



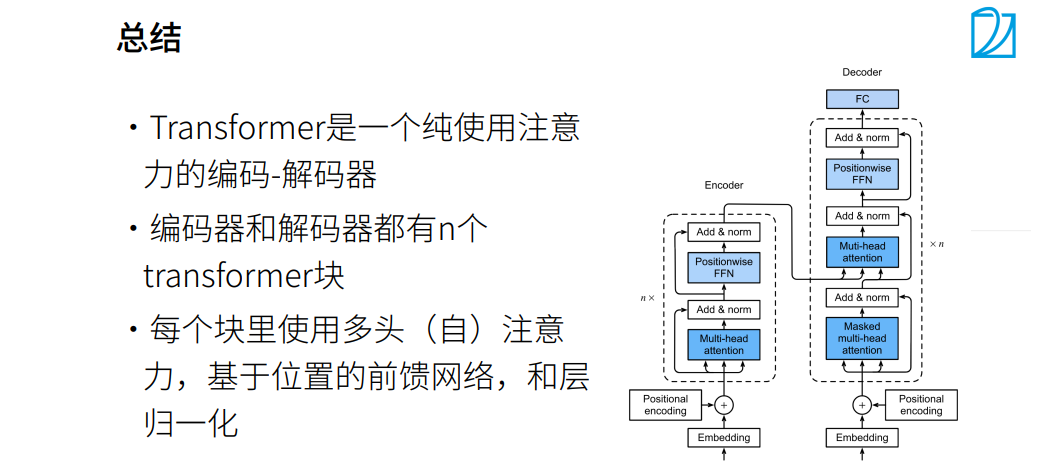
摘要
本周主要学习注意力机制和优化算法。
注意力机制
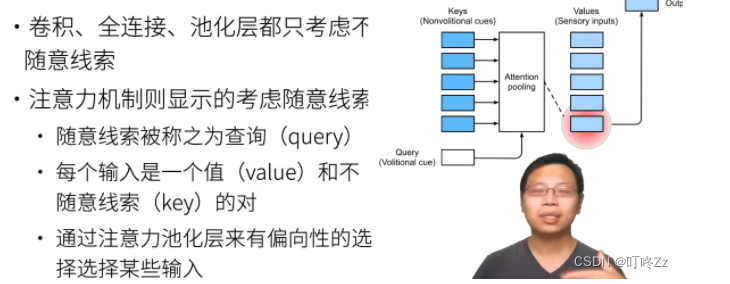
**随意:**跟随自己的想法的,自主的想法,例如query
**不随意:**没有任何偏向的选择,例如 Keys
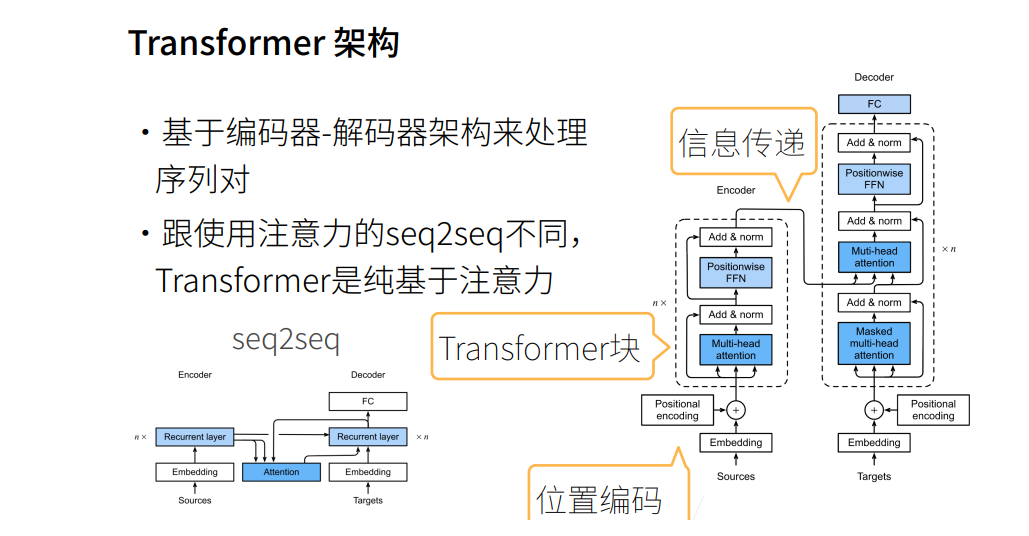
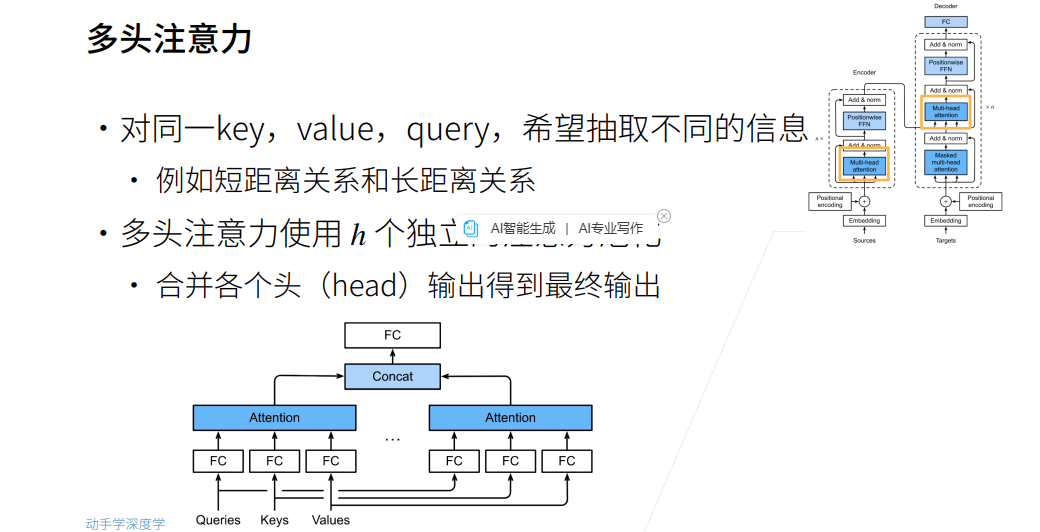
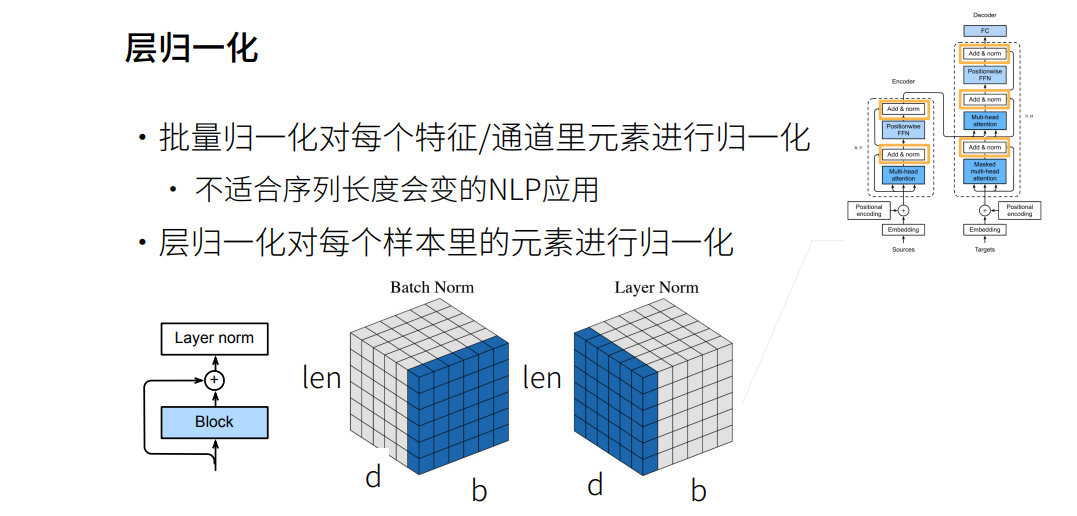
Transformer




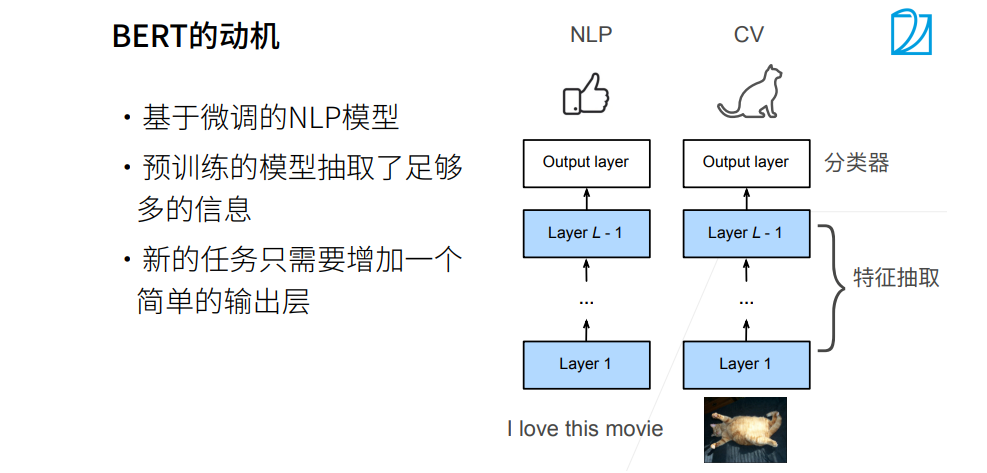
BERT


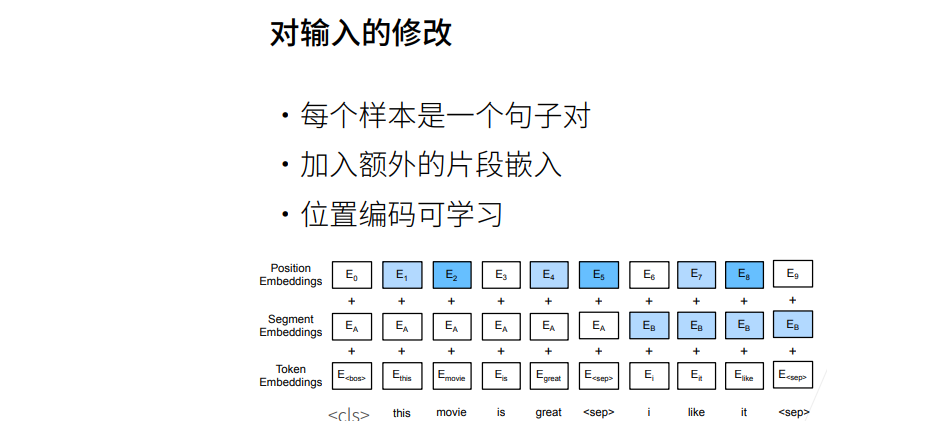
实现
import torch
from torch import nn
from d2l import torch as d2l
# Input Representation
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""Get tokens of the BERT input sequence and their segment IDs"""
