






论文:https://arxiv.org/pdf/1911.08947.pdf
代码:我使用的是 https://github.com/WenmuZhou/DBNet.pytorch(非官方)
- 此次使用的是ICDAR2015数据集,下次使用Total-Text、MSRA-TD500、CTW1500等其他数据集。而且这些数据集有的标注文件和ICDAR2015不一样,有的不是4个点的坐标(是多点坐标),还没学会如何转换和进行训练,有大神了解的话可以在评论留言,感谢!
- 还没进行测试。
- 继续更新遇到的问题。
1. DBNet模型结构
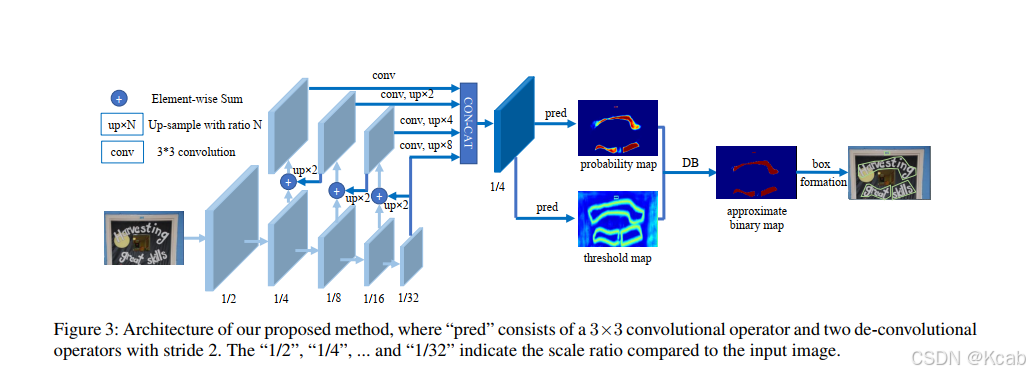
2. 错误修改
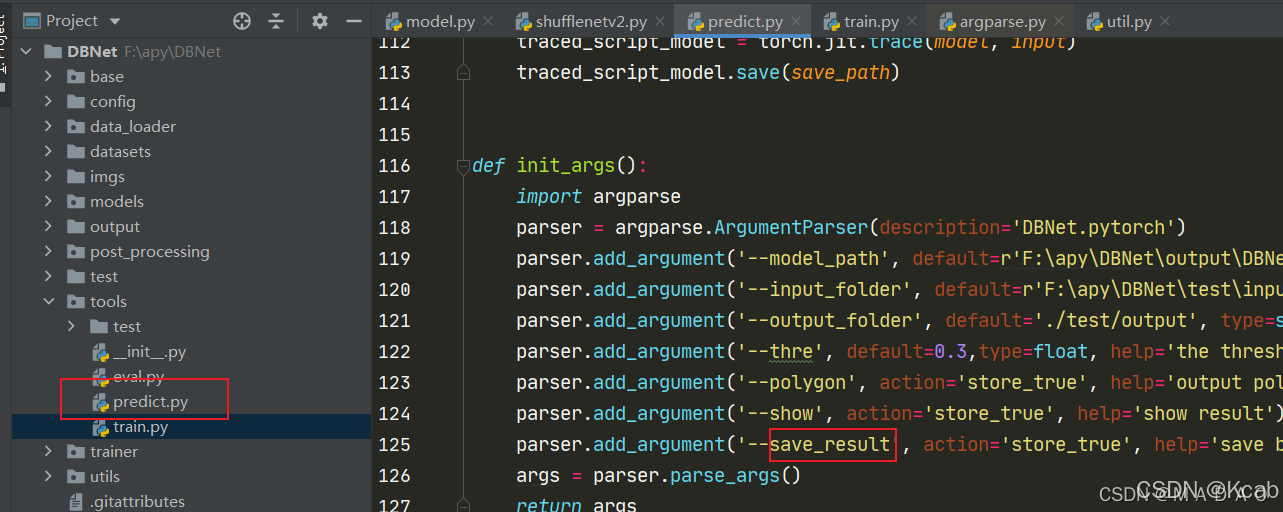
由于作者输入有误,需要在代码中做部分修改
将 ’–save_resut’ 修改为 ’–save_result’
3. 环境配置
3.1 先从上面给的代码连接下载代码,进行解压,导入到pycharm,然后安装缺少的包
3.1.1 通过 requirement.txt 文件安装
这里安装包可以通过 requirement.txt 安装
先 cd 到DBNet所在的文件路径下(我的是:D:\Pycharm\Code\DBNet),然后激活创建的虚拟环境( 比如我的:conda activate DBNet),然后执行:pip install -r requirement.txt
3.1.2 一个一个安装(我采用的方式)
也可以通过在 pycharm 的 Terminal 下面执行:
python tools/train.py --config_file "config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml"
进行安装。如果缺少包就会包错误,如果看不到错误,说明都安装了。
一个一个安装的话,推荐使用 conda 命令安装
https://blog.youkuaiyun.com/qq_46279541/article/details/144568361?spm=1001.2014.3001.5501
注:因为我使用的GPU是4090,安装python版本是3.9,且pytorch版本和cuda版本和readme的不一样,怕安装的包不合适,所以我进行一个一个安装。根据个人情况选择安装方式即可。**
3.2 安装过程中遇到的问题
