






摘要
这个星期主要学习了现代卷积神经网络和循环神经网络,下星期考试较多,主要准备期末考试。
This week mainly studied modern convolutional neural networks and recurrent neural networks, mainly preparing for the final exam.
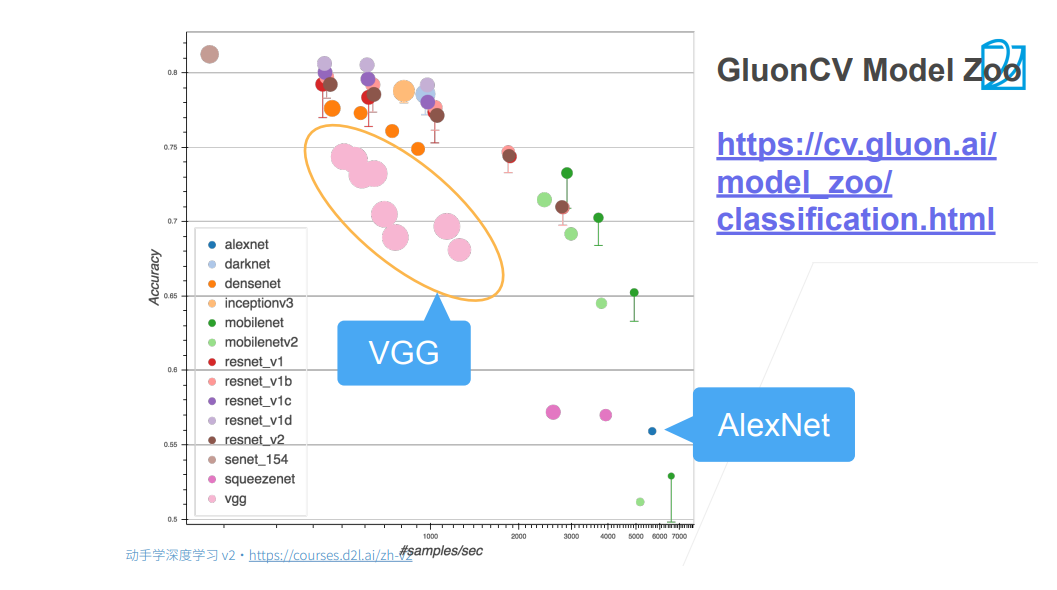
使用块的网络VGG
VGG网络
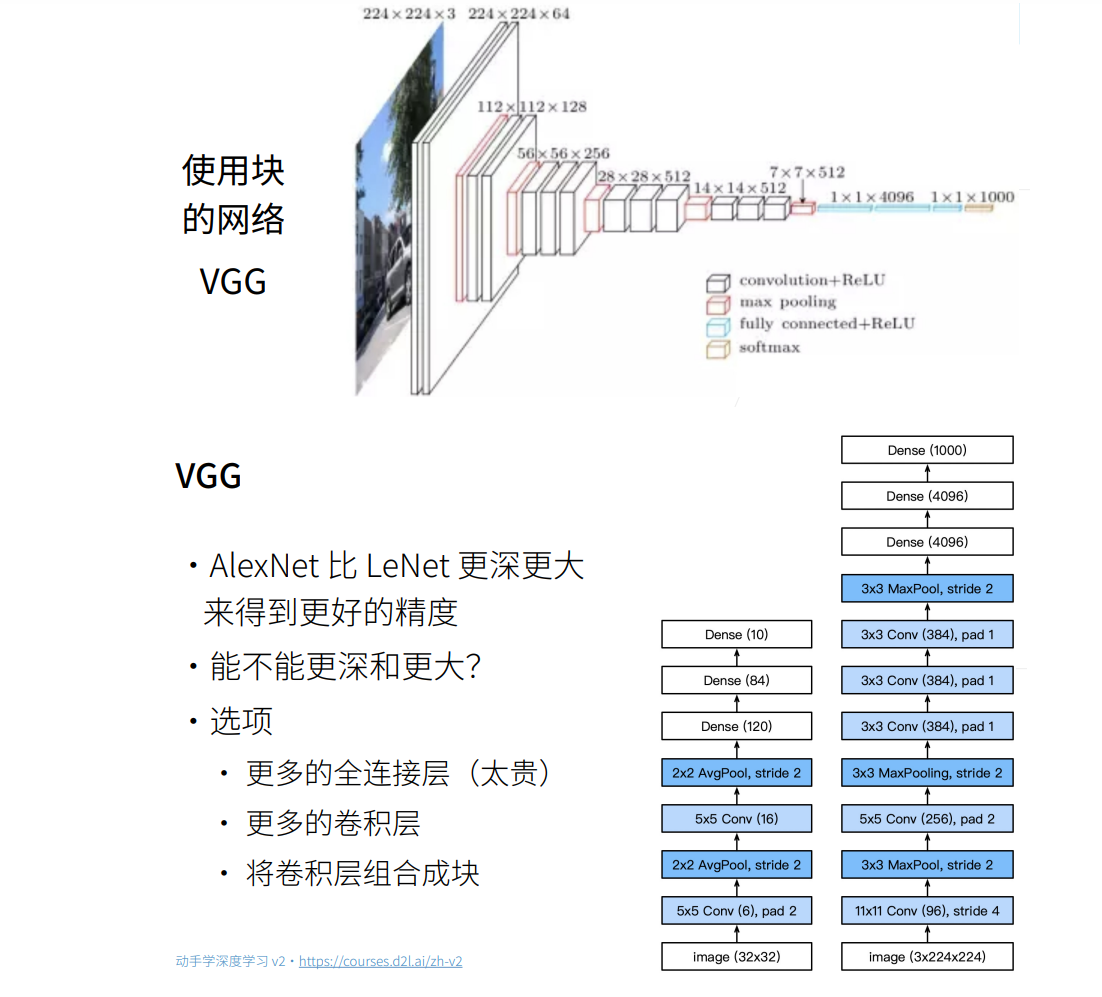
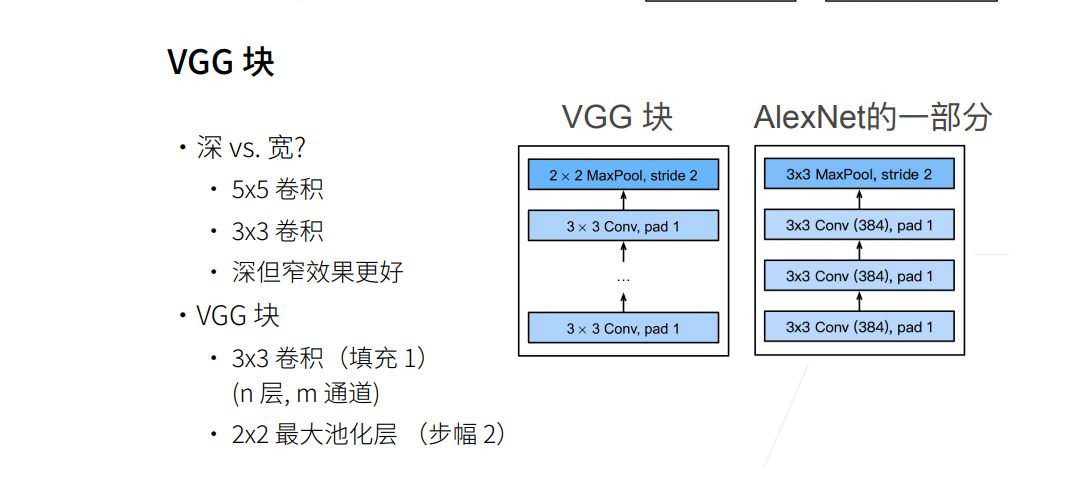
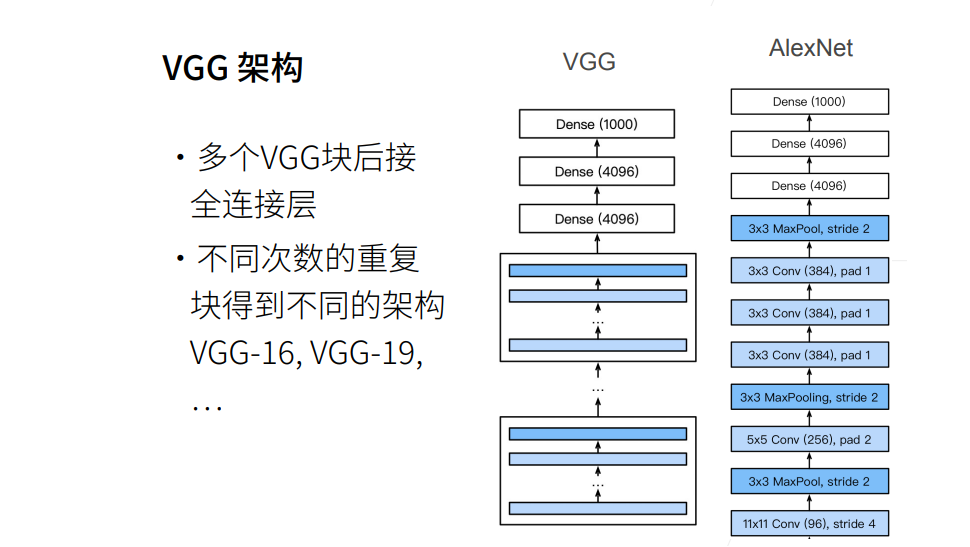

实现
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs,in_channels,out_channels): # 卷积层个数、输入通道数、输出通道数
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers) # *layers表示把列表里面的元素按顺序作为参数输入函数
conv_arch = ((1,64),(1,128),(2,256),(2,512),(2,512)) # 第一个参数为几层卷积,第二个参数为输出通道数
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs,in_channels,out_channels))
in_channels = out_channels
return nn.Sequential(*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096),nn.ReLU(),
nn.Dropout(0.5), nn.Linear(4096,4096),nn.ReLU(),
nn.Dropout(0.5), nn.Linear(4096,10))
net = vgg(conv_arch)
# 观察每个层输出的形状
X = torch.randn(size=(1,1,224,224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t', X.shape) # VGG使得高宽减半,通道数加倍
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
# 由于VGG-11比AlexNet计算量更大,因此构建了一个通道数较少的网络
ratio = 4
small_conv_arch = [(pair[0], pair[1]//ratio) for pair in conv_arch] # 所有输出通道除以4
net = vgg(small_conv_arch)
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
d2l.train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())
loss 0.179, train acc 0.934, test acc 0.915
593.8 examples/sec on cuda:0
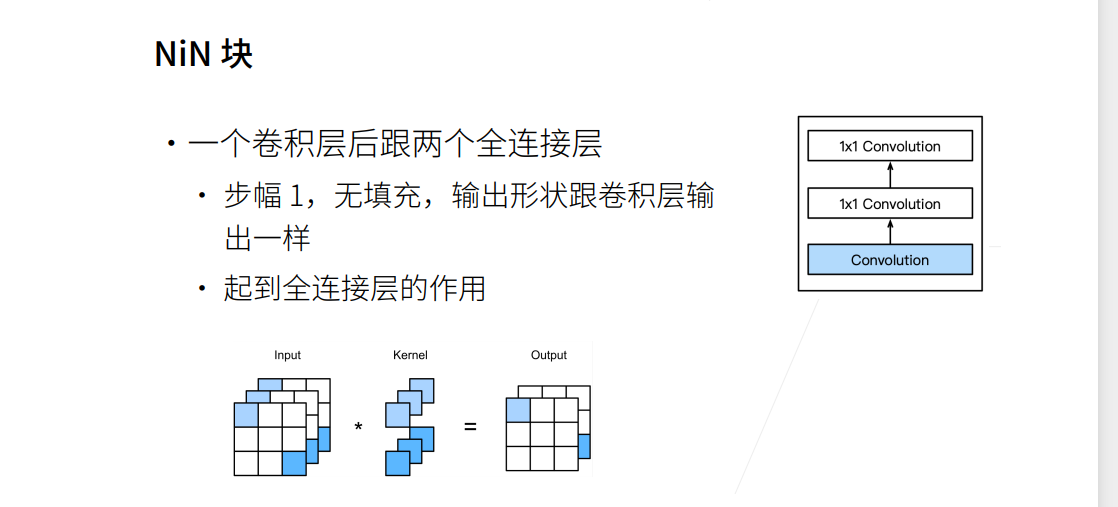
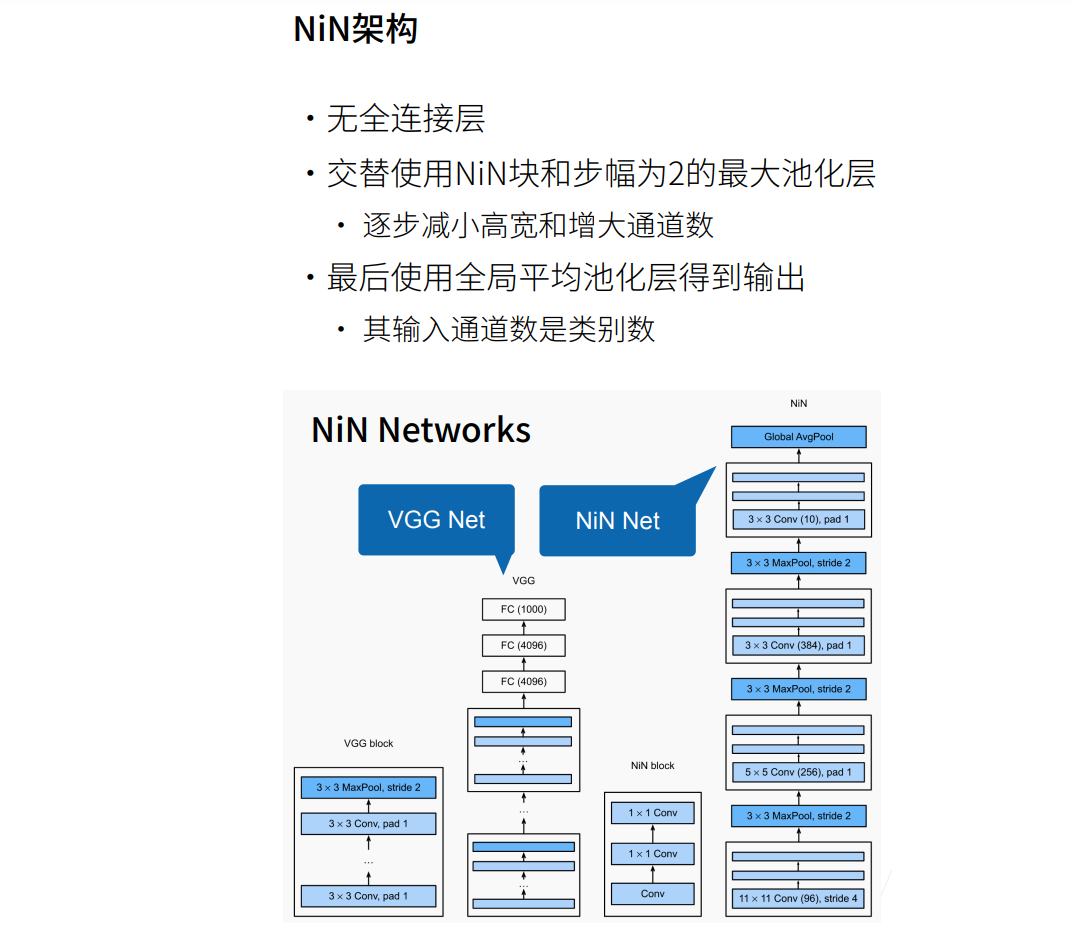
网络中的网络NiN

总结