# 添加特殊标记,并连接第一个句子的标记
tokens = ['<cls>'] + tokens_a + ['<seq>']
# 第一个句子的段ID都为0
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
# 如果存在第二个句子,则连接第二个句子的标记
tokens += tokens_b + ['<seq>']
# 第二个句子的段ID都为1
segments += [1] * (len(tokens_b) + 1)
# 返回转换后的标记列表和段ID列表
return tokens, segments
# BERTEncoder class
class BERTEncoder(nn.Module):
"""BERT encoder."""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
# 标记嵌入层
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
# 段嵌入层
self.segment_embedding = nn.Embedding(2, num_hiddens)
# BERT编码器块的序列容器
self.blks = nn.Sequential()
for i in range(num_layers):
# 添加BERT编码器块
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len, num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 计算输入序列的嵌入表示
X = self.token_embedding(tokens) + self.segment_embedding(segments)
# 添加位置嵌入
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
# 通过BERT编码器块进行编码
X = blk(X, valid_lens)
return X
class BERTEncoder(nn.Module):
"""BERT encoder."""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
# 标记嵌入层
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
# 段嵌入层
self.segment_embedding = nn.Embedding(2, num_hiddens)
# BERT编码器块的序列容器
self.blks = nn.Sequential()
for i in range(num_layers):
# 添加BERT编码器块
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 计算嵌入表示
X = self.token_embedding(tokens) + self.segment_embedding(segments)
# 添加位置嵌入
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
# 进行编码
X = blk(X, valid_lens)
return X
# Putting All Things Together
class BERTModel(nn.Module):
