






目录
Multi-scale Isometric Convolution(MIC) Layer
Abstracts
The title of the paper I read this week is "MICN: Multi scale Local and Global Context Modeling for Long term Series Forecasting", which includes the oral of the 2023 ICLR. Another article on long-term series prediction, but it is a model based on time-domain convolution module rather than Transformer. The motivation of this article is twofold: first, extract local features of the time series, and then extract the correlations between all local features to obtain global features, modeling from the perspectives of Local and Global; When modeling global features, we do not use high complexity attention, but instead use newly proposed modules.
摘要
本周阅读的论文题目是《MICN: Multi-scale Local and Global Context Modeling for Long-term Series Forecasting》,本文中了2023 ICLR的oral。又是一篇长时间序列预测的文章,但是它是一个基于时域卷积模块的模型,而不是基于Transformer的模型。本文的动机有两点:先提取时间序列的局部特征,然后再提取所有局部特征之间的关联性,进而得到全局特征,从Local和Global的角度建模;在建模全局特征时,不采用复杂度高的attention,而是采用新提出来的模块。
Key Points
MICN模型总览
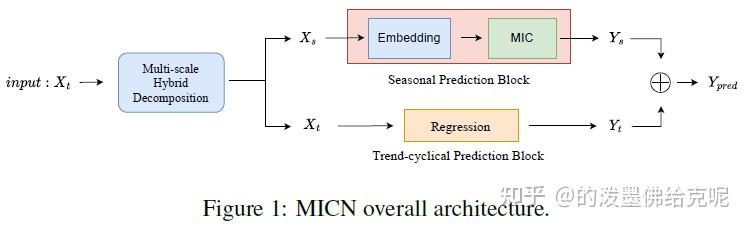
先是将输入序列送到多尺度混合分解模块中进行序列分解,得到Seasonal项和Trend-Cyclical项,分别对两者独立进行预测,最后将预测结果加起来。对于Trend-Cyclical项,直接采用线性回归的方式,即Trend-Cyclical Prediction Block就是一个线性层,因此下面不再介绍;对于Seasonal项,采用提出的MIC层进行预测。
多尺度混合分解
首先是如何将原始输入序列进行分解得到Trend-Cyclical项和Seasonal项。作者也是采用了和AutoFormer比较相似的,用平均池化得到Trend-Cyclical项,然后原始序列减去Trend-Cyclical项就得到了Seasonal项。考虑到平均池化的kernel大小控制着分解的不同模式,因此作者综合多个kernel的平均池化结果,将这些结果再取一个平均,得到Trend-Cyclical项:
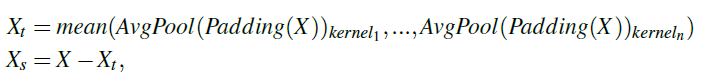
其实这个方式几乎和FEDformer的混合专家分解块(MOEDecomp)是一模一样的,只不过MOEDecomp是对多个kernel的平均池化结果进行加权平均,而本文是直接平均。
