






Denoising Diffusion Probabilistic Models
1 简介
DDPM:Denoising Diffusion Probabilistic Models
去噪扩散模型就是图像生成模型
1.1 大白话版本
简单来说,它就像是一个神奇的“画图机器人”,能根据你的要求生成各种图片、音频或者其他类型的数据。
假如你有一张非常干净的画,但是有人故意在上面加了很多乱七八糟的“噪声”(比如涂鸦、污点等),把这幅画弄得面目全非。DDPM的工作原理就像把这张被破坏的画恢复成原来的模样。
扩散过程:DDPM会从一个完全随机的噪声开始。就像你有一张照片,我们把颜料随机地涂在纸上。这个过程会持续很多步,每一步都会让噪声变得更复杂,直到最后变成一个完全看不出原来模样的东西。
去噪过程:接下来,DDPM开始“去噪”。它会从这个完全混乱的状态开始,一步步地把噪声去掉,就像你小心翼翼地擦掉画上的污点一样。每一步都会让图像变得更清晰一点,直到最后恢复出一个干净的、有意义的图像。
本质上来讲是一个生成模型,去拟合拟目标的分布,然后去生成很多数据符合这个分布。
1.2 简易版本
去噪扩散模型大体包括两个过程,一是对真实图像进行扩散过程,二是对加噪的图像进行重建去噪。
扩散过程:
向真实图片数据中逐步加入噪声,直到观测数据变成高斯分布。
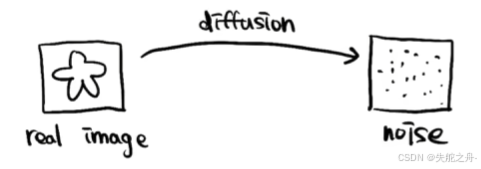
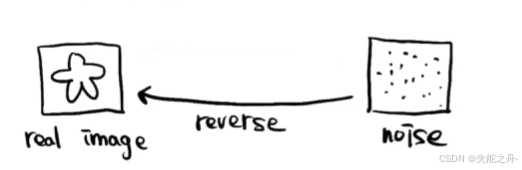
重建(去噪)过程:
从一个高斯分布中采样,逐步消除噪声,直到变成清晰的数据。
1.2.1 例子
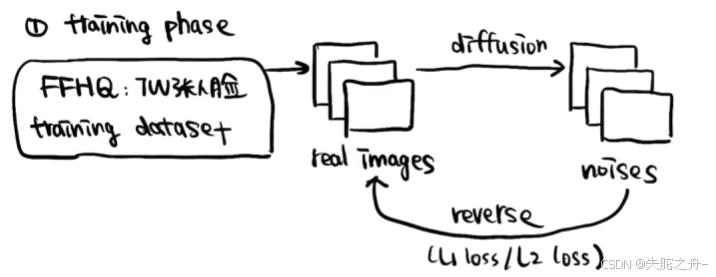
①训练过程
FFHQ(dataset)数据集里面包含7万张人脸,DDPM会先对这些真实的人脸图片逐步添加噪声。
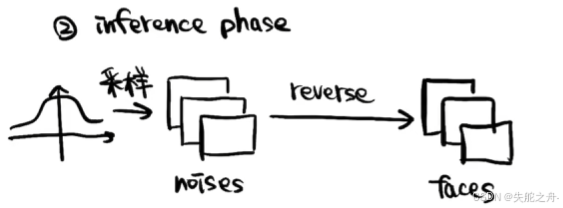
②推理过程
高斯分布里面采样很多的噪声图,把这些噪声图重建reverse,DDPM会不断调整自己的参数,让去噪的效果越来越好,就可以得到很多人脸图片。
1.3 扩散模型相比GAN
GAN(Generative Adversarial Networks)也是生成模型
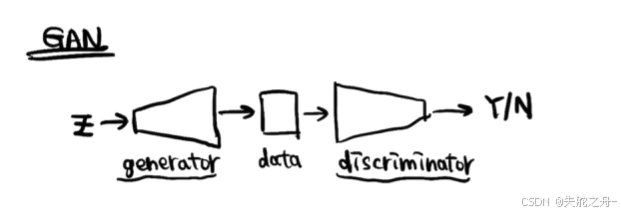
打个不恰当的例子,GAN类似于警察抓小偷的过程中,警察不断增强自己的技能和本领,然而小偷在这个过程中也在不断学习逃跑的方法,警察通过小偷的行为又采取进一步的学习,二者总是在相互制衡。
GAN由生成器(Generator)和判别器(Discriminator)组成。生成器负责生成假数据,判别器负责区分真假数据。生成器不断学习生成更逼真的数据,判别器则不断学习更好地识别真假数据,所以说GAN是不太稳定的过程。
2 扩散阶段diffusion
把一张真实的图像不断的加噪声,噪声强度不断变大,最后得到一个完全的噪声图。
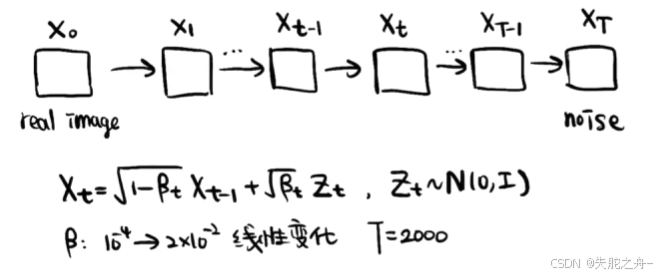
X
t
=
1
−
β
t
X
t
−
1
+
β
t
Z
t
{X}_{t}=\sqrt{1-{\beta }_{t}}{X}_{t-1}+\sqrt{{\beta }_{t}} {Z}_{t}
Xt=1−βtXt−1+βtZt
Z
t
∽
N
(
0
,
I
)
{Z}_{t} \backsim N(0,I)
Zt∽N(0,I)
我们可以把上述方程看作
X
t
=
f
(
X
t
−
1
)
{X}_{t}=f({X}_{t-1})
Xt=f(Xt−1)
因为扩散速度是越来越快的,所以 β t {\beta }_{t} βt是逐渐增大的

