






前言
Pose2Seg人体实例分割框架,它不依赖于传统的目标检测方法,而是直接利用人体姿态信息来区分和分割图像中的个体。这一方法特别适用于处理人体重叠和遮挡的情况。
该Pose2Seg框架通过一个称为Affine-Align的对齐模块,基于人体姿态而非边界框来对齐区域,从而提高了分割精度。此外,框架还融合了人工骨架特征,以增强网络对重叠人体的区分能力。
一、环境配置
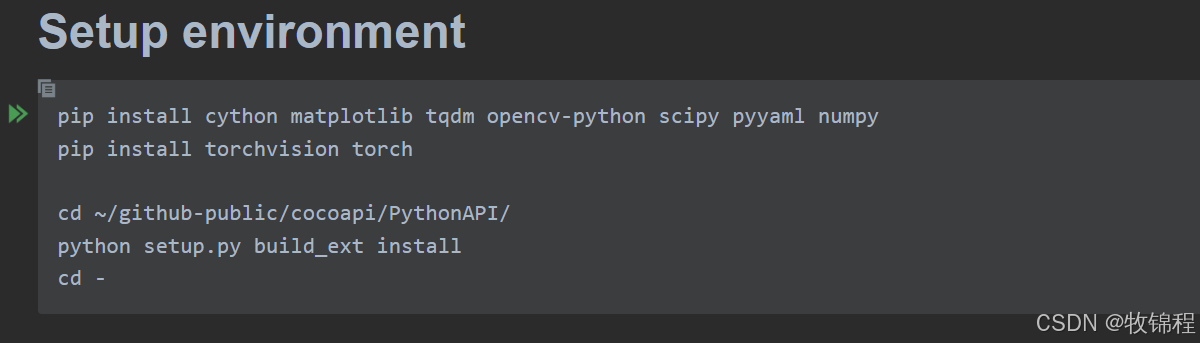
创建专属环境
conda create -n pose2seg python==3.9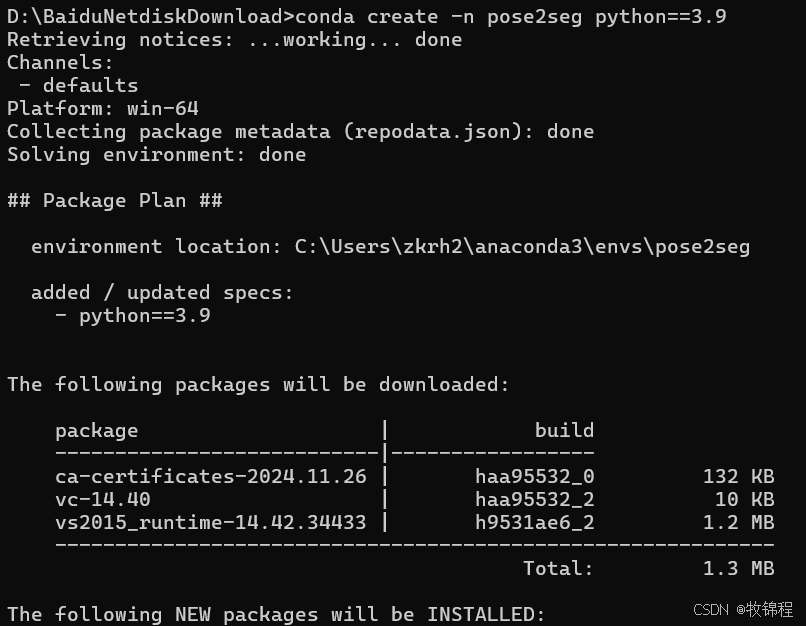
激活环境
conda activate pose2seg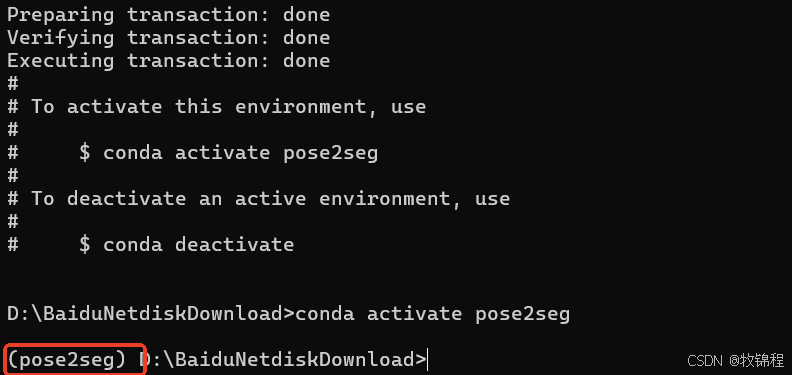
安装 Pytorch 环境
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "torch-2.3.0+cu118-cp39-cp39-win_amd64.whl"安装相关库
pip install cython matplotlib tqdm opencv-python scipy pyyaml numpy -i https://pypi.tuna.tsinghua.edu.cn/simple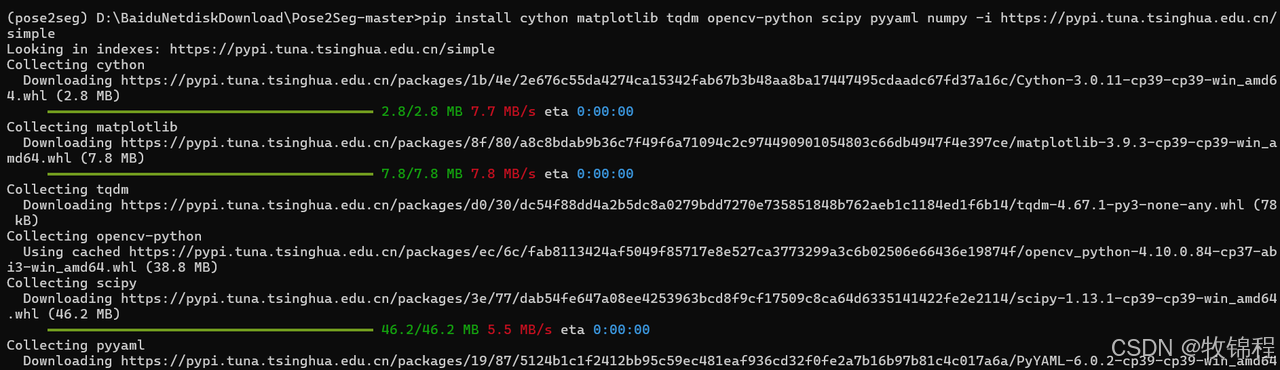
