






幻觉现象
定义:
大语言模型(LLM)的“幻觉现象”是指模型生成的内容看似合理,但实际上包含事实性错误、逻辑矛盾或完全虚构的信息。这些输出可能表现为捏造数据、歪曲事实、杜撰引用文献,甚至凭空创造不存在的概念或事件。
核心问题:
模型在缺乏真实知识或对任务理解不足时,倾向于依赖统计规律“脑补”答案,而非基于事实或逻辑推理。
幻觉的典型表现
| 类型 | 例子 |
|---|---|
| 事实性幻觉 | - 声称“秦始皇在公元前200年统一六国”(实际是公元前221年) - 编造不存在的学术论文标题和作者 |
| 逻辑性幻觉 | - 矛盾陈述:“水的沸点是100°C,但在高海拔地区仍然是100°C” - 错误因果关系:“下雨导致地震” |
| 上下文幻觉 | - 回答与问题无关:“如何更换轮胎?”→“企鹅是南极洲的鸟类,它们不会飞。” |
| 创造性幻觉 | - 虚构人物生平:“19世纪科学家约翰·史密斯发明了量子计算机” |
缓解策略
提示词工程
用户文本输入——提示词;提示词有模版,从而便于管理与维护。
提示词模版
模板可以包含一组模版参数,通过模版参数值可以替换模板对应的参数。
种类繁多,还有 PromptTemplate:字符串模板;输出message就是个字符串。
一个提示词模版包含以下内容:
1、发给LLM的指令;2、一组问答示例,提醒AI返回请求的格式;3、发给语言模型的问题
- 检索增强生成(RAG):
结合外部知识库(如维基百科、专业数据库),在生成前检索相关事实,约束模型输出。 - 强化学习与人类反馈(RLHF):
通过人类标注纠正幻觉,训练模型偏好事实性回答。 - 自洽性校验(Self-Consistency):
多次生成答案并投票选择最一致的版本,减少随机错误。 - 提示工程(Prompt Engineering):
明确要求模型避免猜测,例如:
“请仅基于可靠来源回答,不确定时请说明‘暂无确切信息’。” - 后处理校验:
使用事实核查API或规则系统过滤明显错误(如日期矛盾、虚构人名)。
Demo
所有和LLM交互都是通过Message的JSON格式;下图就是一个ChatPromptTemplate;并通过传参进行修改。
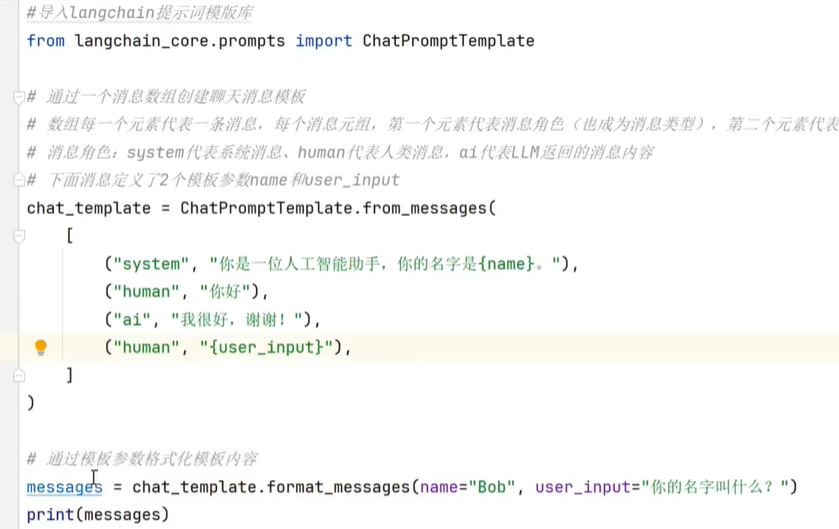
![]()
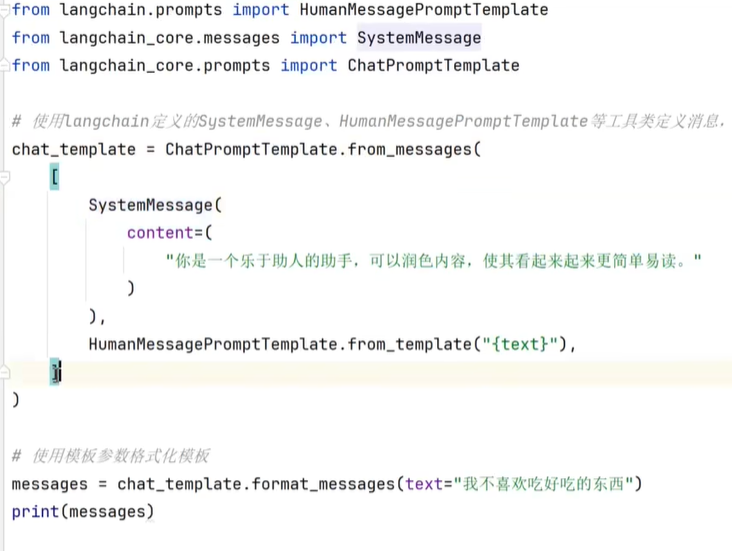
另一种定义方式:直接在ChatPromptTemplate.from_message中输入 Message对象(SystemMessage、HumanMessage)
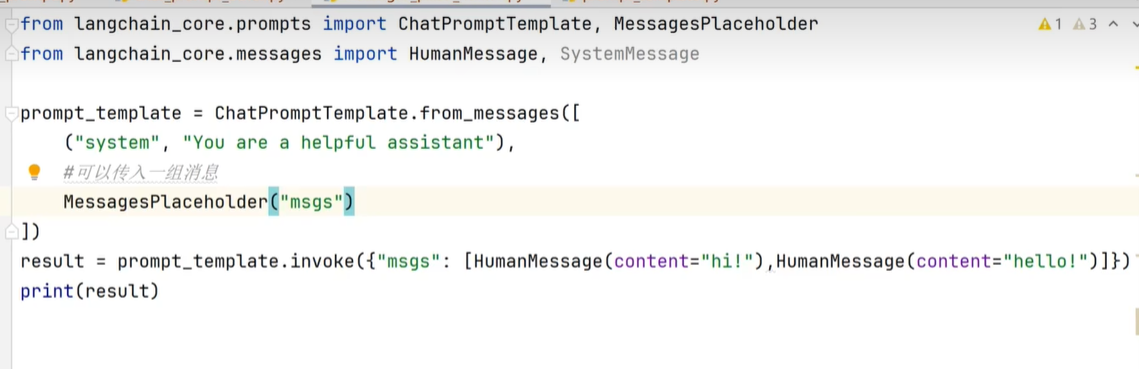
MessagesPlaceholder
相当于创建一个占位符(msgs)、然后可以invoke给MessagesPlaceholder传入新的消息列表;
提示词追加示例(Few-shot prompt templates)
提示词中包含交互示例可以帮助模型更好理解用户意图。减少幻觉问题;

