



devtools::install_github("interstellar-Consultation-Services/dbdataset")
library(dbdataset)
# 获取 drugbank 数据集
data(drugbank, package = "dbdataset")
# 查看 drugbank 下面有哪些数据框
names(drugbank)
# 遍历 drugs 列表中的每个数据框并保存为 CSV 文件
for (i in seq_along(drugbank$drugs)) {
df_name <- names(drugbank$drugs)[i]
df <- drugbank$drugs[[i]]
# 转换所有列表列为字符串,用分号分隔元素,确保返回原子向量
df <- as.data.frame(lapply(df, function(col) {
if (is.list(col)) {
vapply(col, function(x) {
if (length(x) == 0) {
NA_character_
} else {
paste(x, collapse = "; ")
}
}, FUN.VALUE = character(1))
} else {
# 确保非列表列也为原子向量
as.character(col)
}
}), stringsAsFactors = FALSE)
# 检查各列长度是否一致
col_lengths <- sapply(df, length)
if (length(unique(col_lengths)) != 1) {
warning(sprintf("数据框 '%s' 存在列长度不一致: %s", df_name, paste(col_lengths, collapse=", ")))
next # 跳过问题数据框
}
# 保存为CSV
file_name <- paste0("D:/Code/drug_disease/DRUGBANK/", df_name, ".csv")
write.csv(df, file_name, row.names = FALSE)
print(paste("Saved:", file_name))
}
输出是这样的
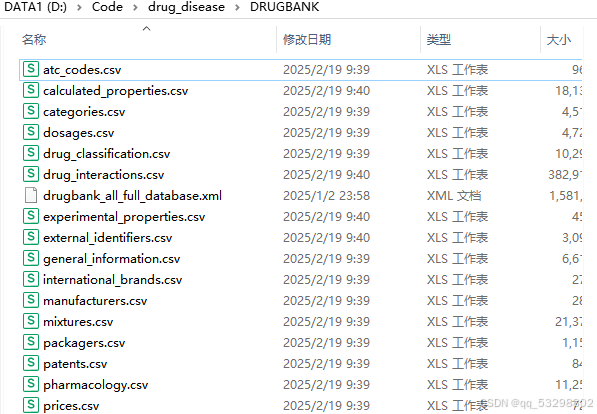
里面的内容就是表格形式,便于我们查看和处理

















 3794
3794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









