






梯度下降法
#梯度下降法基本原理 实现
import numpy as np
#import pandas as pd
#from sklearn import datasets
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
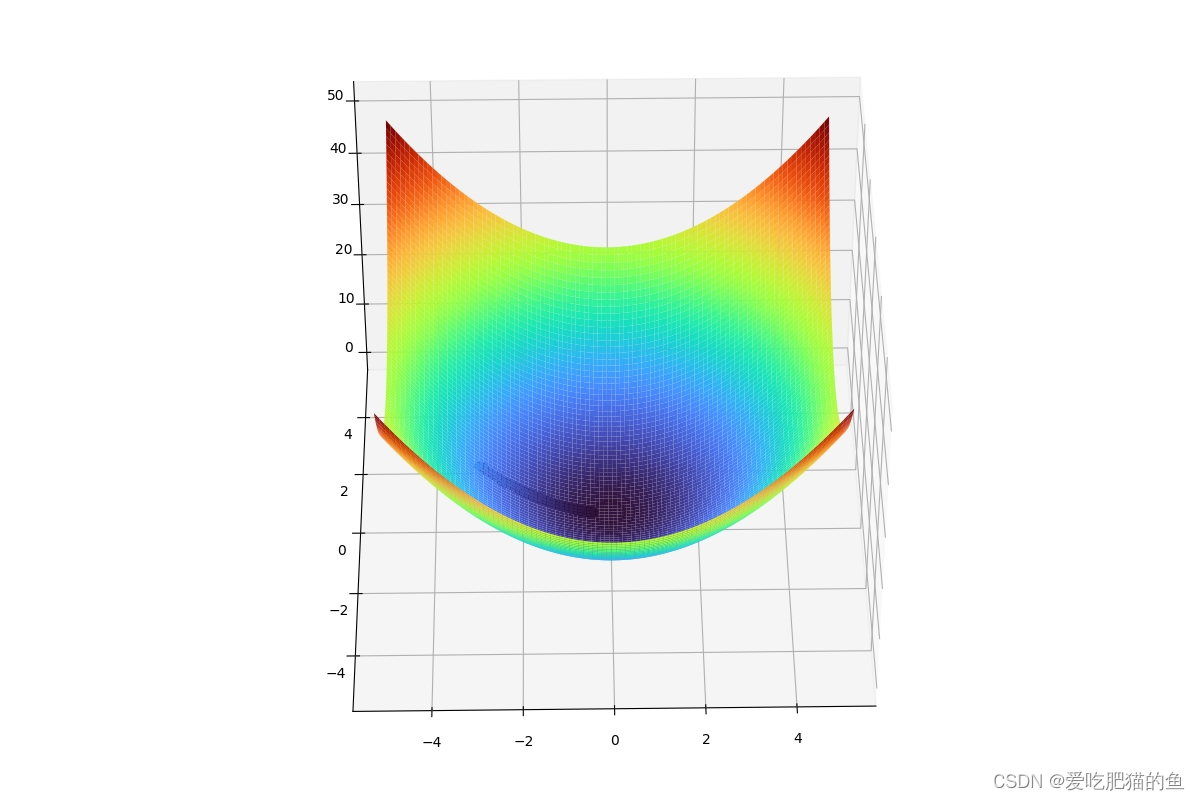
fun = lambda x1,x2:x1**2+x2**2
ub=5
lb=-5
class SGD():
def __init__(self,fun,ub,lb,precison=0.001,iteration = 100,learning_rate = 0.001,flag = True,):
self.iteration = iteration
self.learning_rate = learning_rate
self.fun = fun
self.flag = flag
self.ub = ub
self.lb = lb
self.inti_num = -np.inf
self.inti_x1 = np.random.uniform(self.lb,self.ub)
self.inti_x2 = np.random.uniform(self.lb, self.ub)
self.precision = precison
def run(self):
x = np.linspace(self.lb, self.ub, 100)
y = np.linspace(self.lb, self.ub, 100)
x_, y_ = np.meshgrid(x, y)
plt.ion()
fig = plt.figure(figsize=(12, 8))
ax = Axes3D(fig)
ax.plot_surface(x_, y_, self.fun(x_, y_), cstride=5, rstride=5, cmap='turbo')
#主程序
for j in range(self.iteration):#迭代次数
if self.flag:
for i in range(10):#迭代次数
if self.flag:
self.inti_x1 = self.inti_x1 - self.learning_rate*2*self.inti_x1
self.inti_x2 = self.inti_x2 - self.learning_rate * 2 * self.inti_x2
self.flag = (np.abs(self.fun(self.inti_x1,self.inti_x2) - self.inti_num )>=self.precision)
self.inti_num = self.fun(self.inti_x1,self.inti_x2)
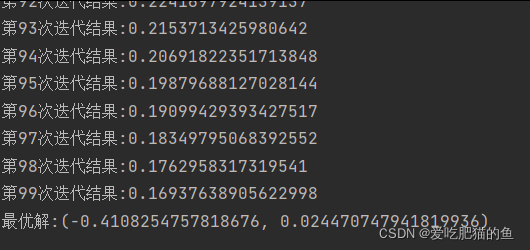
print(f'第{j}次迭代结果:{self.inti_num}')
if self.flag==False:break
ax.scatter(self.inti_x1, self.inti_x2, self.fun(self.inti_x1, self.inti_x2),s=40,edgecolor= 'black')
plt.pause(0.001)