创建示例集
examples 相当于 小型知识库。创建好提示词模板后,通过FewShotPromptTemplate将examples传入提示词模板。
模版中通过template定义了 examples的参数占位
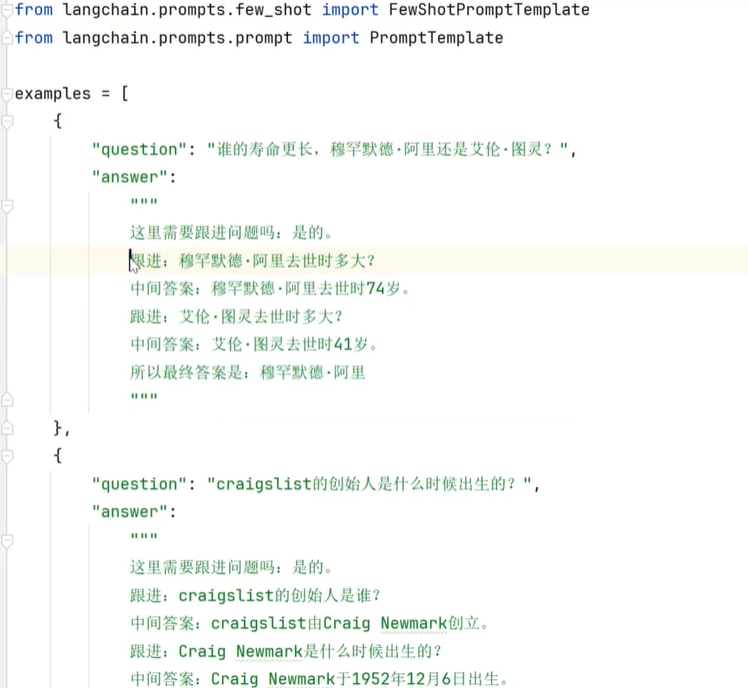
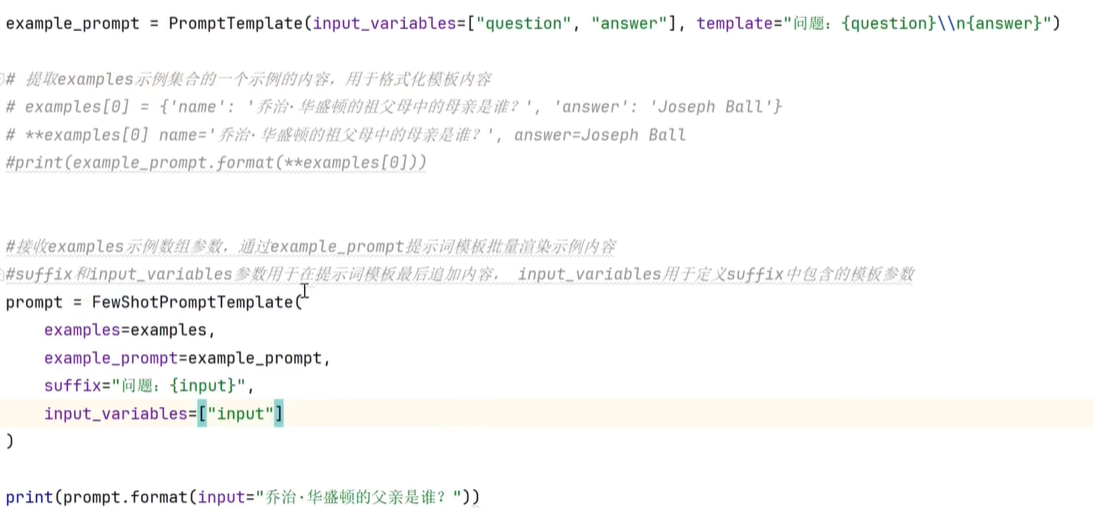
创建小样本示例的格式化程序
通过**examples[0]只取一个样本示例。