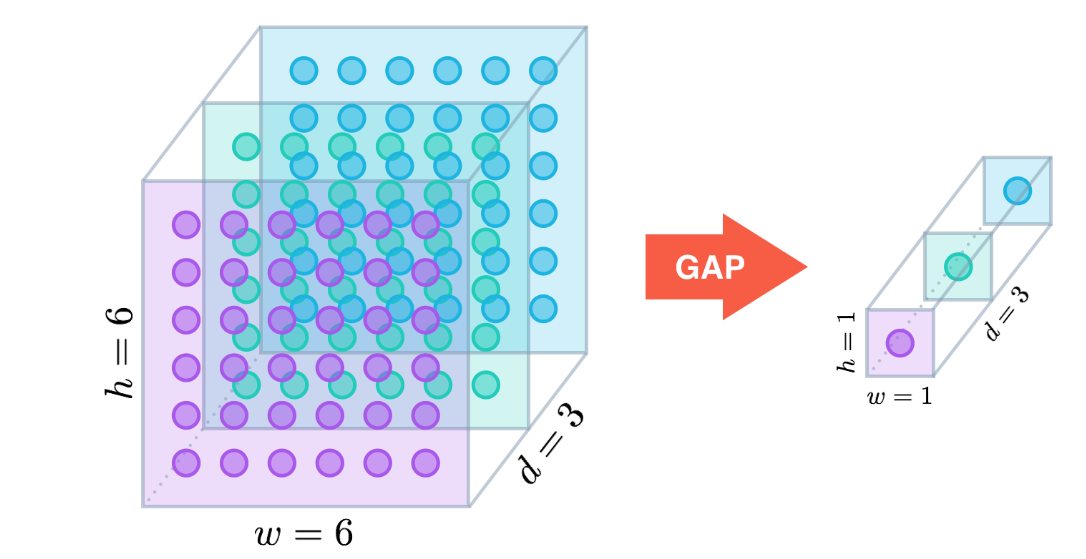
① 在全局平均池化层(GAP)被提出之前,常用的方式是将feature map直接拉平成一维向量,但是GAP不同,是将每个通道的二维图像做平均,最后也就是每个通道对应一个均值。
② 假设卷积层的最后输出是h × w × d 的三维特征图,具体大小为6 × 6 × 3,经过GAP转换后,变成了大小为 1 × 1 × 3 的输出值,也就是每一层 h × w 会被平均化成一个值,如下图所示。
③ GPA优势:
抑制过拟合。直接拉平做全连接层的方式依然保留了大量的空间信息,假设feature map是32个通道的10 * 10图像,那么拉平就得到了32 * 10 * 10的向量,如果是最后一层是对应两类标签,那么这一层就需要3200 * 2的权重矩阵,而GAP不同,将空间上的信息直接用均值代替,32个通道GAP之后得到的向量都是32的向量,那么最后一层只需要32 * 2的权重矩阵。相比之下GAP网络参数会更少,而全连接更容易在大量保留下来的空间信息上面过拟合。
输入尺寸更加灵活。在第1点的举例里面可以看到feature map经过GAP后的神经网络参数不再与输入图像尺寸的大小有关,也就是输入图像的长宽可以不固定。

实现
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, strides,padding),
nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(), nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU())
net = nn.Sequential(nin_block(1,96,kernel_size=11,strides=4,padding=0),
nn.MaxPool2d(3,stride=2),
nin_block(96,256,kernel_size=5,strides=1,padding=2),
nn.MaxPool2d(3,stride=2),
nin_block(256,384,kernel_size=3,strides=1,padding=1),
nn.MaxPool2d(3,stride=2),nn.Dropout(0.5),
nin_block(384,10,kernel_size=3,strides=1,padding=1),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
# 查看每个块的输出形状
X = torch.rand(size=(1,1,224,224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])
# 训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.341, train acc 0.874, test acc 0.834
1627.8 examples/sec on cuda:0
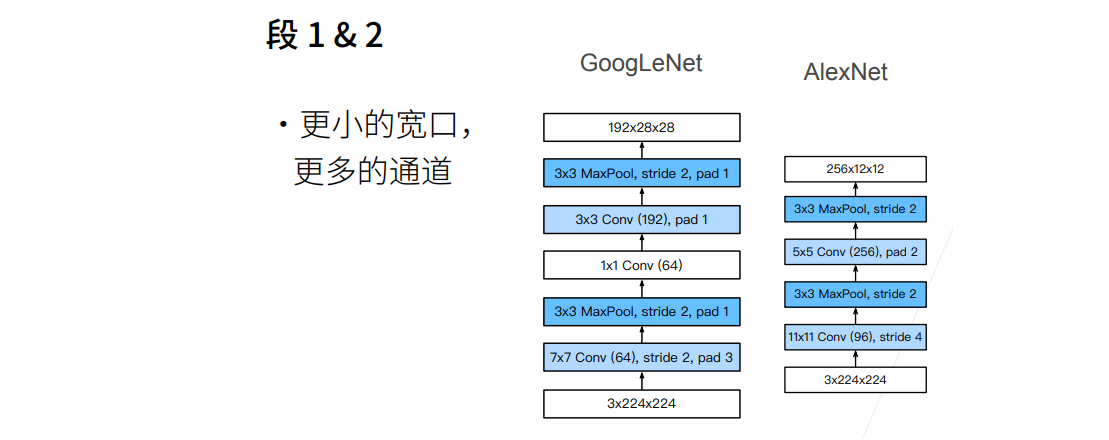
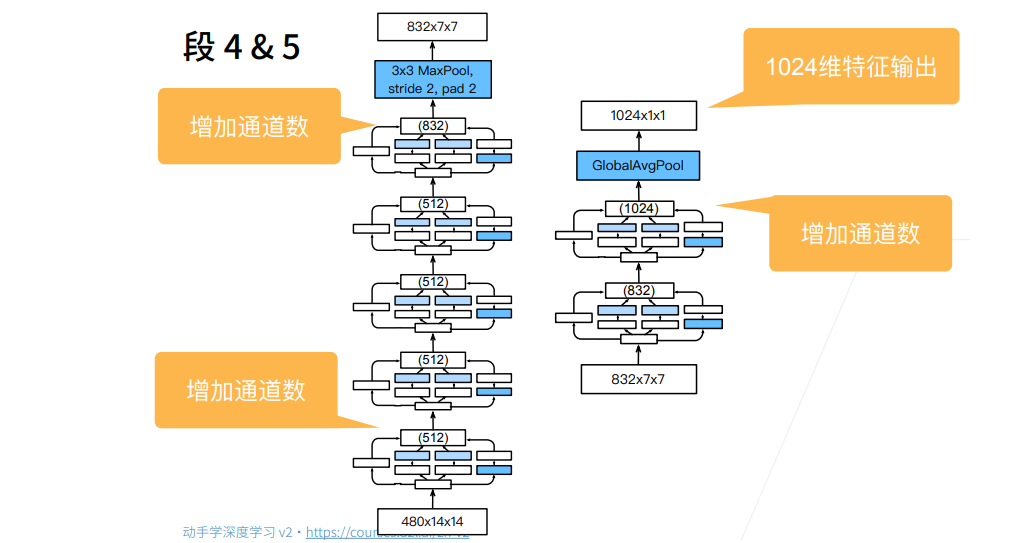
合并行连接的网络GoogLeNet
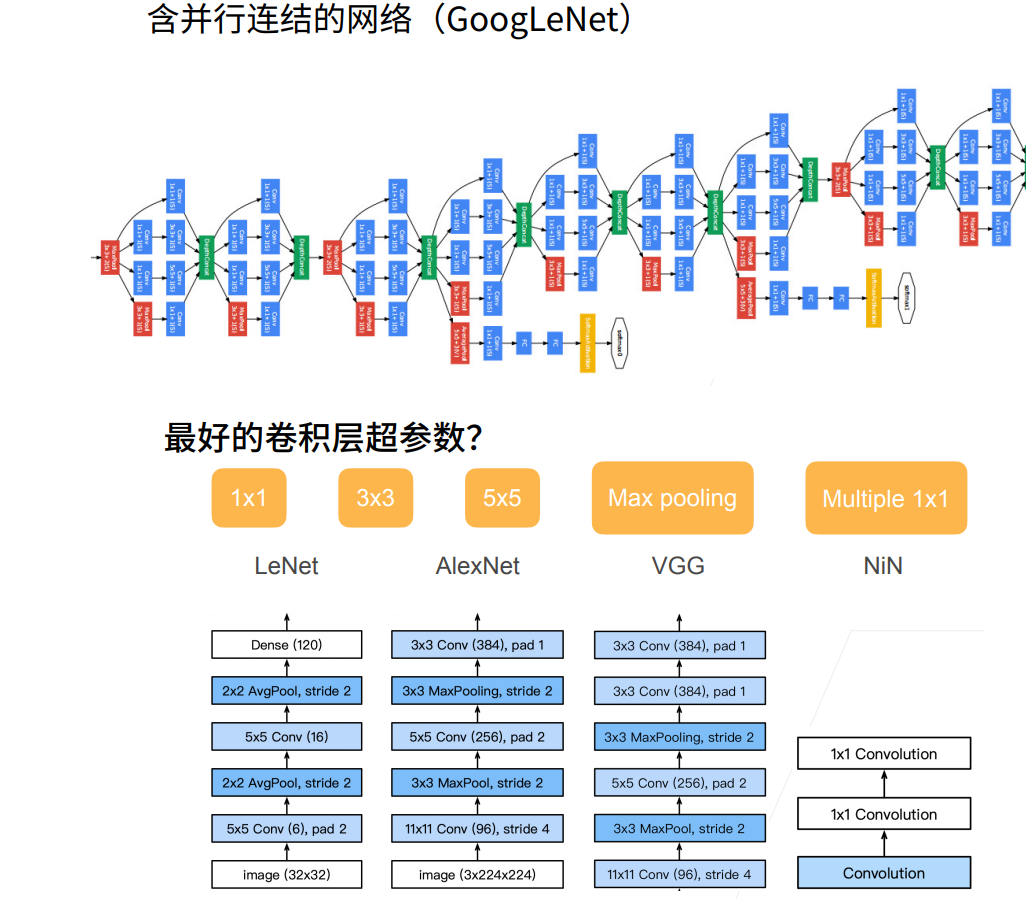
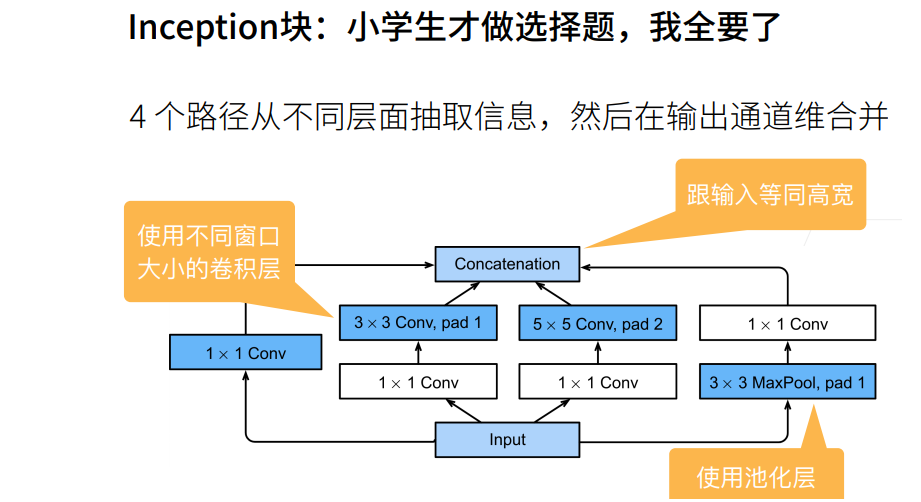
① 白色的卷积用来改变通道数,蓝色的卷积用来抽取信息。
② 最左边一条1X1卷积是用来抽取通道信息,其他的3X3卷积用来抽取空间信息。