3.2.1 在训练中还会出现 No module named ‘torchvision.models.utils‘ 错误,因此只需要将 from torchvision.models.utils import load_state_dict_from_url 改为 from torch.hub import load_state_dict_from_url 即可 (我也遇到了这个问题,该方法有用)

3.2.2 安装有的包可能会出现问题:比如 Polygon,可以使用一下方法
pip install Polygon3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install addict
pip install imgaug
3.3 数据集使用的是ICDAR2015
3.3.1 数据集下载及放到相应位置
连接:https://rrc.cvc.uab.es/?ch=4&com=tasks
选择Task 4.1: Text Localization,下载即可,需要使用邮箱注册。
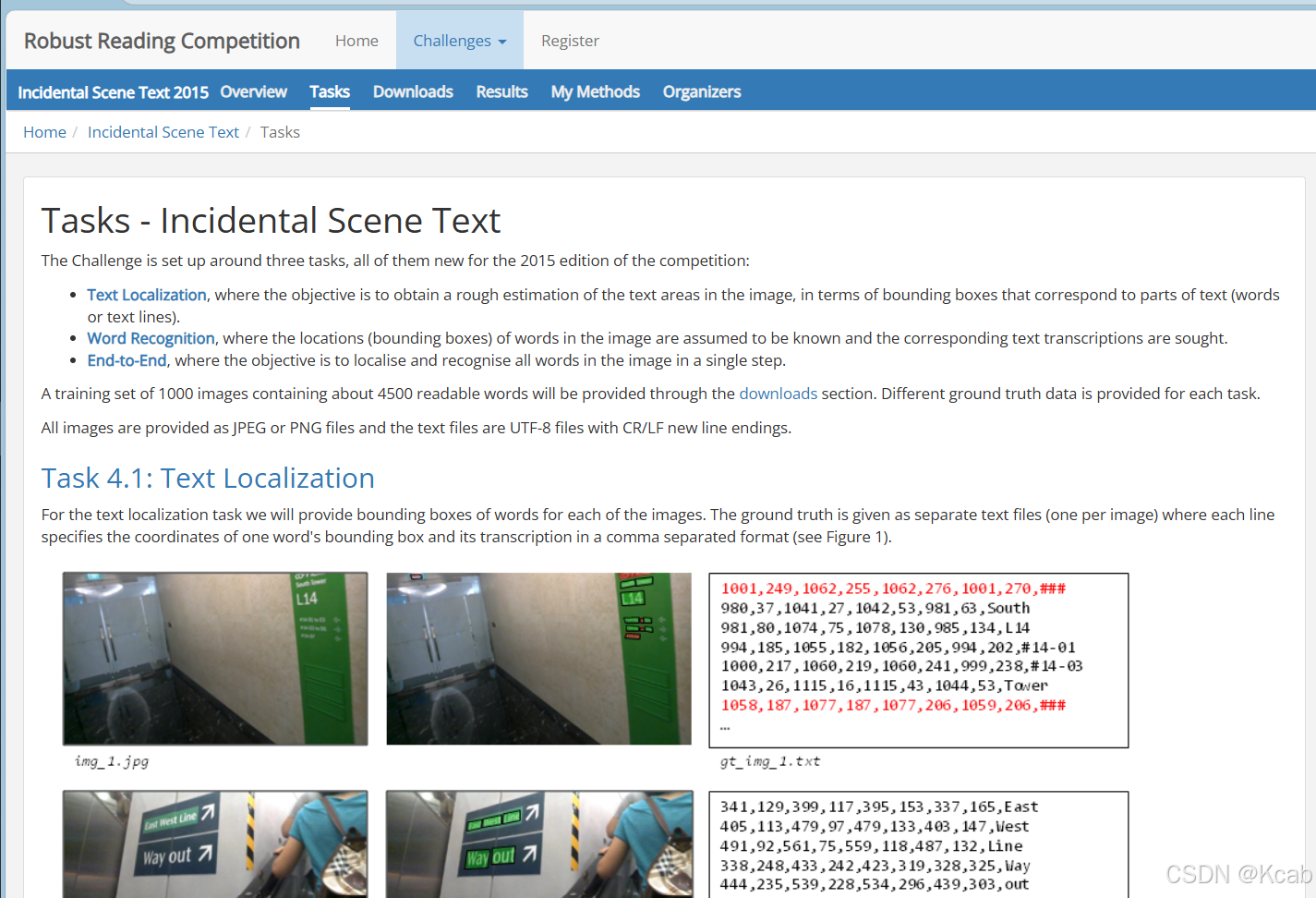
下载好后解压到相应文件夹,
将ch4_training_images.zip解压到./datasets\train\img下面。
将ch4_training_localization_transcription_gt.zip解压到./datasets\train\gt下面。
将ch4_test_images.zip解压到./datasets\test\img下面。
将Challenge4_Test_Task1_GT.zip解压到./datasets\test\gt下面。
ICDAR2015 数据的标注:文本文件是逗号分隔的文件,其中每一行将对应于图像中的一个单词,并给出其边界框坐标(四个角,顺时针)及其格式的转录:
x1, y1, x2, y2, x3, y3, x4, y4, transcription
3.3.2 数据处理
接下来对数据集做预处理,作者写 Ubuntu 系统下的处理脚本generate_lists.sh,所以如果用的系统是 UBuntu,则执行脚本即可
bash generate_lists.sh
我使用的是 windows 系统,因此需要写python脚本。新建 getdata.py ,插入代码:
import os
def get_images(img_path):
'''
find image files in data path
:return: list of files found
'''
files = []
exts = ['jpg', 'png', 'jpeg', 'JPG', 'PNG']
for parent, dirnames, filenames in os.walk(img_path):
for filename in filenames:
for ext in exts:
if filename.endswith(ext):
files.append(os.path.join(parent, filename))
break
print('Find {} images'.format(len(files)))
return sorted(files)
def get_txts(txt_path):
'''
find gt files in data path
:return: list of files found
'''
files = []
exts = ['txt']
for parent, dirnames, filenames in os.walk(txt_path):
for filename in filenames:
for ext in exts:
if filename.endswith(ext):
files.append(os.path.join(parent, filename))
break
print('Find {} txts'.format(len(files)))
return sorted(files)
if __name__ == '__main__':
import json
img_train_path = r'F:\apy\DBNet\datasets\train\img\ch4_training_images'
img_test_path = r'F:\apy\DBNet\datasets\test\img\ch4_test_images'
train_files = get_images(img_train_path)
test_files = get_images(img_test_path)
txt_train_path = r'F:\apy\DBNet\datasets\train\gt\ch4_training_localization_transcription_gt'
txt_test_path = r'F:\apy\DBNet\datasets\test\gt\Challenge4_Test_Task1_GT'
train_txts = get_txts(txt_train_path)
test_txts = get_txts(txt_test_path)
n_train = len(train_files)
n_test = len(test_files)
assert len(train_files) == len(train_txts) and len(test_files) == len(test_txts)
# with open('train.txt', 'w') as f:
with open('./datasets/train.txt', 'w') as f:
for i in range(n_train):
line = train_files[i] + '\t' + train_txts[i] + '\n'
f.write(line)
with open('./datasets/test.txt', 'w') as f:
for i in range(n_test):
line = test_files[i] + '\t' + test_txts[i] + '\n'
f.write(line)
在代码中将路径修改为自己的文件路径即可:
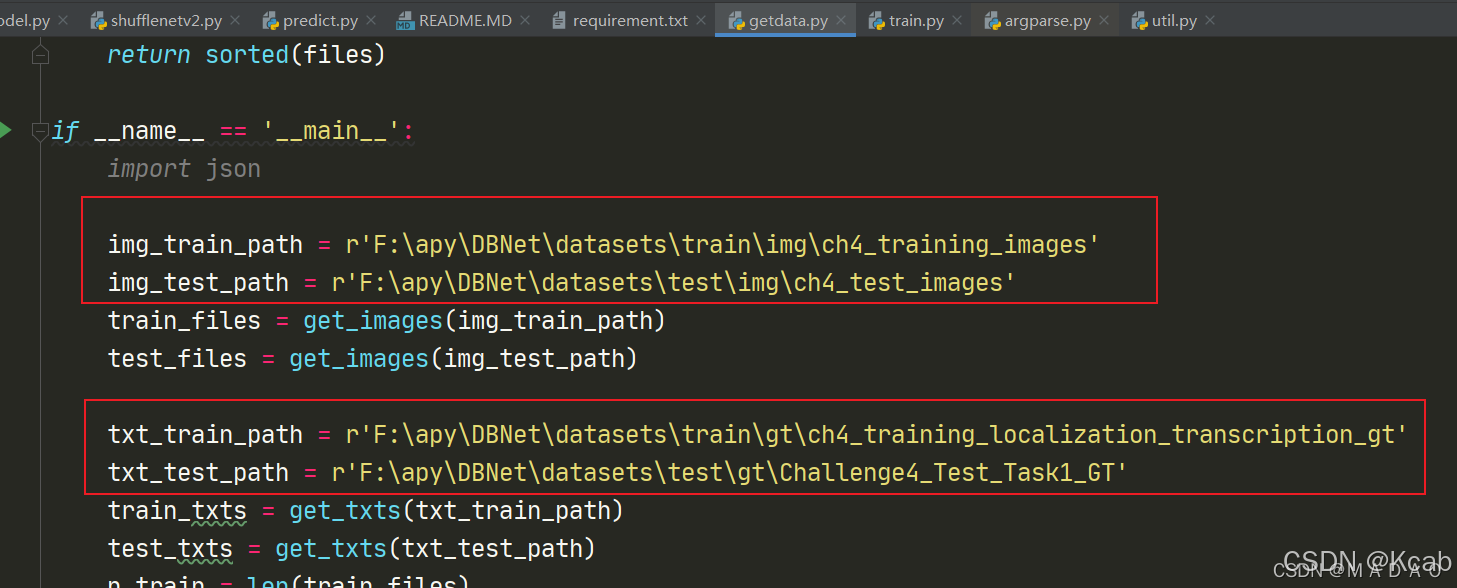
改完路径后运行创建的 getdata.py ,会得到 train.txt 和 test.txt 两个文件。
这里的 train.txt 和 test.txt 是图片和标注的绝对路径,有的代码是图片和标注的文件名字,我还没搞明白。
4. 训练
到这里已经完成大部分的工作了,只需要对config文件参数做适当的修改就可以开始训练了。
本次训练使用的config文件是./config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml,修改学习率、优化器、BatchSize等参数,如下图:
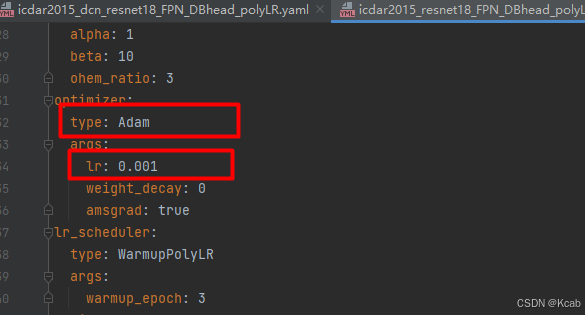
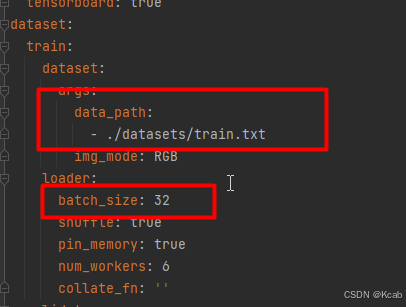
上面用红框标注的参数,大家根据实际的情况做修改,我的卡是4090,BatchSize设置32. 我只改了BatchSize一个参数。
参数设置完成后,就开启训练,在pycharm的Terminal下面执行:
如果是Ubuntu,可以执行:
CUDA_VISIBLE_DEVICES=0 python tools/train.py --config_file "config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml"
CUDA_VISIBLE_DEVICES=0 是设置GPU卡号的
Windows中执行:
set CUDA_VISIBLE_DEVICES=0 # 也是设置GPU卡号的
python tools/train.py --config_file "config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml"
这里我踩了,环境配好后,光标一直闪,不出信息,然后报错:
.......