"""The BERT model."""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, mlm_in_features=768,
nsp_in_features=768):
super(BERTModel, self).__init__()
# BERT编码器
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,
ffn_num,input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=max_len, key_size=key_size)
# 隐藏层
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens), nn.Tanh())
# 掩码语言模型
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
# 下一句预测模型
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None, pred_positions=None):
# 使用编码器对输入进行编码
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
# 如果传入了pred_positions参数,则调用掩码语言模型进行预测
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# 将encoded_X的第一个位置的隐藏表示通过隐藏层进行转换
# 使用下一句预测模型进行预测
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat
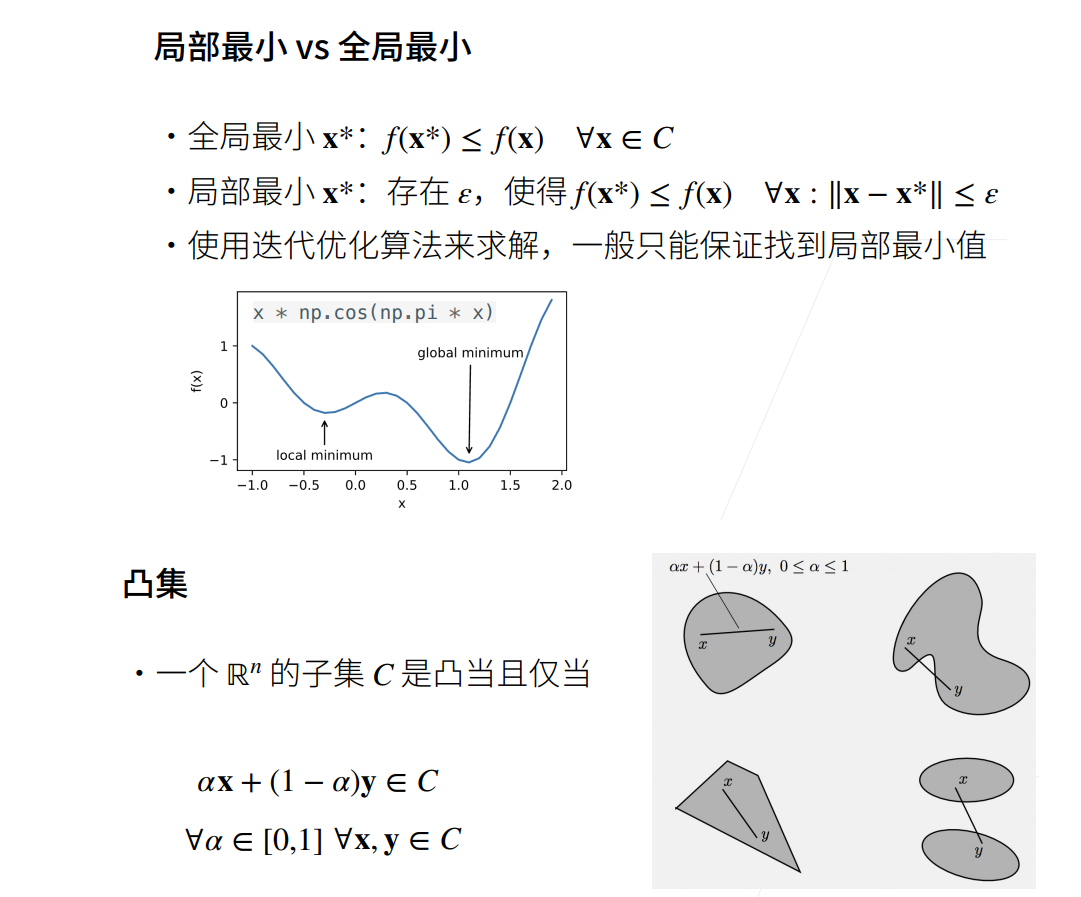
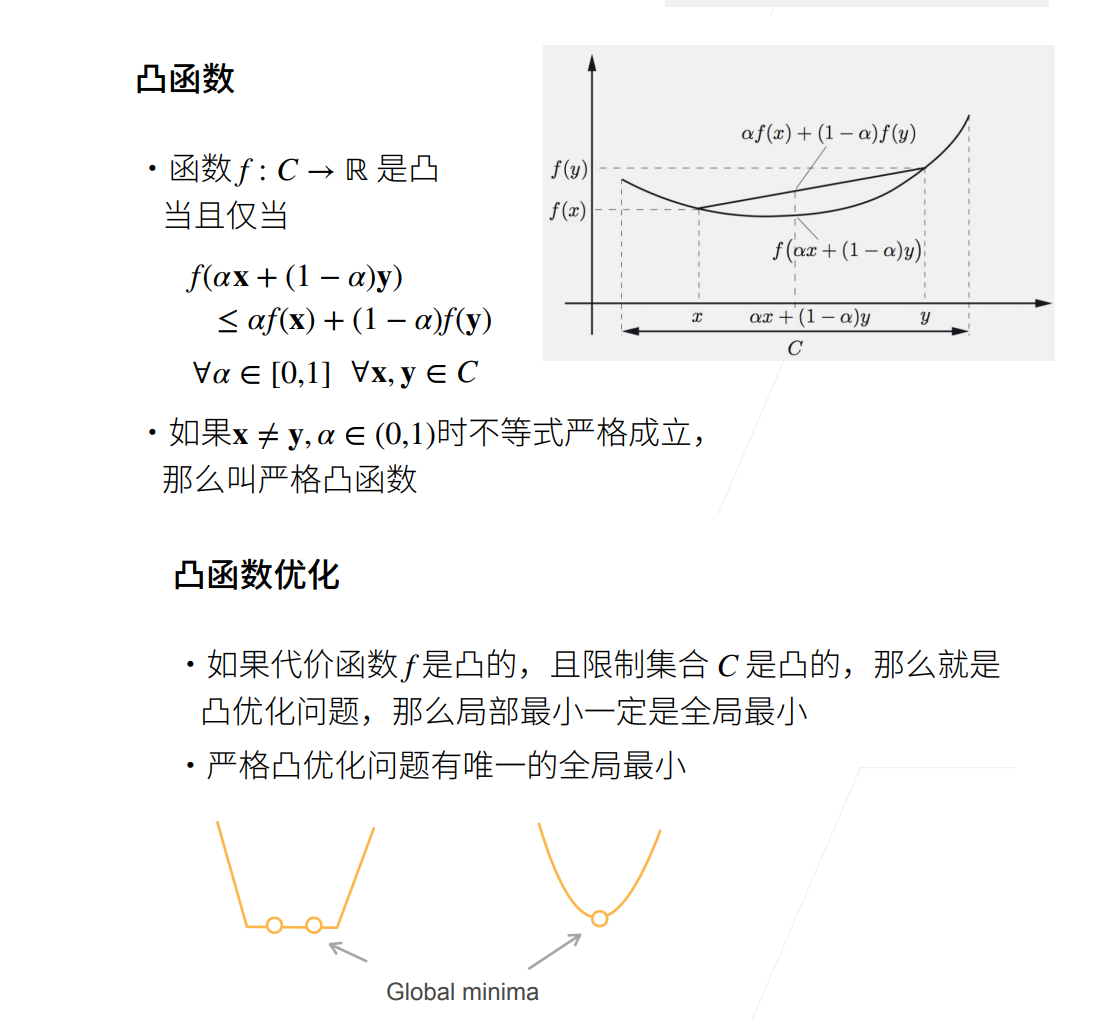
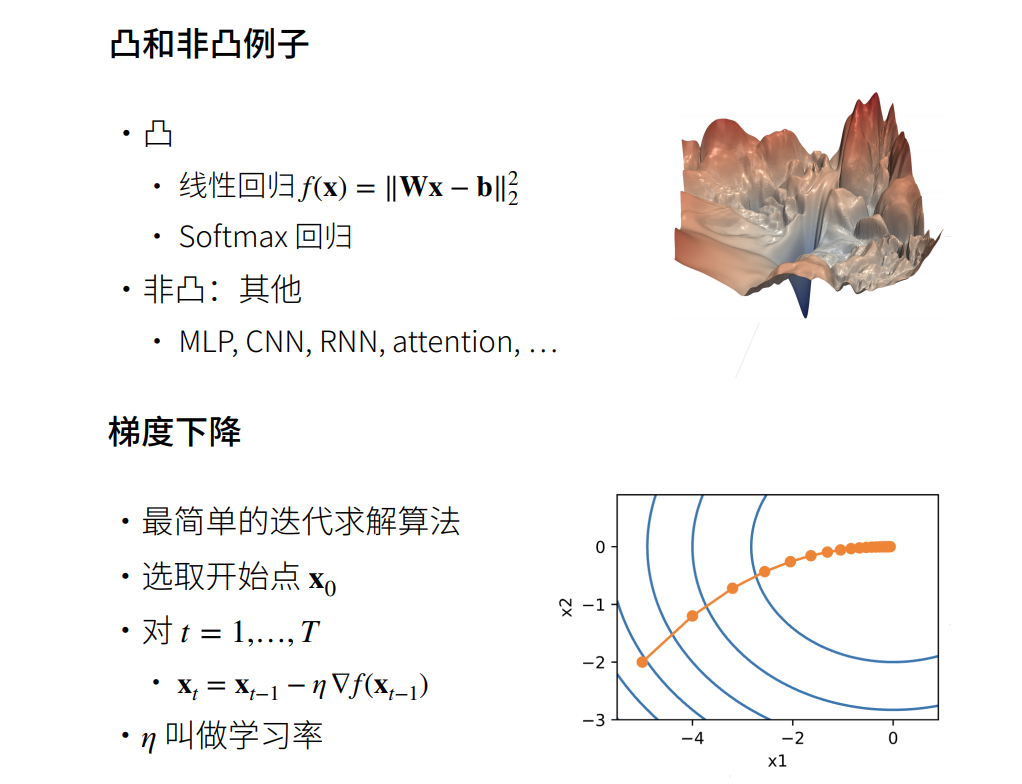
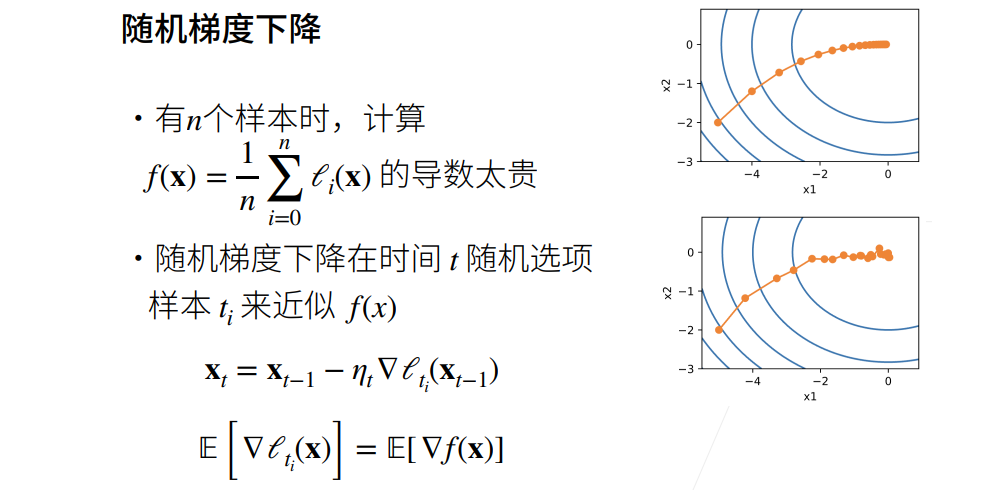
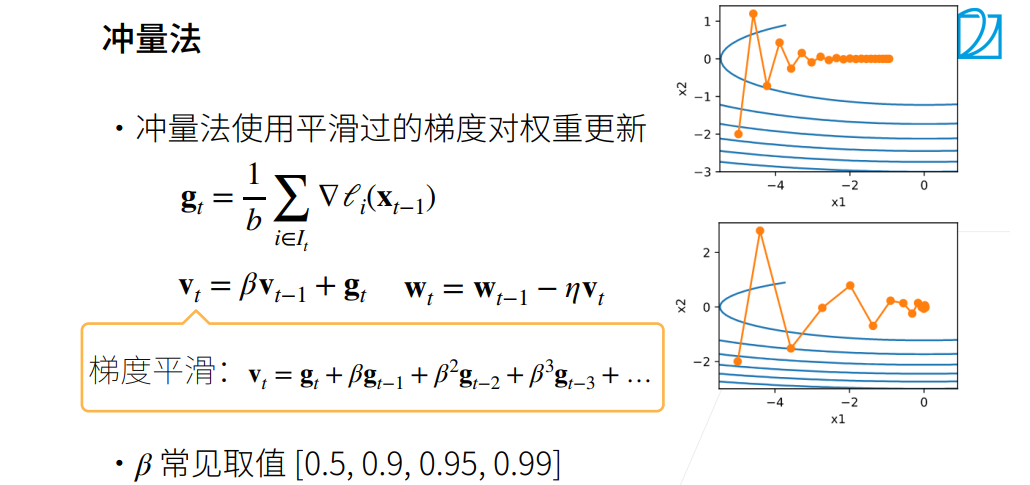
优化算法




















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