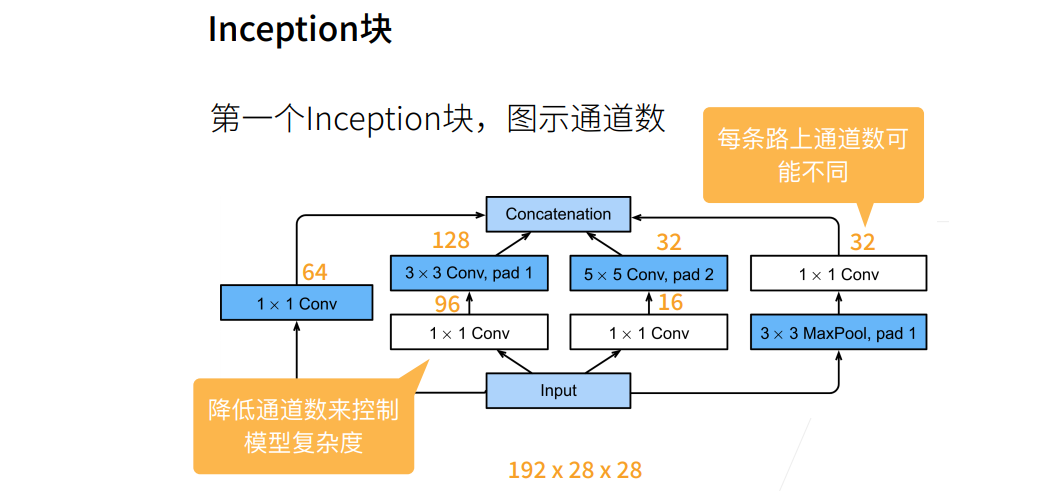
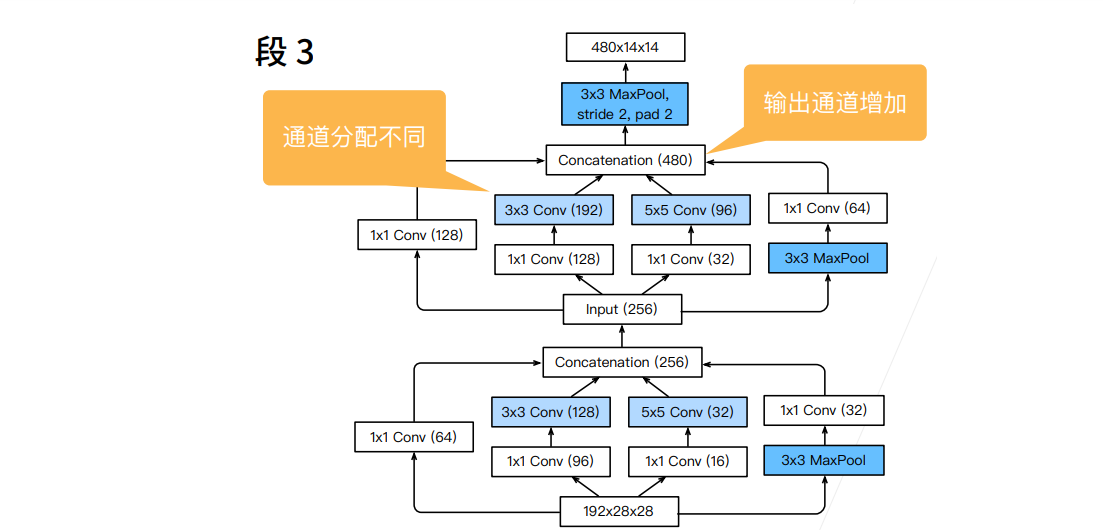
① 输出相同的通道数,5X5比3X3的卷积层参数个数多,3X3比1X1卷积层的参数个数多。
② Inception块使用了大量1X1卷积层,使得参数相对单3X3、5X5卷积层更少。

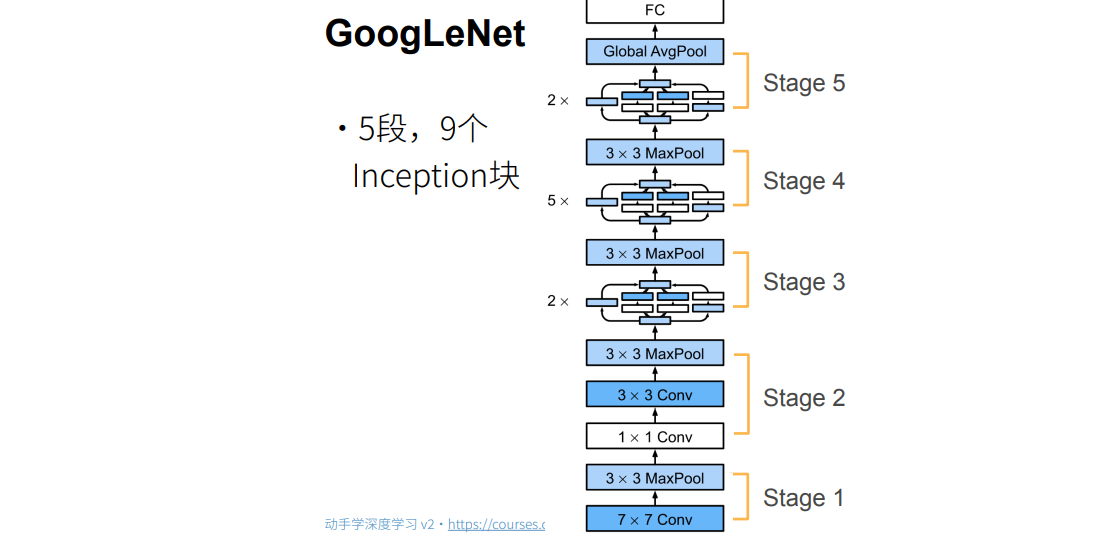
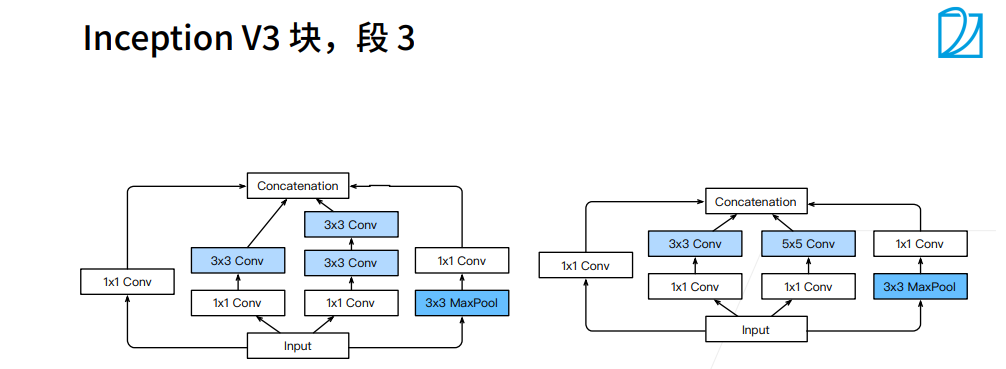
① 1X7卷积层是看行一下空间信息,列信息不看,7X1是列看一下空间信息,行信息不看。
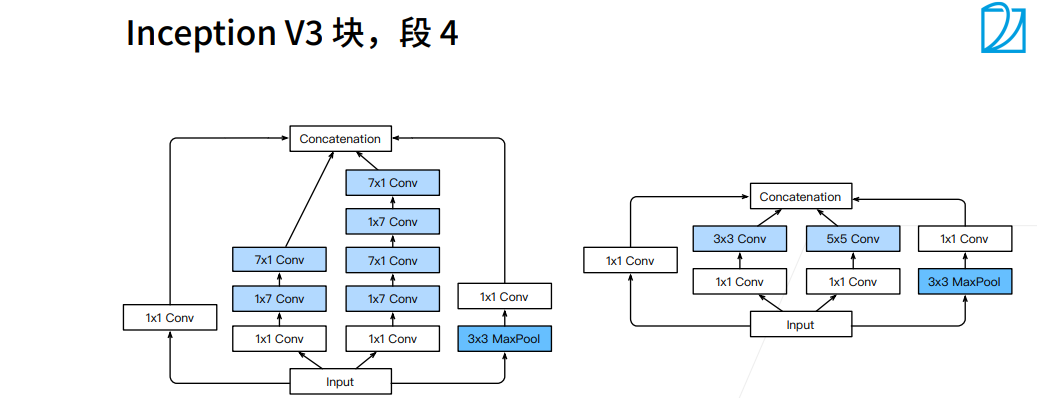
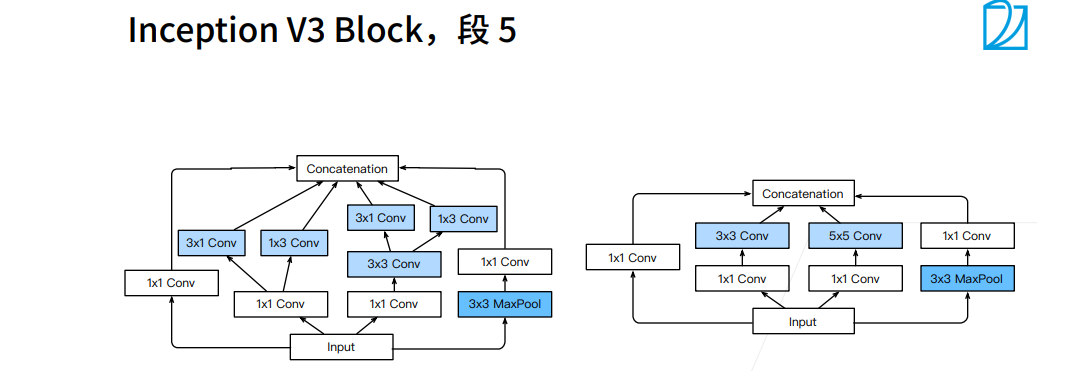
① 圈的大小表示耗内存的大小。

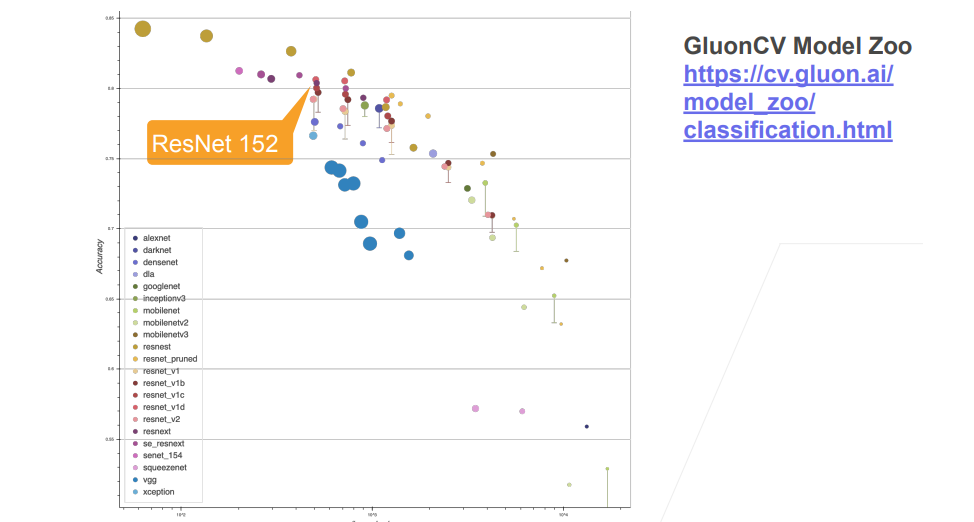
残差神经网络ResNet
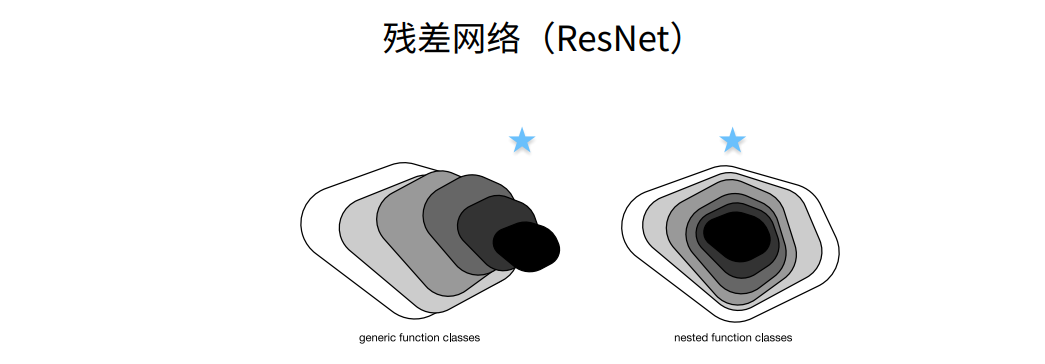
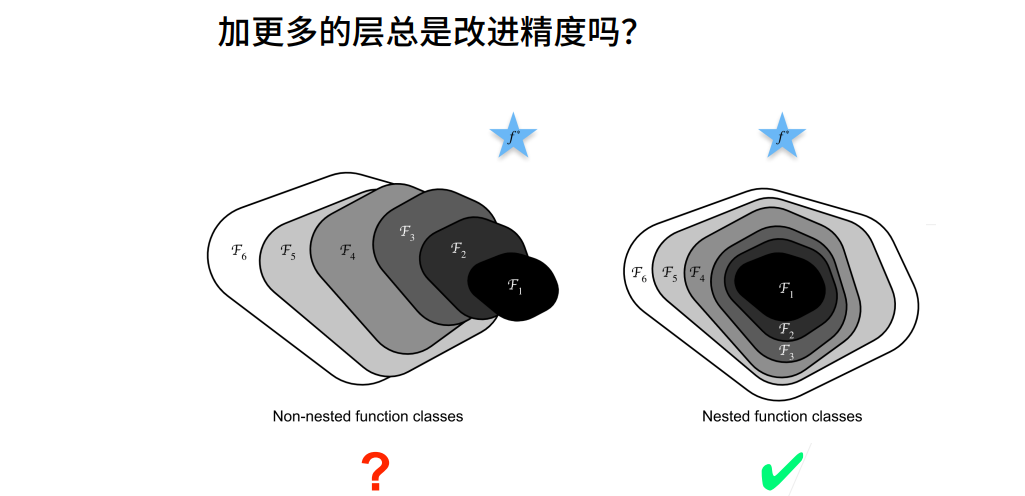
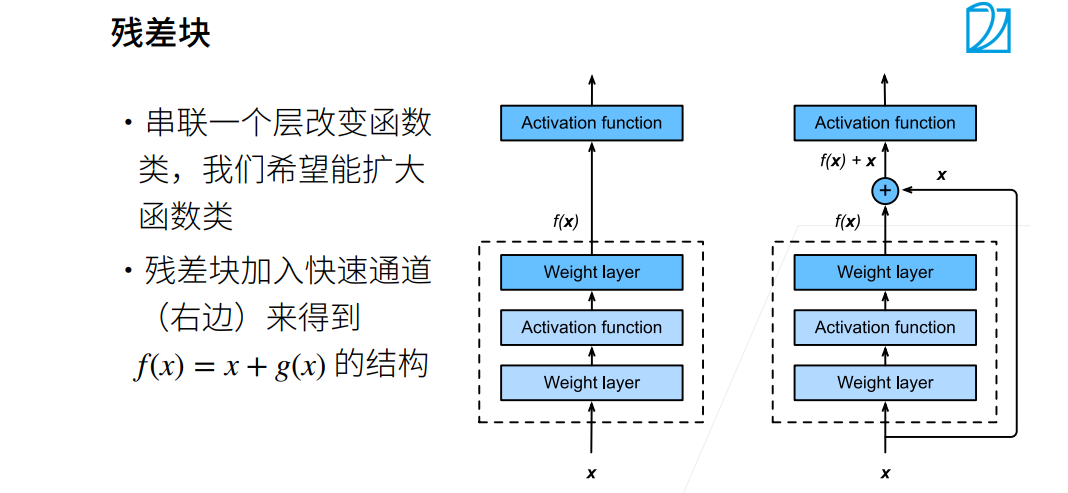
① 这样直接加保证了最优解“至少不会变差”,g(x)=0是和以前一样的。假设没有学到任何东西,则g(x)为0。
② 这个x实际上是f0(x),就是上幅图小的部分,f(x)是f1(x),新函数包含原函数。
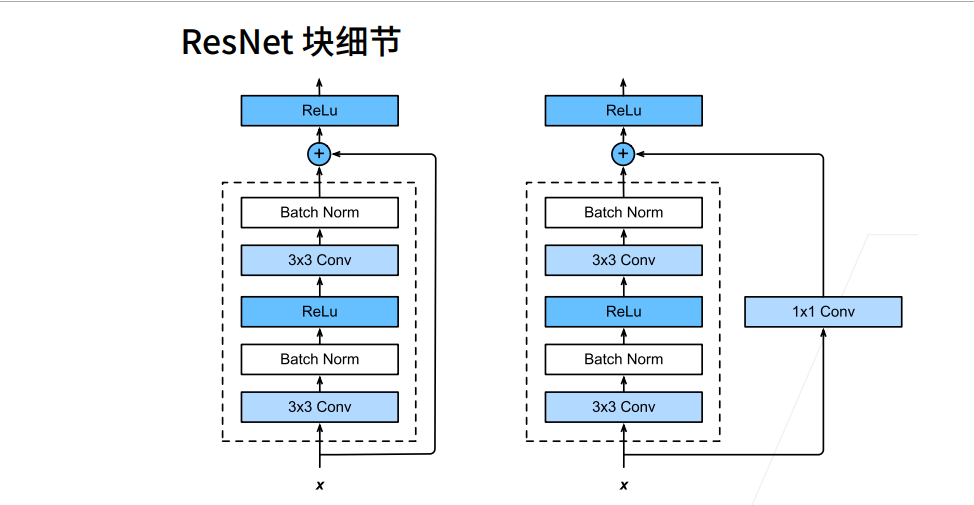
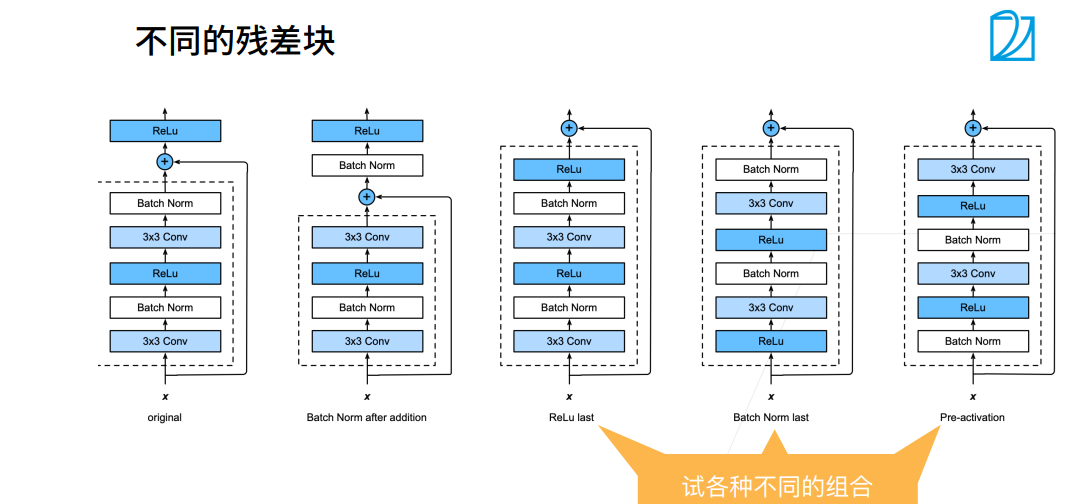
① g(x)高宽减半的同时,1x1 conv的strides=2,也把x高宽减半了。
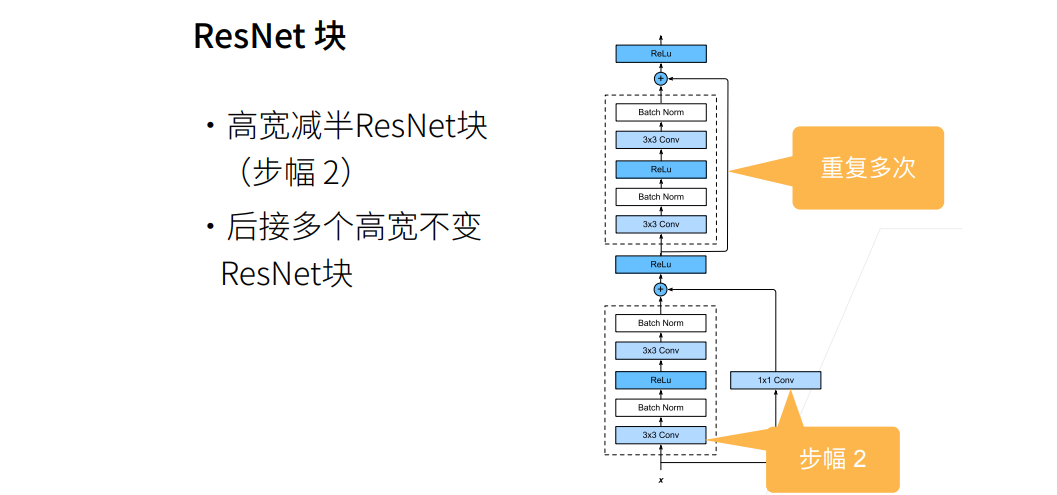


实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual (nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,strides=1): # num_channels为输出channel数
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides) # 可以使用传入进来的strides
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1) # 使用nn.Conv2d默认的strides=1
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True) # inplace原地操作,不创建新变量,对原变量操作,节约内存
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
# 输入和输出形状一致
blk = Residual(3,3) # 输入三通道,输出三通道
X = torch.rand(4,3,6,6)
Y = blk(X) # stride用的默认的1,所以宽高没有变化。如果strides用2,则宽高减半
Y.shape
torch.Size([4, 3, 6, 6])
# ResNet的第一个stage
b1 = nn.Sequential(nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
