







 本文介绍了如何使用Labelimg工具并结合Python脚本,批量修改XML文件中图片路径,以适应新的图片存储结构。核心代码展示了如何读取XML文件,替换<folder>标签的内容和图片路径,并将修改后的文件保存。
本文介绍了如何使用Labelimg工具并结合Python脚本,批量修改XML文件中图片路径,以适应新的图片存储结构。核心代码展示了如何读取XML文件,替换<folder>标签的内容和图片路径,并将修改后的文件保存。
labelimg制作数据集+xml文件路径修改
labelimg制作数据集+xml文件路径批量修改
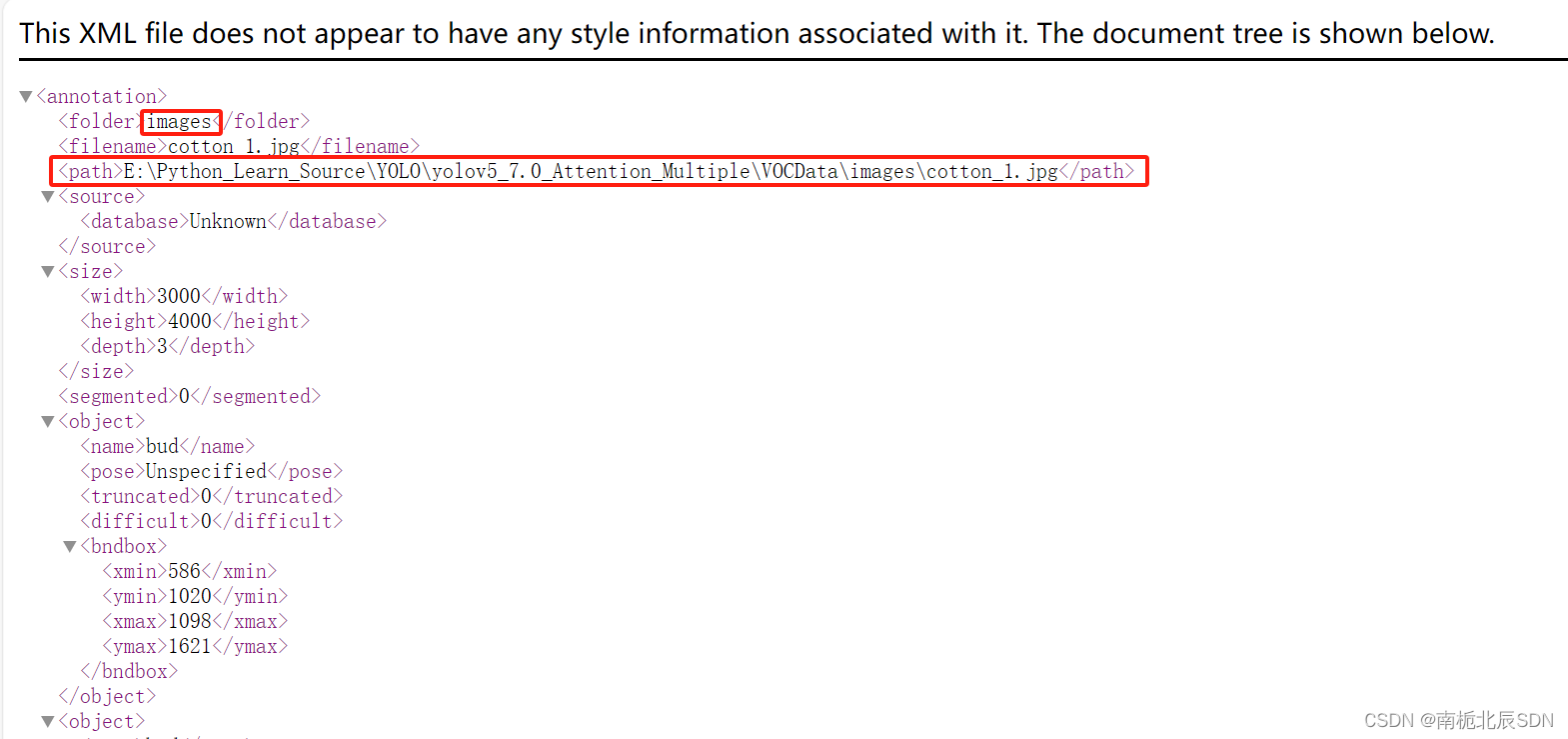
1 .修改下图中 标红的部分
2.核心代码
"""
替换标签xml中的路径,修改下面变量即可:
path
sv_path
img_path
root[0].text
"""
import xml.etree.ElementTree as ET
import os
path = "E:/Python_Learn_Source/10.Data_processing/Original_xml/" # xml文件存放路径
sv_path = "E:/Python_Learn_Source/10.Data_processing/Changed_xml/" # 修改后的xml文件存放路径
img_path = "E:\\Python_Learn_Source\\YOLO/yolov5_7.0_Attention_Multiple\\VOCData\\images\\" # xml里面的新path路径
files = os.listdir(path) # 读取路径下所有文件名
for xmlFile in files:
if xmlFile.endswith('.xml'):
tree = ET.ElementTree(file=path + xmlFile) # 打开xml文件,送到tree解析
root = tree.getroot() # 得到文档元素对象
root[0].text = 'images' # 修改<folder>images</folder>
# root[0].text是annotation下第一个子节点中内容,直接赋值替换文本内容
root[2].text = img_path + xmlFile
root[2].text = root[2].text.replace('xml', 'jpg')
# 替换后的内容保存在内存中需要将其写出
tree.write(sv_path + xmlFile)
print('全部替换完成')


















 854
854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











