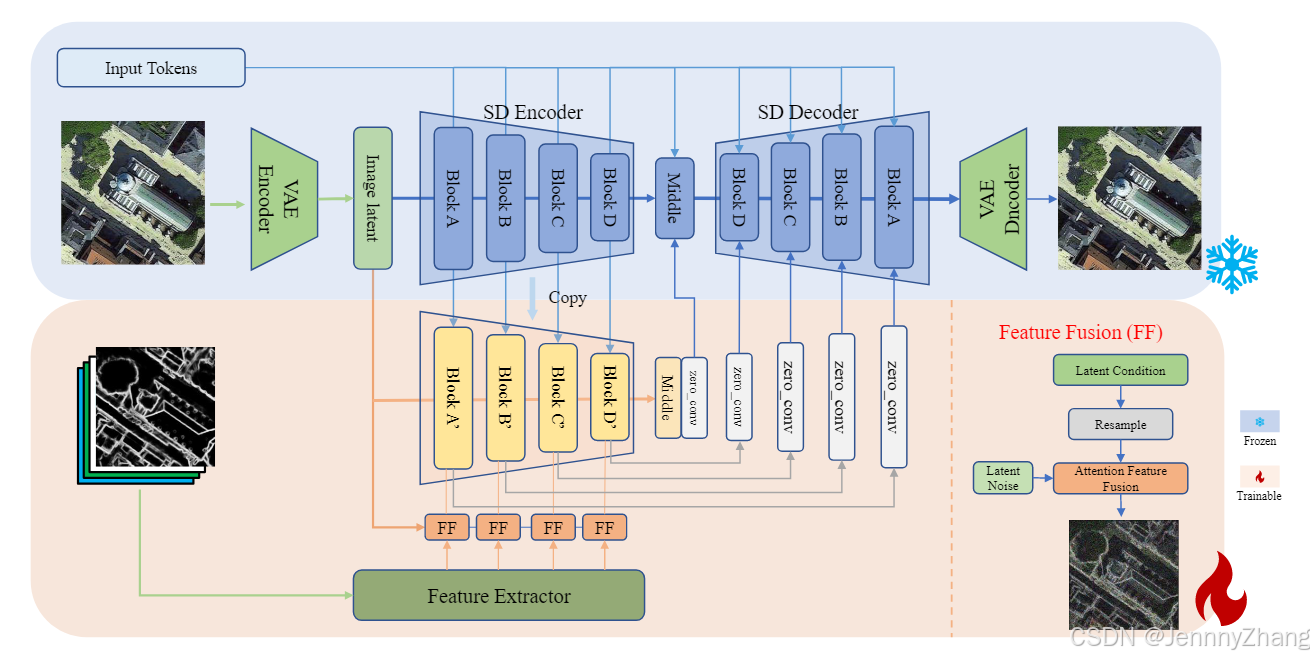
3. Method
- 模型架构:CRS-Diff基于Stable Diffusion框架,并通过集成ControlNet扩展了控制能力。
- 多条件输入:
- 文本条件:使用CLIP模型对文本描述进行编码。
- 图像条件:包括语义分割、道路图、草图等,通过特征提取模块实现多条件特征注入。
- 元数据条件:将时间和空间信息编码为固定长度的向量,并与其他条件融合。
- 训练策略:
- 阶段1:使用文本-图像对数据训练基础生成模型。
- 阶段2:添加控制模块,训练多条件生成能力。
3.1. 引入扩散模型与多条件控制
这部分描述了作者将扩散模型引入遥感图像生成领域的总体目标与方法:
- 目标:提高遥感图像生成的通用能力,生成更真实的遥感图像。
- 创新点:
- 引入多条件控制机制,结合文本、图像和多维信息,指导生成过程。
- 模型结构分为两步:
- 使用文本-图像对训练生成模型的权重,基于Stable Diffusion(SD)框架。
- 通过条件控制网络,融合图像和文本条件实现复合控制。
3.2. 生成流程的核心部分
A. 文本到图像生成
-
流程概述:
- 使用一个冻结的VAE编码器和解码器,将图像x映射到潜在空间表示z。
- 通过CLIP模型对文本描述进行编码,指导扩散过程中的去噪。
- 使用DDIM采样算法加速生成过程。
-
损失函数:

-
分类器自由引导机制(CFG):

-
模型优化:
- 使用预训练的CLIP模型(ViT-L-14)对遥感图像数据集(RSICD)进行微调。
- 训练时仅更新去噪模型的参数(ϵθ),其他模块参数保持不变。
B. 图像解耦
- 目的:通过对图像的特征解耦生成大规模条件数据集,用于模型训练。
- 引入九种条件:
- Caption:直接使用图像的描述性文本(如RSICD数据集)或基于类别生成描述。
- HED:提取边缘和目标边界信息。
- MLSD:检测直线段以捕捉遥感图像中的结构信息。
- Depthmap:估计图像深度,捕获图像布局和语义。
- Sketch:提取草图,关注局部细节。
- Road Map:提取道路信息,生成单通道道路图。
- Segmentation Mask:生成语义分割掩码。
- Content:使用CLIP模型编码图像内容,生成全局嵌入。
- Metadata:包含时间、空间等元数据(如经纬度、云量等),编码为序列嵌入。
3.3. 多条件融合
- 概述:通过附加条件控制模块,将分解的图像条件与潜在特征融合,实现多条件信息注入。
- 条件类型:
- 文本条件:包含描述、内容和元数据。
- 图像条件:包含Sketch、Segmentation Mask、Depthmap等。
- 元数据:通过多层感知机(MLP)编码。
A. 文本条件融合
B. 图像条件融合
3.4. 训练策略
第一阶段:基础模型训练
- 使用Stable Diffusion (SD) 1.5版本的预训练权重,在文本-图像的遥感数据集上进行训练。
- 目标是开发一个高精度的扩散模型,作为ControlNet的骨干结构,能够在去噪过程中有效引导生成。
第二阶段:ControlNet训练
- 在SD模型的基础上,进一步训练ControlNet以支持多条件的联合控制生成。
- 强调模型需要在多种条件的组合下进行训练,以增强其对多维条件的适应性。
条件控制的实现
- 独立条件的丢弃概率:
- 在训练中,每种文本或图像控制条件以0.5的独立概率被随机忽略。
- 这种方法是基于分类器自由引导机制(Classifier-free Guidance)的思想,让模型在缺失某些条件时依然能有效生成图像。
- 联合条件的丢弃概率:
- 所有条件以0.1的联合概率被忽略。
- 通过这种设计,模型能够学习不同条件组合下的生成能力,从而更灵活地应对多样化的输入。
条件组合的训练机制
- 多样性学习:
- 每个条件元素都被视为独立的引导条件(bootstrap condition)。
- 在训练过程中,单个或多个条件会以一定概率被忽略,让模型学习更多种类的条件组合。