# class Residual为小block,resnet_block 为大block,为Resnet网络的一个stage
def resnet_block(input_channels,num_channels,num_residuals,first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block: # stage中不是第一个block则高宽减半
blk.append(Residual(input_channels, num_channels, use_1x1conv=True,strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64,64,2,first_block=True)) # 因为b1做了两次宽高减半,nn.Conv2d、nn.MaxPool2d,所以b2中的首次就不减半了
b3 = nn.Sequential(*resnet_block(64,128,2)) # b3、b4、b5的首次卷积层都减半
b4 = nn.Sequential(*resnet_block(128,256,2))
b5 = nn.Sequential(*resnet_block(256,512,2))
net = nn.Sequential(b1,b2,b3,b4,b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(),nn.Linear(512,10))
# 观察一下ReNet中不同模块的输入形状是如何变化的
X = torch.rand(size=(1,1,224,224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape) # 通道数翻倍、模型减半
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
# 训练模型
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.009, train acc 0.998, test acc 0.921
2166.7 examples/sec on cuda:0
序列模型



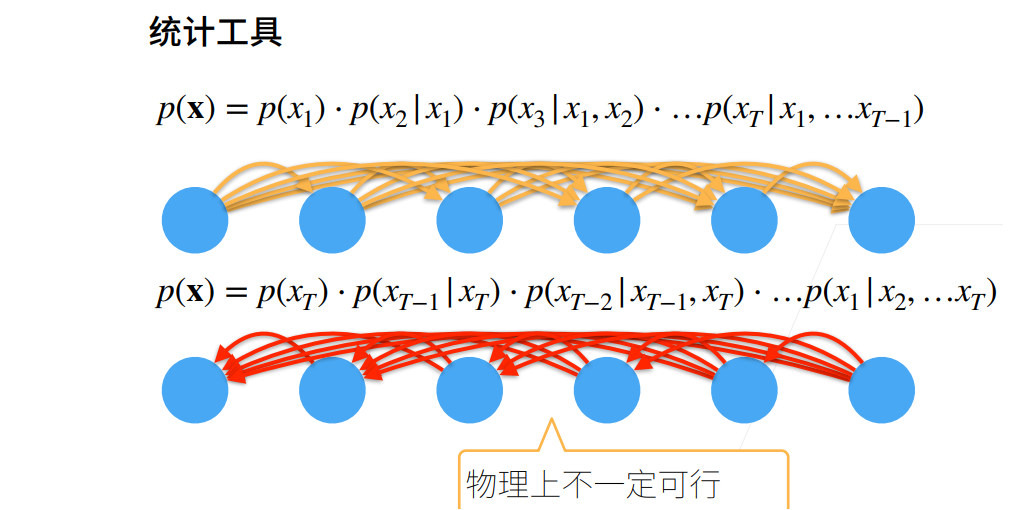


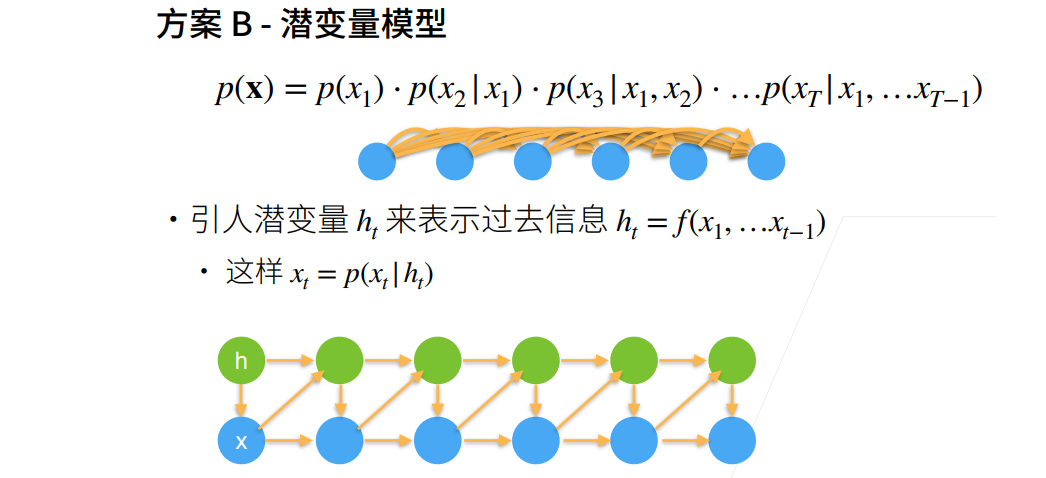

实现
① 使用正弦函数和一些可加性噪声来生成序列数据,时间步为1,2,…,1000
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
# 总时间步数
T = 1000
# 创建一个从1到T的张量
time = torch.arange(1, T + 1, dtype = torch.float32) # 1到1000为时间
# 生成频率为0.01的正弦波并加入随机噪声
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,))
# 绘制数据
d2l.plot(time, [x], 'time', 'x', xlim=[1,1000], figsize=(6,3))
② 将数据映射为数据对 𝑦𝑡=𝑥𝑡和 𝐱𝑡=[𝑥𝑡−𝜏,…,𝑥𝑡−1]
# 延迟时间步长
tau = 4
# 创建一个形状为(T - tau, tau)的零张量作为特征
features = torch.zeros((T - tau, tau)) # T - tau 为样本数,tau 为特征数
# 每四个数据作为特征,第五个作为标签,不断构造这样的数据形成数据集
for i in range(tau):