.......
RuntimeError: Socket Timeout
.......
.......
RuntimeError: Distributed package doesn't have NCCL built in
发现是多GPU进行分布式训练的问题,然后执行 nvidia-smi 查看哪个GPU是空闲的,使用 set CUDA_VISIBLE_DEVICES=0 设置GPU,如果是卡号 0 的空闲,就 set CUDA_VISIBLE_DEVICES=0 ,如果是卡号 1 的就 set CUDA_VISIBLE_DEVICES=1,更多GPU的依次方法类推。
5. 训练过程中断
训练到360多轮的时候,自动停止了,报错:
Traceback (most recent call last):
File "<string>", line 1, in <module>
.......
.......
EOFError: Ran out of input
.......
.......
PermissionError: [WinError 5] 拒绝访问。
搜了下,没看懂
然后就继续训练了:将配置文件里的resume_checkpoint设置一下就可以重停止的地方开始训练,不需要重头开始
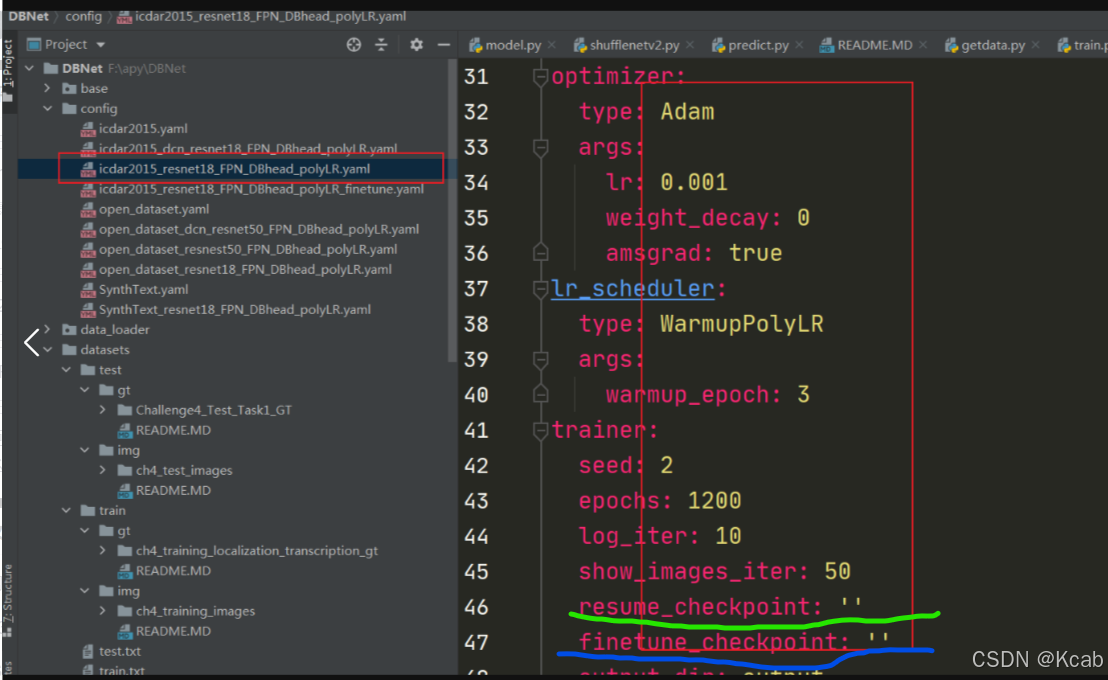
就是把划绿线的地方改为 checkpoint文件即可(.pth文件),选带 laste 的,不选带 best 的。
划蓝线的地方是设置预训练文件地址的。
本文是总结网上的资料,和自己遇到的问题。
参考:https://blog.youkuaiyun.com/qq_44961737/article/details/128272399
为了方便,文章中有的图片使用这篇博客里的。
https://blog.youkuaiyun.com/hhhhhhhhhhwwwwwwwwww/article/details/123904386
https://bbs.huaweicloud.com/blogs/345205
https://rrc.cvc.uab.es/?ch=4&com=tasks

















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