二、代码测试
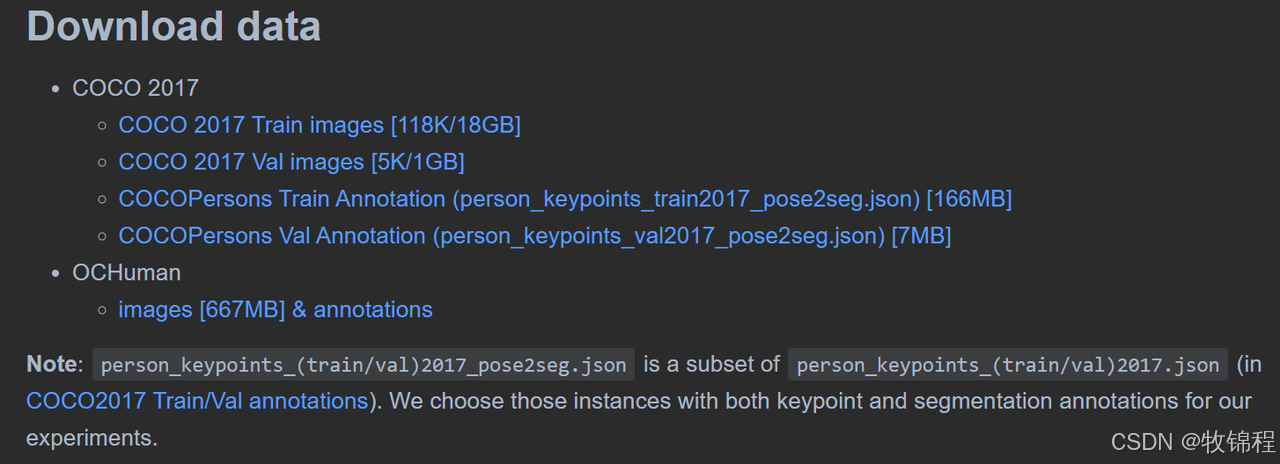
数据集下载
整体验证
python infer.pyparser = argparse.ArgumentParser(description="Pose2Seg Testing")
parser.add_argument(
"--cuda",
default=True,
help="use gpu",
type=bool,
)
parser.add_argument(
"--weights",
default='./imagenet_pretrain/pose2seg_release.pkl',
help="path to .pkl model weight",
type=str,
)
parser.add_argument(
"--coco",
help="Do test on COCOPersons val set",
action="store_true",
)
parser.add_argument(
"--OCHuman",
default=True,
help="Do test on OCHuman val&test set",
action="store_true",
)
args = parser.parse_args()Loading and preparing results...