- 这种机制使模型能够:
- 在条件有限甚至缺失的情况下依然生成高质量图像。
- 提升对多条件联合控制的生成适应性。
- 动态调整丢弃概率:
- 根据实验结果,调整某些条件的丢弃概率,以优化生成性能。
3.5. 总结
- 本文设计的CRS-Diff模型通过两阶段训练和多条件控制,实现了对遥感图像生成的精细控制。
- 其创新点在于:
- 将文本、图像和元数据条件有机结合。
- 通过解耦特征和特征融合,增强生成模型的灵活性和生成质量。
- CRS-Diff为遥感图像生成及相关下游任务(如分割、道路提取)提供了高质量的数据支持。
4. Experiment
- 数据集:使用RSICD、fMoW和Million-AID等数据集。
- 评估指标:
- 文本到图像生成:采用Inception Score (IS)、Frechet Inception Distance (FID)等指标评估生成图像质量。
- 条件生成:使用SSIM、mIoU和CLIP分数评估条件约束能力。
- 实验结果:
- 相较于现有方法,CRS-Diff在生成质量和控制能力上表现更优。
- 在多条件控制生成中,CRS-Diff能够融合多个控制信号生成精确的图像。
- 在下游任务(如道路检测)中,使用CRS-Diff生成的数据能够有效提升模型性能。
A. 数据集
CRS-Diff模型的训练使用了以下数据集:
- RSICD:
- 用于遥感图像的图像描述任务。
- 包含10,921张航拍图像(224×224分辨率),每张图像都有对应的自然语言描述。
- fMoW:
- 大规模遥感数据集,提供每张图像的时空和类别信息。
- 使用了110,000张RGB图像(224×224分辨率)以及相关元数据来训练多条件控制模型。
- Million-AID:
- 遥感场景分类基准数据集。
- 包含数百万样本,分为51个场景类别,每类图像数量在2,000到45,000之间。
B. 实现细节
- 第一阶段:基础模型训练
- 数据集:RSICD。
- 训练配置:
- 训练10个epoch。
- 使用U-Net和AdamW优化器,学习率为1×10⁻⁵。
- 输入图像分辨率调整为512×512,模型参数量约为0.9亿。
- 采样:使用DDIM采样算法,设置100个时间步长,分类器自由引导比例为7.5。
- 第二阶段:条件控制网络训练
- 数据集:fMoW和Million-AID,共生成200,000个文本-图像对。
- 条件生成:通过标注网络将图像分解为多种条件(例如道路图、MLSD、元数据等)。
- 训练配置:
- 微调条件控制网络5个epoch。
- 使用AdamW优化器,学习率为1×10⁻⁴。
- 输入图像及条件图像均调整为512×512分辨率。
- 硬件:实验在NVIDIA GeForce RTX 4090和RTX A100 GPU上进行,批量大小为8。
C. 评估指标
- 文本到图像生成评估:
- 指标:
- Inception Score (IS):衡量生成图像的多样性和质量。
- Fréchet Inception Distance (FID):评估生成图像与真实图像的相似性。
- CLIP Score:基于CLIP模型,评估图像与文本描述的一致性。
- Overall Accuracy (OA):零样本分类精度,衡量生成数据的泛化能力。
- 计算公式:
- IS:使用KL散度衡量条件分布与边际分布之间的差异。
- FID:基于生成和真实图像特征分布的均值和协方差矩阵计算。
- OA:训练分类器,并在未见过的类别上测试准确性。
- 指标:
- 条件图像生成评估:
- 指标:
- SSIM:衡量生成图像与条件图像的相似性(结构保真)。
- mIoU:用于分割条件下,评估预测区域与真实区域的重叠程度。
- CLIP Score:评估条件图像与语义的一致性。
- 计算公式:
- SSIM:基于图像的均值、方差和协方差。
- mIoU:计算预测区域与真实区域的交并比。
- 指标:
D. 比较与分析
文本到图像生成
- 定性分析:
- CRS-Diff生成的图像在形状、数量、颜色和光照等方面表现优越。
- 能准确反映复杂描述的语义信息(如“一个方形草坪和半圆形草坪由森林环绕”)。
- 定量分析:
- CRS-Diff在零样本分类精度(OA)、FID和CLIP评分等指标上超过了现有方法。
- 在IS指标上接近SOTA,但略低于最佳结果。
单一条件图像生成
- 定性分析:
- 对于HED和Sketch条件,CRS-Diff能够通过边界和轮廓信息实现直观的图像控制。
- 道路图和分割掩码条件提供了丰富的语义信息。
- CRS-Diff生成的图像具有清晰的纹理细节和连贯的场景关系。
- 定量分析:
- 与ControlNet和Uni-ControlNet相比,CRS-Diff在SSIM、mIoU和FID指标上表现最佳。
多条件图像生成
- 结果展示:
- 多条件生成的图像具有高真实感和多样性。
- 利用文本引导,模型在生成能力、可控性和细节保真度上表现出色。
- 挑战:
- 遥感图像对条件冲突的容忍度较低,轻微失真可能使生成结果毫无意义。
E. 消融实验(Ablation Analysis)
多条件控制网络结构改进与控制信息注入方式
- 实验目标:评估以下两种改动对生成质量与控制效果的影响:
- 替换骨干模型(ReB)。
- 改变特征融合方法(FF)。
- 结果总结:
- 预训练的骨干模型和高效的特征融合方法显著提升了生成效果。
- 模型能够生成更高信息密度的遥感图像,并实现多种控制信息的融合,从而增强控制生成能力。
CLIP模型版本与训练策略的影响
- 实验设置:
- 使用两个版本的CLIP文本编码器(ViT-B-32和ViT-L-14)对文本条件进行编码。
- 比较不同参数量的模型和特定微调策略的效果。
- 结果总结:
- 参数量更大的模型生成能力更强。
- 在遥感图像上微调的CLIP模型显著提高了生成性能。
额外图像控制条件的作用
- 实验目标:评估增加图像控制条件(如内容图像)对生成质量的影响。
- 结果总结:
- 增加图像控制条件对生成质量(FID和CLIP分数)有积极影响。
- 然而,图像控制条件的引入会减少生成图像的多样性(反映在IS分数上)。
CLIP图像编码器版本的影响
- 实验设置:比较四种CLIP图像编码器(基于ViT和ResNet架构)的性能。
- 结果总结:
- ViT架构的编码器在FID和CLIP评分上表现最佳。
- ViT-L-14模型在特征提取能力上具有显著优势,相较于ResNet架构的编码器表现更优。
F. 下游道路检测任务的应用
- 验证生成的遥感图像在下游任务(如道路提取)中的应用价值。
- 确保生成的图像与控制标签(如道路图)的相关性足够高,同时能为下游任务提供有效的训练数据支持。
实验方法
- 将合成数据集(由CRS-Diff生成的图像)与真实数据集结合,加入SGCN(Separable Graph Convolutional Network)的训练集。
- 在官方测试集上评估道路检测性能。
结果总结
- 单独使用合成数据集:
- 模拟真实图像的性能接近真实训练数据集。
- 合成数据集与真实数据集结合:
- 显著提高了道路检测的性能,特别是在处理复杂道路网络时表现更优(如连续性与完整性)。
- 图示分析:
- 在对比的可视化结果中,红框标注的区域显示,使用扩展数据集(真实+合成)训练的模型在复杂场景下更具有鲁棒性和广泛适应性。
综合结论
- 结合真实和合成数据集不仅增加了训练数据量,还引入了更广泛的场景,显著提高了下游任务的性能。
- CRS-Diff生成的图像为复杂道路结构的处理提供了更强的支持,展现出在数据扩展和增强下游任务性能方面的巨大潜力。
5. Future Work
论文提出未来工作的方向:
- 进一步探索如何优化控制机制,以支持更多复杂的条件。
- 在更多遥感领域应用CRS-Diff,例如灾害监测和农业评估。
- 提高模型的生成效率,降低对计算资源的依赖。


















 4548
4548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