示例选择器
当示例集非常丰富时,考虑token数和上下文长度。我们不每次携带全量示例集。因此,我们通过SemanticSimilarityExampleSelector类,进行选择和输入相似搜索,获取相似示例。
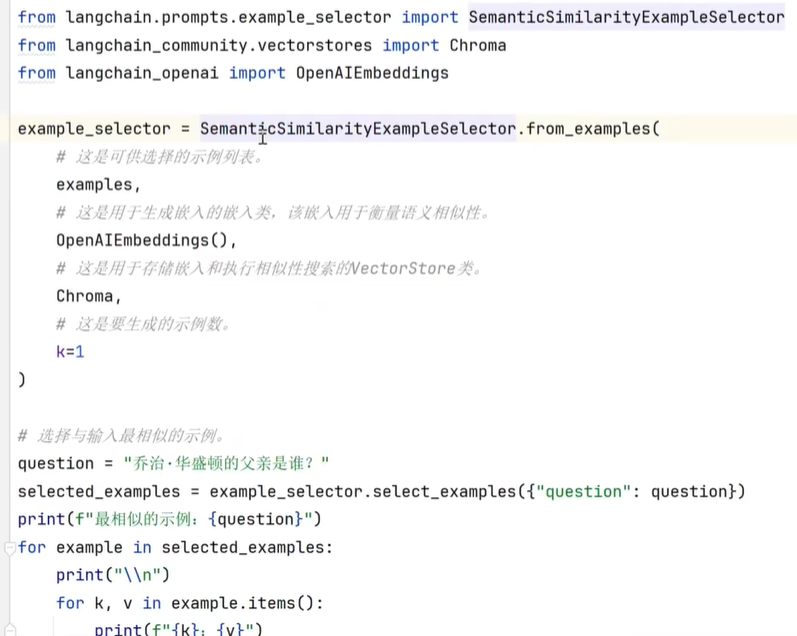

结合FewShotPromptTemplate
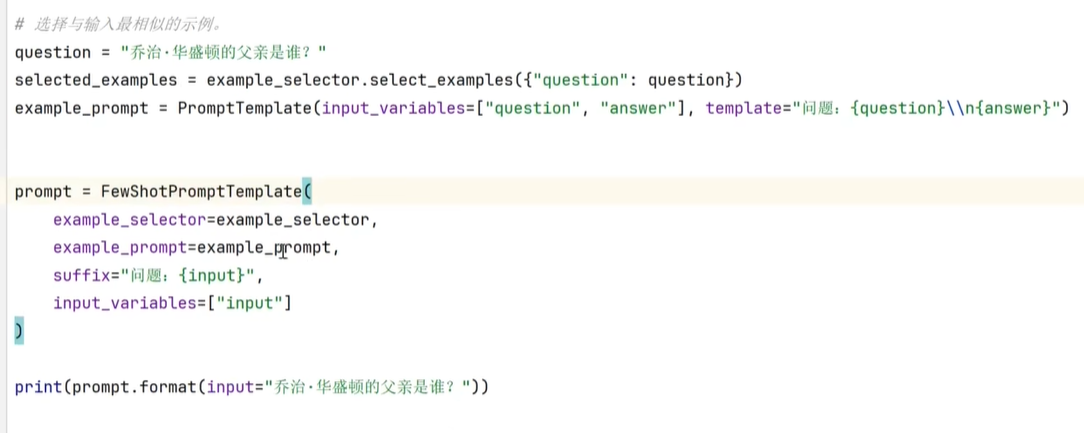
就是往FewShotPromptTemplate传入 SemanticSimilarityExampleSelector;
这样可以先计算语义相似,再生成提示词,相当于用相似度做了个Select来完成小样本。

















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