print(f'最优解:{self.inti_x1,self.inti_x2}')
plt.ioff()
plt.show()
SGD(fun,ub,lb) .run()
拟合曲线
import numpy as np
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X,label = make_blobs(10000,2,centers=7)
x ,y = np.array([X[:,0]]).T,np.array([X[:,1]]).T
# 初始参数
learning_rate = 0.001
theta = np.random.random((2,1))# np.array([[1],[2]])#
x_ = x
ones_x = np.hstack((np.ones_like(x_),x_))
Y=y
def SGD(ones_x, theta, Y):
def loss_function(theta,X, Y):
x_theta_Y = np.dot(ones_x, theta) - Y
H_x = np.dot(x_theta_Y.T, x_theta_Y)/X.shape[0]*0.5
return H_x
def gradiant_function(ones_x, theta, Y):
x_theta_Y = np.dot(ones_x, theta) - Y
return np.dot(ones_x.T, x_theta_Y)
flag = True
loss = []
while flag == True:
delta_theta = gradiant_function(ones_x, theta, Y) / ones_x.shape[0]
theta = theta - learning_rate * delta_theta
flag = np.all(np.abs(delta_theta) > 1e-5)#当梯度变化很小时就可以停止了
loss_ = loss_function(theta, X, Y)
loss .append(np.array(loss_).flatten())
return loss, theta
loss, theta = SGD(ones_x,theta,Y)
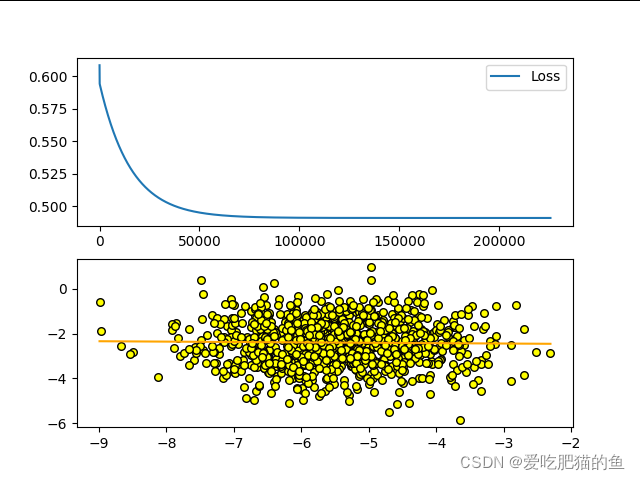
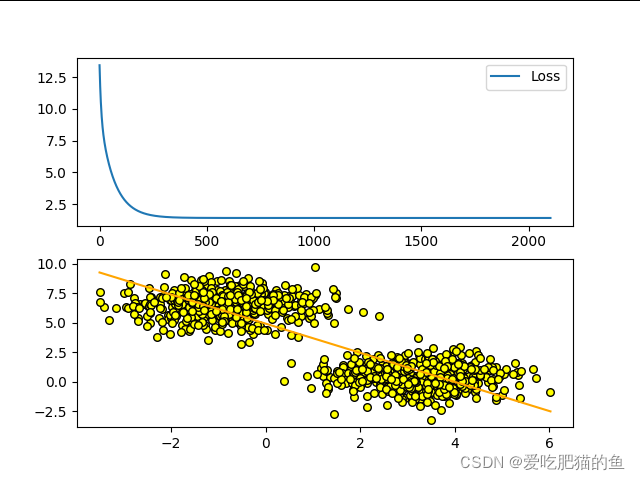
plt.subplot(2,1,1)
plt.plot(loss)
plt.subplot(2,1,2)
x_ = np.linspace(ones_x[:,1].min(),ones_x[:,1].max(),100)
y_ = x_*theta[1]+theta[0]*np.ones_like(theta[1])
plt.plot(x_,y_,color='orange')
plt.scatter(x,y,s=30,edgecolor='black',color= 'yellow')
plt.show()
print(min(loss))
#部分代码纯冗余, jupyter notebook 测试的原因

















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