DONE (t=0.06s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type segm
DONE (t=0.58s).
Accumulating evaluation results...
DONE (t=0.13s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.557
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.945
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.599
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.090
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.560
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.401
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.666
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.666
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.443
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.666
[POSE2SEG] AP|.5|.75| S| M| L| AR|.5|.75| S| M| L|
[segm_score] OCHumanVal 0.557 0.945 0.599 -1.000 0.090 0.560 0.401 0.666 0.666 -1.000 0.443 0.666
loading annotations into memory...
Done (t=0.06s)
creating index...
index created!
100%|██████████| 2231/2231 [01:30<00:00, 24.64it/s]
Loading and preparing results...
DONE (t=0.05s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type segm
DONE (t=0.55s).
Accumulating evaluation results...
DONE (t=0.07s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.551
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.932
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.601
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.554
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.401
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.666
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.666
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.666
[POSE2SEG] AP|.5|.75| S| M| L| AR|.5|.75| S| M| L|
[segm_score] OCHumanTest 0.551 0.932 0.601 -1.000 -1.000 0.554 0.401 0.666 0.666 -1.000 -1.000 0.666
模型代码解释
_setInputs函数
_setInputs函数的作用是处理输入数据,包括图像、关键点和掩码,并在训练模式下对关键点和掩码进行采样,以确保不超过最大实例数。
def _setInputs(self, batchimgs, batchkpts=None, batchmasks=None):
# batchimgs: a list of array (H, W, 3) 图片
# batchkpts: a list of array (m, 17, 3) 关键点
# batchmasks: a list of array (m, H, W) 掩码
self.batchimgs = batchimgs
self.batchkpts = batchkpts
self.batchmasks = batchmasks
self.bz = len(self.batchimgs)
# sample
if self.training:
# 创建了一个包含所有关键点索引的列表,其中每个索引是一个元组(i, j),i表示图像的索引,j表示该图像中关键点的索引。
ids = [(i, j) for i, kpts in enumerate(batchkpts) for j in range(len(kpts))]
# 检查关键点的总数是否超过了self.MAXINST定义的最大实例数
if len(ids) > self.MAXINST:
select_ids = random.sample(ids, self.MAXINST)
# 用于存储每个图像选择的关键点索引
indexs = [[] for _ in range(self.bz)]
for id in select_ids:
indexs[id[0]].append(id[1])
# 遍历每个图像的关键点和掩码,只保留选择的关键点和对应的掩码
for i, (index, kpts) in enumerate(zip(indexs, self.batchkpts)):
self.batchkpts[i] = self.batchkpts[i][index]
self.batchmasks[i] = self.batchmasks[i][index]_calcNetInputs函数
_calcNetInputs函数的作用是将输入图像调整到网络期望的尺寸和格式,包括尺寸调整、颜色通道转换和数据类型转换。
def _calcNetInputs(self):
# 对每张图像计算一个变换矩阵,这个矩阵将图像从原始尺寸变换到512x512的尺寸
self.inputMatrixs = [translib.get_aug_matrix(img.shape[1], img.shape[0], 512, 512,
angle_range=(-0., 0.),
scale_range=(1., 1.),
trans_range=(-0., 0.))[0] \
for img in self.batchimgs]
# 对每张图像进行仿射变换,将它们调整到512x512的尺寸
inputs = [cv2.warpAffine(img, matrix[0:2], (512, 512)) \
for img, matrix in zip(self.batchimgs, self.inputMatrixs)]
if len(inputs) == 1:
inputs = inputs[0][np.newaxis, ...]
else:
inputs = np.array(inputs)
inputs = inputs[..., ::-1]
inputs = inputs.transpose(0, 3, 1, 2)
inputs = inputs.astype('float32')
self.inputs = inputs_calcAlignMatrixs函数
_calcAlignMatrixs函数的主要作用是计算关键点的对齐矩阵,这些矩阵将用于后续的特征提取和掩码对齐步骤。
def _calcAlignMatrixs(self):
# 1. transform kpts to feature coordinates. 将关键点(kpts)转换到特征坐标系中。
# 2. featAlignMatrixs (size feature -> size align) used by affine-align 计算featAlignMatrixs,用于将特征尺寸对齐到对齐尺寸。
# 3. maskAlignMatrixs (size origin -> size output) used by Reverse affine-align 计算maskAlignMatrixs,用于将原始尺寸的掩码对齐到输出尺寸。
# matrix: size origin ->(m1)-> input ->(m2)-> feature ->(m3(mAug))-> align ->(m4)-> output
size_input = self.size_input
size_feat = self.size_feat
size_align = self.size_align
size_output = self.size_output
# 计算两个步长矩阵m2和m4,分别用于将图像从输入尺寸调整到特征尺寸,以及从对齐尺寸调整到输出尺寸。
m2 = translib.stride_matrix(size_feat / size_input)
m4 = translib.stride_matrix(size_output / size_align)
# 存储每个批次中每个图像的对齐矩阵
self.featAlignMatrixs = [[] for _ in range(self.bz)]
self.maskAlignMatrixs = [[] for _ in range(self.bz)]
# 用于存储骨架特征
if self.cat_skeleton:
self.skeletonFeats = [[] for _ in range(self.bz)]
for i, (matrix, kpts) in enumerate(zip(self.inputMatrixs, self.batchkpts)):