# 每四个数据作为特征,第五个作为标签,不断构造这样的数据形成数据集
features[:, i] = x[i:T - tau + i]
# 所从第5个时刻开始,每个时刻的label是该时刻的x值,该时刻的输入是前4个时刻的数值组成的一个向量。
# 经过变化后数据的输入共有996组4个一组的数据,输出共996个值
# 提取标签数据并进行形状变换
labels = x[tau:].reshape((-1,1))
# 批量大小和训练样本数量
batch_size, n_train = 16, 600
# 使用 features 和 labels 的前 n_train 个样本创建一个可迭代的训练集
train_iter = d2l.load_array((features[:n_train],labels[:n_train]),
batch_size, is_train=True)
③ 使用一个相当简单的结构:只是一个拥有两个全连接层的多层感知机
def init_weights(m):
# 如果当前模块是线性层
if type(m) == nn.Linear:
# 初始化权重函数
nn.init.xavier_uniform_(m.weight)
def get_net():
# 定义神经网络结构
net = nn.Sequential(nn.Linear(4,10),nn.ReLU(),nn.Linear(10,1))
# 对网络的权重进行初始化
net.apply(init_weights)
# 返回构建好的神经网络模型
return net
# 定义均方误差损失函数
loss = nn.MSELoss()
④ 训练模型
def train(net, train_iter, loss, epochs, lr):
# 定义优化器
trainer = torch.optim.Adam(net.parameters(), lr)
# 迭代训练指定的轮数
for epoch in range(epochs):
# 遍历训练集中的每个批次
for X, y in train_iter:
# 梯度清零
trainer.zero_grad()
# 前向传播计算损失
l = loss(net(X), y)
# 反向传播求梯度
l.backward()
# 更新模型参数
trainer.step()
# 打印当前轮次的损失
print(f'epoch {epoch + 1}, '
f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')
# 创建神经网络模型
net = get_net()
# 训练模型
train(net, train_iter, loss, 5, 0.01)
epoch 1, loss: 0.065596
epoch 2, loss: 0.055322
epoch 3, loss: 0.052283
epoch 4, loss: 0.050081
epoch 5, loss: 0.050155
⑤ 模型预测下一个时间步
# 对特征进行一步预测
onestep_preds = net(features)
# 进行数据可视化,将真实数据和一步预测结果绘制在同一个图中进行比较
d2l.plot([time, time[tau:]],
[x.detach().numpy(), onestep_preds.detach().numpy()], 'time', 'x',
legend = ['data','l-step preds'], xlim = [1, 1000], figsize=(6,3))
文本预处理
import collections
import re
from d2l import torch as d2l