Seasonal Prediction Block
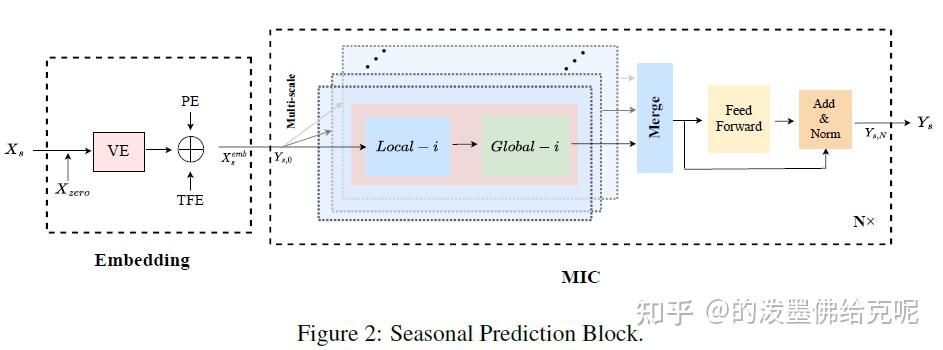
季节预测模块首先对输入进行Embedding,其次使用 N 个堆叠的MIC层预测未来。每个MIC层中,有多个代表不同尺度的Branch,如上图中浅蓝色部分所示。每个branch实际上就是一个Local-Global模块,在下一节中将具体介绍。对于每一个MIC层,输入首先通过多个branch中的Local-Global模块,然后不同branch的结果会合并起来,相当于融合多尺度信息,最后馈送到FFN和Add&Norm,即得到该MIC层的输出。
Multi-scale Isometric Convolution(MIC) Layer
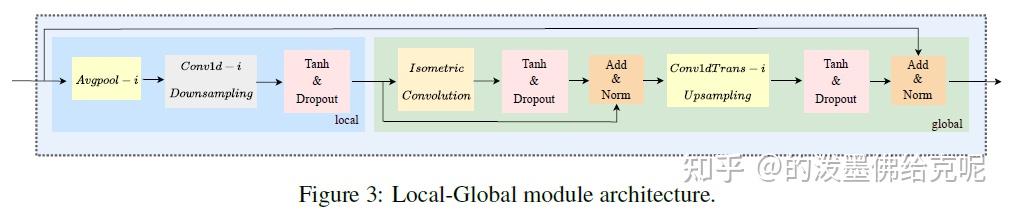
对于每一个MIC层,本节详细介绍其中的Local-Global模块。Local-Global模块由聚合局部特征的Local模块和建模所有局部特征之间的关系的Global模块串联而成。
对于Local模块,首先使用kernel大小为 i 的平均池化进行滤波,然后使用kernel大小为 i,stride大小也为 i 的1D时域卷积来进行降采样(这相当于将序列长度缩小了 i 倍)。作者认为,这样相当于把每 i 个相邻的时间点特征聚合成了一个局部特征。
对于Global模块,它的输入实际上就是降采样后的序列,也就是局部特征的序列。于是,作者提出了Isometric Convolution来建模这些局部特征的全局关系。之后,利用1D转置卷积进行上采样,将序列长度扩大了 i 倍,也就是再恢复到原始的长度。下图是Isometric Convolution和masked self-attention的对比。可以看到,Isometric Convolution就是把长度为 S 的序列从头部再填充 S−1 的长度,然后利用kernel大小为 S 的1D卷积来直接处理即可。我认为Isometric Convolutio实际上就是kernel大小等于整个序列长度的因果卷积,换汤不换药,就是换了个名字。对于每个输出,只能看到位于该输出前面时刻的那些输入。
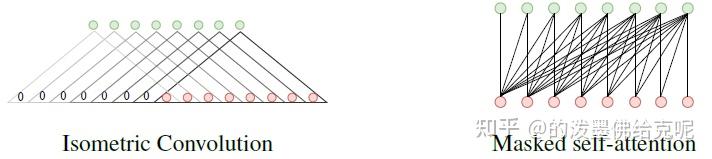
那多尺度,也就是上一节提到的多个Branch是如何实现的呢?很简单,对于不同的branch,采用不同的参数 i 即可。
实验结果
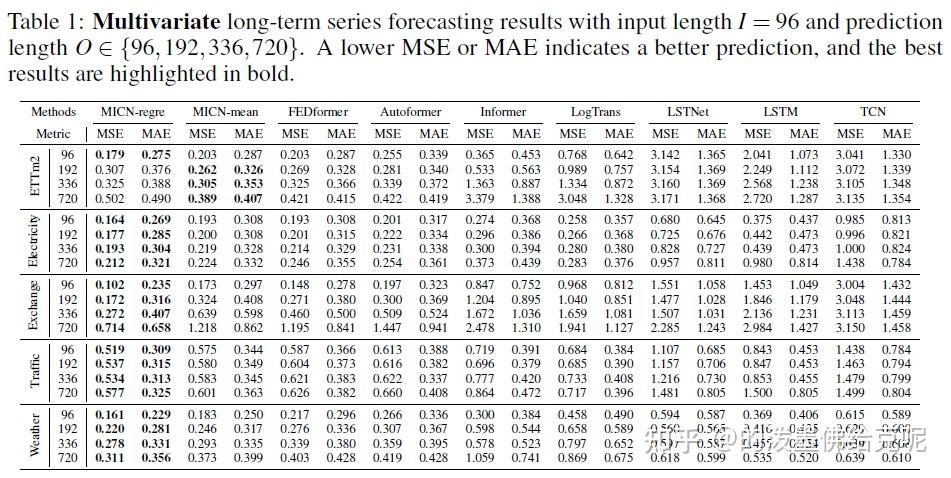
主要结果
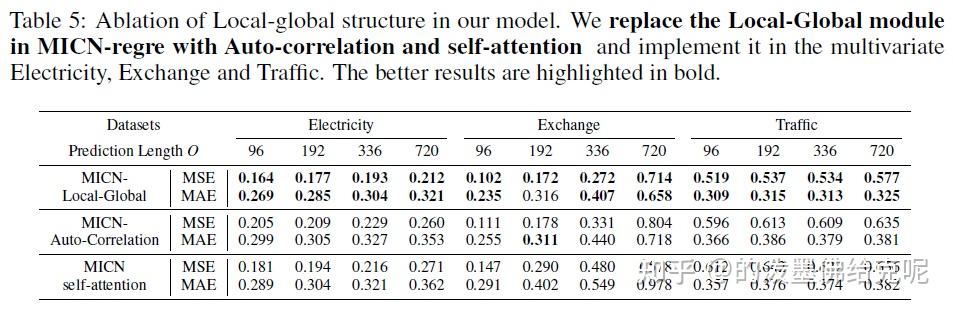
Local-Global模块的消融
Comments
本文消融实验比较完备,模型结构也蛮合理。提出的isometric convolution来替代masked self-attention是本文最主要的创新点,但它就是因果卷积换了个皮,而且不太清楚为什么要用这种因果卷积的形式,因为模型的输入本身就不包括未来序列,未来序列是以填充0的方式输入到模型中的,并不需要防止信息泄露。事实上,在很多基于Transformer的时序预测论文都不用因果mask了,以及基于TCN的模型如SCINet认为TCN中的因果卷积不但没有必要,反而自我限制了对时序信息的提取能力。模型的效果虽然超过了一些Transformer的模型,但和另一些方法如DLinear比还是有一些差距的。在openreview上可以看到该文章以668的得分中了oral,但老实说我觉得远不够oral的门槛,可能是PC觉得实验比较充分吧。

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









