









目录
在 2025 年 3 月 26 日,我完成了一个轻量级的项目:在我的 RTX 4070 显卡上成功部署 Stable Diffusion,生成高质量图像并实现多尺度优化。下面是我从环境配置到生成高分辨率图像的完整学习过程,旨在为其他学习者提供一些实用参考。
第一步:环境配置与验证
操作步骤
-
目标: 配置支持 GPU 的 PyTorch 环境。
-
在 Anaconda 中创建新环境
kaiti:conda create -n kaiti python=3.11 -
卸载旧版 PyTorch:
pip uninstall torch torchvision torchaudio -
安装新版 PyTorch:
pip install torch==2.5.1+cu121 torchvision==0.16.1+cu121 -f https://download.pytorch.org/whl/torch_stable.html -
验证 GPU 可用性:
import torch print(torch.cuda.is_available()) # True 表示成功配置 -
安装依赖:
pip install diffusers transformers accelerate safetensors
问题与解决
-
问题: 旧版 PyTorch 不支持 CUDA,需要手动卸载。
-
解决: 按照官方指南安装新版 PyTorch,成功确认 CUDA 设备可用。
收获
-
学会了如何使用 Anaconda 管理环境并配置 GPU 支持的 PyTorch。
第二步:初次生成图像
操作步骤
-
目标: 使用 Stable Diffusion 生成第一张图像。
-
编写
generate_image.py代码:from diffusers import StableDiffusionPipeline import torch pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16) pipe = pipe.to("cuda") image = pipe("a majestic dragon flying over a fantasy castle at sunset", num_inference_steps=30).images[0] image.save("generated_dragon.png")
问题与解决
-
问题: 下载模型速度慢。
-
解决: 手动下载模型文件,减少下载时间。最终成功生成图像。
收获
-
成功生成了我的第一张图像,确认了模型部署的可行性。
第三步:优化生成效率
操作步骤
-
目标: 避免每次修改提示词时都重新运行脚本。
-
编写交互式脚本:
while True: prompt = input("请输入提示词 (输入 'exit' 退出): ") if prompt.lower() == "exit": break image = pipe(prompt, num_inference_steps=30).images[0] image.save(f"generated_pic/image_{datetime.now().strftime('%Y%m%d_%H%M%S')}.png")
问题与解决
-
问题: 模型每次都加载,浪费时间。
-
解决: 将模型加载移到循环外,只加载一次,提升效率。
收获
-
实现了更高效的图像生成,每次生成图像只需 2-3 秒。
第四步:数据集驱动生成
操作步骤
-
目标: 批量生成图像以满足导师的要求。
-
创建
prompts.txt文件:a futuristic city, cyberpunk style a serene lake, photorealistic -
修改脚本来批量生成图像:
with open("prompts.txt", "r", encoding="utf-8") as file: prompts = [line.strip() for line in file] for i, prompt in enumerate(prompts, 1): image = pipe(prompt, num_inference_steps=20).images[0] image.save(f"generated_pic/image_{i:03d}.png")
问题与解决
-
没有遇到明显问题,顺利完成批量生成。
收获
-
成功实现了批量生成并有序保存图像。
第五步:多尺度创新尝试
操作步骤
-
目标: 通过多尺度生成提高图像质量。
-
使用基础模型生成 256x256 图像,然后用