3 DDPM实现过程
输入值:X(图像),t(时间点)
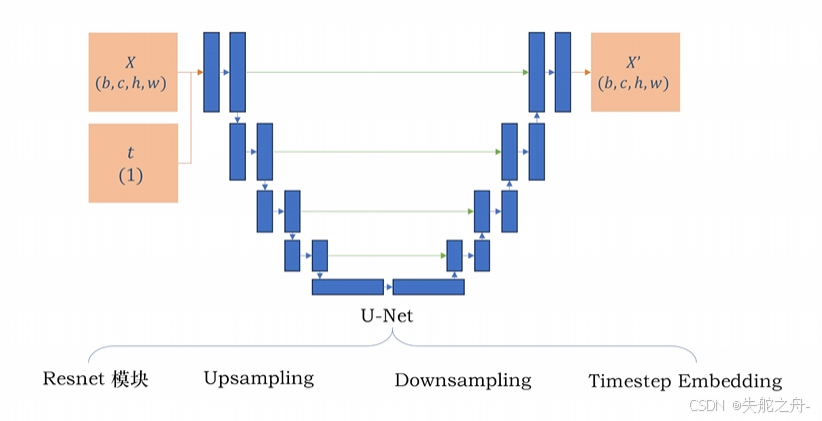
3.1 正向过程
1.我们往图片上添加的噪声是以0为均值,我们把图像缩放到[-1,1]的范围里面去
2.设置β,根据β计算α和
α
ˉ
\bar{α}
αˉ
3.采样高斯噪声
ϵ
∽
N
(
0
,
1
)
\epsilon \backsim N(0,1)
ϵ∽N(0,1),选取时间点t对图像进行加噪
4.预测加以图像的噪声
3.2 反向过程
1.根据模型预测噪声
2.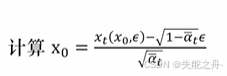 ,t越小预测的图像越清楚
,t越小预测的图像越清楚
3.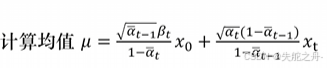
4.计算方差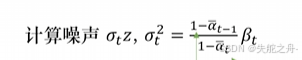
5.根据均值和噪声合成图像
4 项目链接
比较简单的玩具项目代码:https://github.com/abarankab/DDPM
比较实用的项目代码:https://github.com/Janspiry/Image-Super-Resolution-via-Iterative-Refinement


















 2626
2626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











