






1.采集数据
x = np.random.uniform(-10.,10.),x从(-10,10)随机取值(这样就不用打乱了)。
eps = np.random.normal(0.,0.01),eps可以理解为误差(结果更符合实际),eps符合高斯分布(正态分布)。
data=[]保存数据和标签。
data = []#保存样本的列表
for i in range(100):
x = np.random.uniform(-10.,10.) #随机采样输入x
eps = np.random.normal(0.,0.01)#采用高斯噪声
y = 2.5012*x+1.888+eps
data.append([x,y])
data = np.array(data)
2.计算误差
每个(x,y)的预测值和真实值的平法差,除len(point)得均方误差
def mse(b,w,points):
totalError = 0
for i in range(0,len(points)):
x=points[i,0]
y=points[i,1]
totalError+=(y-(w*x+b))**2
return totalError/float(len(points))
3.计算梯度
lr为学习率
误差函数对b求导:grad_b=2(wx+b-y)
误差函数对w求导:grad_w=2(wx+b-y)*x
def step_gradient(b_current,w_current,points,lr):
b_gradient = 0
w_gradient = 0
M=float(len(points))#总样本数
for i in range(0,len(points)):
x = points[i,0]
y = points[i,1]
b_gradient+=(2/M)*((w_current*x+b_current)-y)
w_gradient+=(2/M)*x*((w_current*x+b_current)-y)
new_b = b_current-(lr*b_gradient)
new_w = w_current-(lr*w_gradient)
return [new_b,new_w]
4.梯度更新 and 主函数
def gradient_descent(points,starting_b,starting_w,lr,num_iterations):
b = starting_b
w = starting_w
for step in range(num_iterations):
b,w = step_gradient(b,w,np.array(points),lr)
loss = mse(b,w,points)
if step%50 ==0:
print(f"iteration: {step} , loss:{loss},w:{w},b:{b}")
return [b,w]
每50步打印一次:
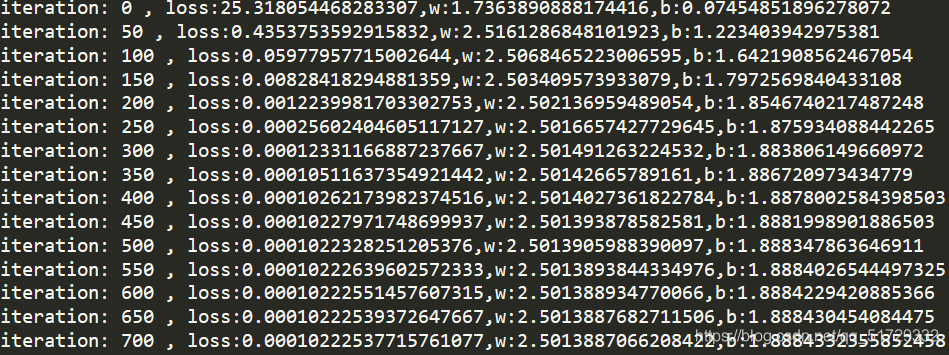
主函数:
def main():
lr = 0.01 #学习率
initial_b = 0 #初始化b,w
initial_w = 0
num_iterations = 1000 #进行的次数
[b,w] = gradient_descent(data,initial_b,initial_w,lr,num_iterations)
loss = mse(b,w,data)
print(f'Final loss:{loss},w:{w},b:{b}')
结果:

和最初设置的w,b相当吻合了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