StableDiffusionUpscalePipeline放大至 1024x1024。 -
设计自定义
custom_upscale方法:def custom_upscale(low_res_image, prompt, target_size=(1024, 1024), refine_steps=20): upscale = low_res_image.resize(target_size, Image.BICUBIC) upscale_tensor = T.ToTensor()(upscale).unsqueeze(0).to("cuda", torch.float16) latent = pipe.vae.encode(upscale_tensor).latent_dist.sample() * pipe.vae.config.scaling_factor text_embeddings = pipe.text_encoder(pipe.tokenizer(prompt, return_tensors="pt").input_ids.to("cuda"))[0].to(torch.float16) scheduler = PNDMScheduler.from_config(pipe.scheduler.config) scheduler.set_timesteps(refine_steps) latents = latent for t in scheduler.timesteps: timestep = torch.tensor([t], dtype=torch.long, device="cuda") noisy_latents = scheduler.add_noise(latents, torch.randn_like(latents) * 0.05, timestep).to(torch.float16) pred_noise = pipe.unet(noisy_latents, timestep, text_embeddings).sample latents = scheduler.step(pred_noise, timestep, noisy_latents).prev_sample.to(torch.float16) refined_tensor = pipe.vae.decode(latents / pipe.vae.config.scaling_factor).sample return T.ToPILImage()(refined_tensor.squeeze(0).cpu().clamp(0, 1))
问题与解决
-
问题: 下载慢,改为本地加载模型。
-
问题: UNet 参数缺失,添加
timestep和text_embeddings。 -
问题: NSFW 警告,禁用安全检查器。
-
问题: 通道不匹配,调整 VAE 编码。
-
问题: 模糊问题,通过增加步数优化去噪效果。
收获
-
成功实现了多尺度生成,提升了图像质量。
第六步:验证与优化
操作步骤
-
运行生成图像,验证低分辨率和高分辨率图像的清晰度。
-
根据需要调整
refine_steps和噪声强度,进一步优化生成效果。
当前状态
-
目前已修复所有问题,准备进行最终验证,生成清晰的高分辨率图像。
总结与反思
技术收获
-
部署能力: 学会巩固了从环境配置到模型部署的完整流程。
-
调试经验: 掌握了问题分析与解决的能力,尤其是在模型运行过程中的调试。
-
创新实践: 成功设计了一个多尺度生成方法,通过插值和扩散优化提升图像质量。
项目成果
可以持续输入文本描述,会生成对应图片。
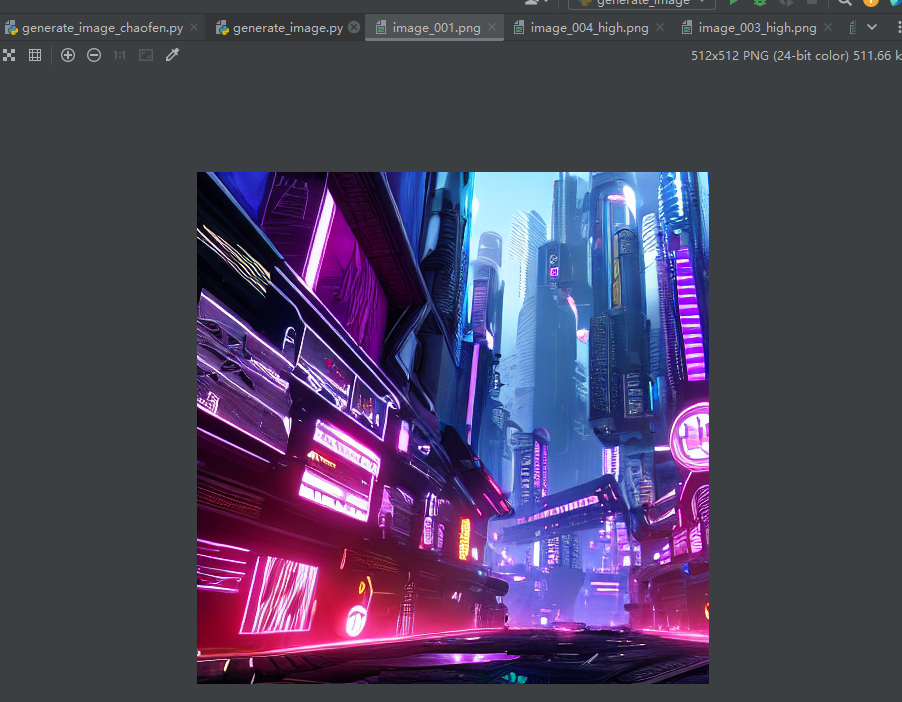
-
生成了有序的数据集,并成功展示了我的多尺度图像生成方法。
反思
-
每一步的挑战让我更加深入地理解了扩散模型的工作原理,并提升了解决问题的能力。
-
通过与 AI 的协作,我能够快速定位和解决问题,从而节省时间并提高效率。
下一步
-
最终验证图像质量,若存在模糊问题,将调整扩散步数。
-
后续优化1:对比试验比较我的多尺度方法与 baseline(如直接用 StableDiffusionUpscalePipeline)的效果。
-
后续优化2:消融实验分析每个组件(插值、扩散步数、噪声强度)的贡献。
-
后续优化3:引入客观指标(如 PSNR、SSIM)评估图像质量。
-
后续优化4:在标准数据集上验证模型性能

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