m1 = matrix
# transform gt_kpts to feature coordinates.
# 将关键点应用变换矩阵m2.dot(m1),将它们从原始坐标系转换到特征坐标系
kpts = translib.warpAffineKpts(kpts, m2.dot(m1))
# 每个关键点初始化两个空的对齐矩阵
self.featAlignMatrixs[i] = np.zeros((len(kpts), 3, 3), dtype=np.float32)
self.maskAlignMatrixs[i] = np.zeros((len(kpts), 3, 3), dtype=np.float32)
# 为每个关键点初始化一个空的骨架特征矩阵
if self.cat_skeleton:
self.skeletonFeats[i] = np.zeros((len(kpts), 55, size_align, size_align), dtype=np.float32)
for j, kpt in enumerate(kpts):
timers['2'].tic()
# best_align: {'category', 'template', 'matrix', 'score', 'history'}
# 每个关键点找到最佳的对齐方式
best_align = self.poseAlignOp.align(kpt, size_feat, size_feat,
size_align, size_align,
visualize=False, return_history=False)
# aug
if self.training:
mAug, _ = translib.get_aug_matrix(size_align, size_align,
size_align, size_align,
angle_range=(-30, 30),
scale_range=(0.8, 1.2),
trans_range=(-0.1, 0.1))
m3 = mAug.dot(best_align['matrix'])
else:
m3 = best_align['matrix']
self.featAlignMatrixs[i][j] = m3
self.maskAlignMatrixs[i][j] = m4.dot(m3).dot(m2).dot(m1)
# 合并骨架特征
if self.cat_skeleton:
# size_align (sigma=3, threshold=1) for size_align=64
self.skeletonFeats[i][j] = genSkeletons(translib.warpAffineKpts([kpt], m3),
size_align, size_align,
stride=1, sigma=3, threshold=1,
visdiff=True).transpose(2, 0, 1)_forward函数
_forward函数是模型的前向传播过程,它处理输入数据,通过骨干网络和分割网络,最终输出分割掩码。在训练模式下,它还会计算损失函数。
def _forward(self):
#########################################################################################################
# If we use `pytorch` pretrained model, the input should be RGB, and normalized by the following code:
# normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225])
# Note: input[channel] = (input[channel] - mean[channel]) / std[channel], input is (0,1), not (0,255)
#########################################################################################################
if self.gpu:
inputs = (torch.from_numpy(self.inputs).cuda() / 255.0 - self.mean) / self.std
else:
inputs = (torch.from_numpy(self.inputs) / 255.0 - self.mean) / self.std
# 获取不同阶段的特征图
[p1, p2, p3, p4] = self.backbone(inputs)
# 选择骨干网络的第一个特征图(p1)作为后续步骤的输入特征
feature = p1
# 将特征对齐矩阵和索引合并为两个大的NumPy数组,以便后续批量处理
alignHs = np.vstack(self.featAlignMatrixs)
indexs = np.hstack([idx * np.ones(len(m), ) for idx, m in enumerate(self.featAlignMatrixs)])
# 对特征图进行仿射对齐,得到ROI(感兴趣区域)特征
rois = affine_align_gpu(feature, indexs, (self.size_align, self.size_align), alignHs, self.gpu)
# 将骨架特征与ROI特征拼接在一起
if self.cat_skeleton:
skeletons = np.vstack(self.skeletonFeats)
if self.gpu:
skeletons = torch.from_numpy(skeletons).float().cuda()
else:
skeletons = torch.from_numpy(skeletons).float()
rois = torch.cat((rois, skeletons), 1)
# 将拼接后的特征传递给分割网络(self.segnet)进行处理
netOutput = self.segnet(rois)
if self.training:
# 计算损失函数
loss = self._calcLoss(netOutput)
return loss
else:
netOutput = F.softmax(netOutput, 1)
netOutput = netOutput.detach().data.cpu().numpy()
# 获取最终的掩码输出
# _getMaskOutput函数的作用是将网络的输出转换为每个关键点对应的二值化掩码,并将其映射回原始图像空间。这些掩码可以用于后续的评估或可视化。
output = self._getMaskOutput(netOutput)
if self.visCount < 0:
# 可视化输出结果
self._visualizeOutput(netOutput)
self.visCount += 1
return output_getMaskOutput函数
_getMaskOutput函数的作用是将网络的输出转换为每个关键点对应的二值化掩码,并将其映射回原始图像空间。这些掩码可以用于后续的评估或可视化。
def _getMaskOutput(self, netOutput):
netOutput = netOutput.transpose(0, 2, 3, 1)
MaskOutput = [[] for _ in range(self.bz)]
idx = 0
for i, (img, kpts) in enumerate(zip(self.batchimgs, self.batchkpts)):
height, width = img.shape[0:2]
for j in range(len(kpts)):
# 获取当前关键点的预测图。
predmap = netOutput[idx]
# 获取当前关键点的反向对齐矩阵,用于将预测图映射回原始图像空间。
H_e2e = self.maskAlignMatrixs[i][j]
# 使用反向对齐矩阵H_e2e将预测图predmap变换回原始图像尺寸(width, height)。cv2.WARP_INVERSE_MAP标志表示逆变换,cv2.INTER_LINEAR表示线性插值。
pred_e2e = cv2.warpAffine(predmap, H_e2e[0:2], (width, height),
borderMode=cv2.BORDER_CONSTANT,
flags=cv2.WARP_INVERSE_MAP + cv2.INTER_LINEAR)
pred_e2e = pred_e2e[:, :, 1]
pred_e2e[pred_e2e > 0.5] = 1
pred_e2e[pred_e2e <= 0.5] = 0
mask = pred_e2e.astype(np.uint8)
MaskOutput[i].append(mask)
idx += 1
return MaskOutputvisualize函数
_visualizeOutput函数的主要作用是将网络的输出(预测掩码)与真实掩码进行可视化比较,并计算IoU值,以评估模型的性能。
def _visualizeOutput(self, netOutput):
outdir = './vis/'
netOutput = netOutput.transpose(0, 2, 3, 1)
MaskOutput = [[] for _ in range(self.bz)]
# 创建一个步长矩阵mVis,用于后续的可视化变换
mVis = translib.stride_matrix(4)
idx = 0
for i, (img, masks) in enumerate(zip(self.batchimgs, self.batchmasks)):
height, width = img.shape[0:2]
for j in range(len(masks)):
# 获取当前掩码的预测图
predmap = netOutput[idx]
# 预测图中提取第二个通道(索引为1的通道)
predmap = predmap[:, :, 1]
predmap[predmap > 0.5] = 1
predmap[predmap <= 0.5] = 0
predmap = cv2.cvtColor(predmap, cv2.COLOR_GRAY2BGR)
# 将预测图应用步长矩阵mVis变换,并调整到256x256的尺寸
predmap = cv2.warpAffine(predmap, mVis[0:2], (256, 256))
# 获取当前掩码的对齐矩阵,并应用步长矩阵mVis
matrix = self.maskAlignMatrixs[i][j]
matrix = mVis.dot(matrix)
# 将原始图像应用对齐矩阵变换,并调整到256x256的尺寸
imgRoi = cv2.warpAffine(img, matrix[0:2], (256, 256))
# 将原始掩码应用对齐矩阵变换,并调整到256x256的尺寸,然后转换为BGR颜色空间
mask = cv2.warpAffine(masks[j], matrix[0:2], (256, 256))
mask = cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR)
# 计算预测掩码和真实掩码的交集(I)、并集(U)以及交并比(IoU)
I = np.logical_and(mask, predmap)
U = np.logical_or(mask, predmap)
iou = I.sum() / U.sum()
# 调整尺寸后的图像ROI、掩码和预测掩码水平堆叠在一起,用于可视化
vis = np.hstack((imgRoi, mask * 255, predmap * 255))
cv2.imwrite(outdir + '%d_%d_%.2f.jpg' % (self.visCount, j, iou), np.uint8(vis))
idx += 1三、总结
关于Pose2Seg模型的相关代码、论文PDF、预训练模型、使用方法等,我都已打包好,供需要的小伙伴交流研究,获取方式如下:
关注公众号,回复:论文源码,即可获取相关代码、论文、预训练模型、使用方法示例等


















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