① 将数据集读取到由文本行组成的列表中。
# 下载并存储 'time_machine' 数据集的 URL 和哈希值
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
"""Load the time machine dataset into a list of text lines. """
"""将时间机器数据集加载为文本行的列表。"""
# 打开 'time_machine' 数据集文件,并使用文件对象 f 进行操作
with open(d2l.download('time_machine'), 'r') as f:
# 读取文件的所有行,并将每行存储在列表 lines 中
lines = f.readlines()
# 把不是大写字母、小写字母的东西,全部变成空格
# 去除非字母字符,并转换为小写
return [re.sub('[^A-Za-z]+',' ',line).strip().lower() for line in lines]
# 读取时间机器数据集,并将结果存储在 'lines' 变量中
lines = read_time_machine()
# 打印数据集的第一行
print(lines[0])
# 打印数据集的第11行(索引为10)
print(lines[10])
the time machine by h g wells
twinkled and his usually pale face was flushed and animated the
② 每个文本序列又被拆分成一个标记列表。
def tokenize(lines, token='word'):
"""
将文本行列表进行分词处理。
Parameters:
lines (list): 文本行列表。
token (str): 令牌类型,可选值为 'word'(默认)或 'char'。
Returns:
list: 分词后的结果列表。
Raises:
None
"""
# 如果令牌类型为 'word'
if token == 'word':
# 以空格为分隔符将每行字符串拆分为单词列表
return [line.split() for line in lines]
# 如果令牌类型为 'char'
elif token == 'char':
# 将每行字符串拆分为字符列表
return [list(line) for line in lines]
else:
# 若指定的令牌类型无效,则打印错误信息
print('错位:未知令牌类型:' + token)
# 对 lines 进行分词处理,使用默认的 'word' 令牌类型
tokens = tokenize(lines)
# 打印前11行的分词结果
for i in range(11):
# 空列表表示空行
print(tokens[i])
[‘the’, ‘time’, ‘machine’, ‘by’, ‘h’, ‘g’, ‘wells’]
[]
[]
[]
[]
[‘i’]
[]
[]
[‘the’, ‘time’, ‘traveller’, ‘for’, ‘so’, ‘it’, ‘will’, ‘be’, ‘convenient’, ‘to’, ‘speak’, ‘of’, ‘him’]
[‘was’, ‘expounding’, ‘a’, ‘recondite’, ‘matter’, ‘to’, ‘us’, ‘his’, ‘grey’, ‘eyes’, ‘shone’, ‘and’]
[‘twinkled’, ‘and’, ‘his’, ‘usually’, ‘pale’, ‘face’, ‘was’, ‘flushed’, ‘and’, ‘animated’, ‘the’]
③ 构建一个字典,通常也叫做词表(vocabulary),用来你将字符串标记映射到从0开始的数字索引中。
class Vocab:
"""文本词表"""
def __init__(self, tokens=None,min_freq=0,reserved_tokens=None):
"""
初始化词表对象。
Parameters:
tokens (list): 标记列表(默认为 None)。
min_freq (int): 最小频率阈值,低于该频率的标记将被过滤掉(默认为 0)。
reserved_tokens (list): 保留的特殊标记列表(默认为 None)。
Returns:
None
Raises:
None
"""
# 如果输入的 tokens 为 None,则将其设置为空列表
if tokens is None:
tokens = []
# 如果保留的特殊标记列表 reserved_tokens 为 None,则将其设置为空列表
if reserved_tokens is None:
reserved_tokens = []
# 统计 tokens 中标记的频率,并返回一个包含标记频率的 Counter 对象
counter = count_corpus(tokens) # 遍历得到每一个独一无二token出现的次数
# 根据标记的频率进行排序,并将结果存储在 self.token_freqs 中
# sorted() 函数使用 counter.items() 作为排序对象,使用标记频率 x[1] 作为排序依据,降序排序
self.token_freqs = sorted(counter.items(),key=lambda x:x[1],reverse=True)
# 设置未知标记索引为 0,构建包含未知标记和保留特殊标记的列表 uniq_tokens
self.unk, uniq_tokens = 0, ['<unk>'] + reserved_tokens
# 将频率大于等于 min_freq 且不在 uniq_tokens 中的标记添加到 uniq_tokens 列表中
uniq_tokens += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in uniq_tokens]
# 初始化索引到标记和标记到索引的空列表和字典
self.idx_to_token, self.token_to_idx = [], dict()
# 遍历 uniq_tokens 中的每个标记,将其添加到索引到标记的列表中,并将标记和对应索引存储到标记到索引的字典中
# 索引值从 0 开始递增,对应于标记在列表中的位置
for token in uniq_tokens:
# 将当前标记 `token` 添加到索引到标记的列表 `self.idx_to_token` 的末尾
self.idx_to_token.append(token)
# 将当前标记 `token` 和其对应的索引值存储到标记到索引的字典 `self.token_to_idx` 中
# 索引值是 `self.idx_to_token` 列表的长度减去 1,即标记在列表中的位置索引
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
"""
获取词表的长度。
Parameters:
None
Returns:
int: 词表的长度。
Raises:
None
"""
# 获取词表的长度
return len(self.idx_to_token)
def __getitem__(self, tokens):
"""
根据标记获取其对应的索引或索引列表。
Parameters:
tokens (str or list): 标记字符串或标记列表。
Returns:
int or list: 标记的索引或索引列表。
Raises:
None
"""
# 如果 tokens 不是列表或元组,则返回对应的索引或默认的未知标记索引
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
# 对于输入的标记列表 tokens,逐个调用 self.__getitem__() 方法获取每个标记对应的索引值,并返回索引值的列表
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
"""
根据索引获取对应的标记或标记列表。
Parameters:
indices (int or list): 索引或索引列表。
Returns:
str or list: 索引对应的标记或标记列表。
Raises:
None
"""
# 如果输入的 indices 不是列表或元组类型,则返回对应索引值处的标记
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
# 对于输入的索引列表 indices,逐个取出每个索引值 index,并通过 self.idx_to_token[index] 获取对应的标记值,最后返回标记值组成的列表
return [self.idx_to_token[index] for index in indices]
def count_corpus(tokens):
"""
统计标记的频率。
Parameters:
tokens (list): 标记列表。
Returns:
collections.Counter: 包含标记频率的 Counter 对象。
Raises:
None
"""
# 检查 tokens 是否是一个列表的列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 如果 tokens 是一个列表的列表,则将其展平为一维列表
tokens = [token for line in tokens for token in line]
# 使用 collections.Counter 统计标记的频率
return collections.Counter(tokens)
④ 构建词汇表
# 创建一个 Vocab 对象,将标记列表 tokens 作为参数传入,用于构建词表
vocab = Vocab(tokens)
# 获取词表中的前 10 个标记及其对应的索引值,并将其转换为列表进行打印输出
print(list(vocab.token_to_idx.items())[:10])
[(‘’, 0), (‘the’, 1), (‘i’, 2), (‘and’, 3), (‘of’, 4), (‘a’, 5), (‘to’, 6), (‘was’, 7), (‘in’, 8), (‘that’, 9)]
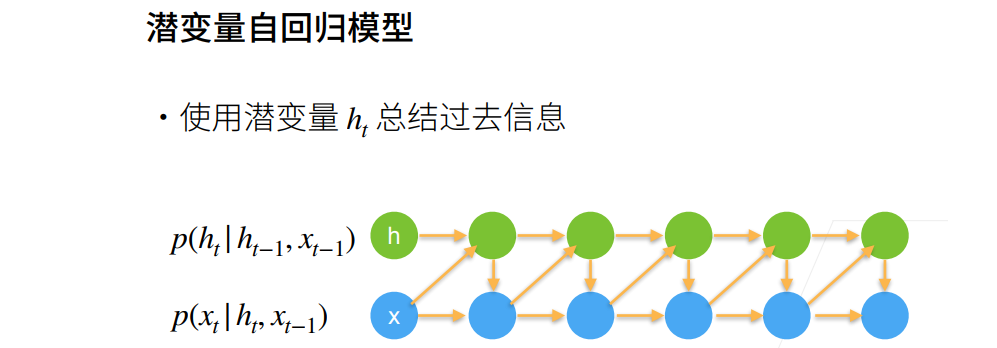
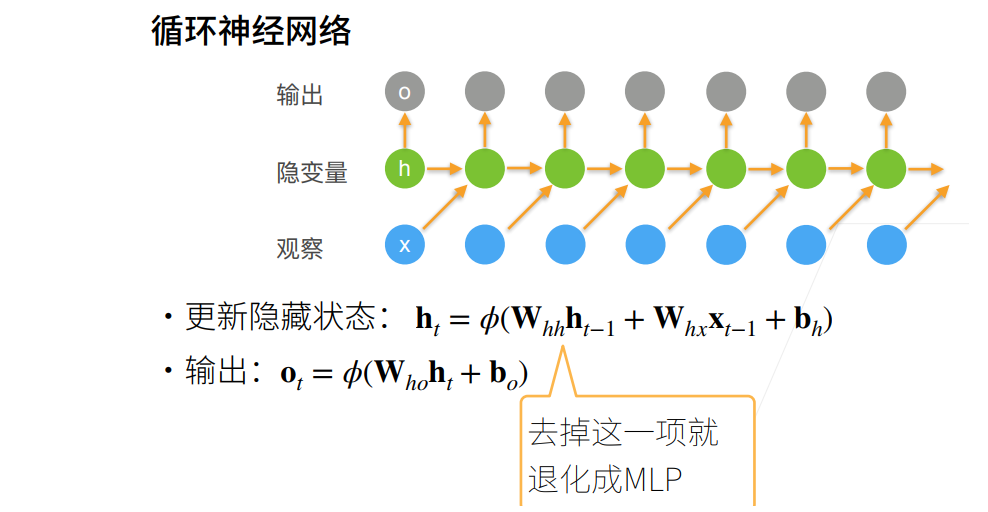
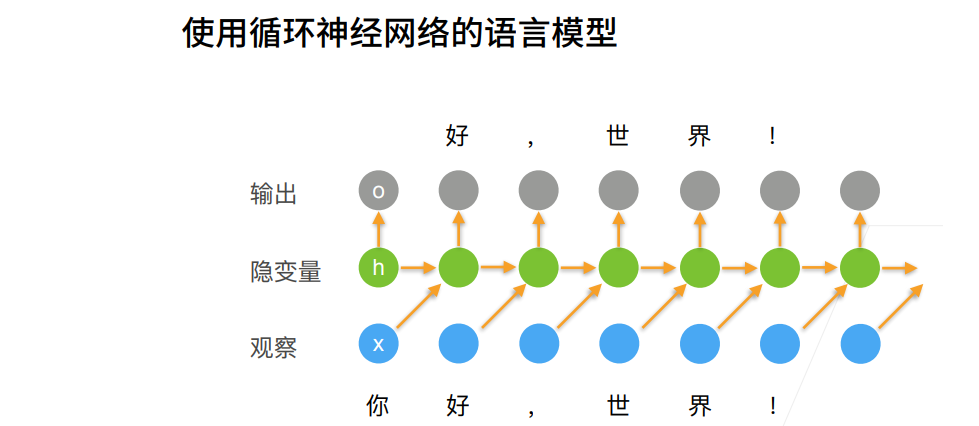
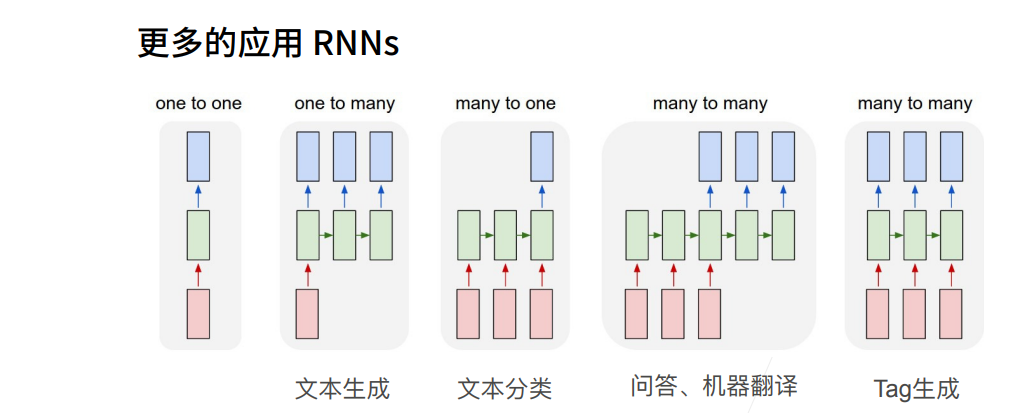
循环神经网络RNN





















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









