







目录
1 梯度下降算法
1.1 基本概念
梯度下降算法是一种用于优化目标函数的迭代算法,通常用于机器学习和人工智能领域。它的基本思想是通过迭代的方式不断调整参数,使得目标函数达到最小值或最大值。
具体来说,梯度下降算法通过计算目标函数对参数的偏导数(梯度),然后沿着梯度的负方向进行迭代调整参数。这是因为梯度的方向表示目标函数在该点上升最快的方向,而梯度的负方向则表示目标函数在该点下降最快的方向。
在每次迭代过程中,梯度下降算法根据预先定义的学习率来控制每次迭代的步长大小。学习率决定了算法在每次迭代中跨越的距离,过大的学习率可能导致算法无法收敛,而过小的学习率可能导致算法收敛速度过慢。
梯度下降算法有多种变体,包括批量梯度下降、随机梯度下降和小批量梯度下降等。批量梯度下降在每次迭代中使用全部样本进行参数更新,随机梯度下降在每次迭代中使用一个样本进行参数更新,而小批量梯度下降则在每次迭代中使用一小部分样本进行参数更新。
梯度下降算法在机器学习和人工智能的许多任务中得到了广泛应用,例如线性回归、逻辑回归和神经网络等。它是一种简单而有效的优化算法,但也存在着一些问题,如容易陷入局部最优解和需要选择合适的学习率等。因此,研究者们一直在针对这些问题进行改进和优化。
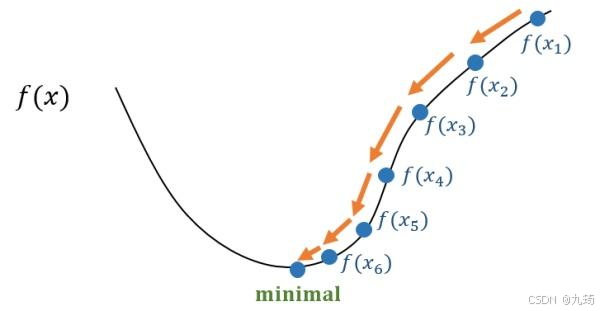
1.2 数学解释
梯度下降算法的数学解释可以从两个方面来理解:目标函数和参数更新。
首先,假设我们有一个目标函数J(θ),其中θ表示参数。我们的目标是找到使目标函数最小化的参数值。为了做到这一点,我们需要计算目标函数对参数的偏导数,也称为梯度。
梯度用∇J(θ)表示,它是一个向量,其中包含了目标函数在每个参数处的变化率。梯度的方向指向目标函数在当前参数点上升最快的方向。
其次,我们需要调整参数以使目标函数达到最小值。我们可以通过迭代的方式更新参数,直到达到满足停止条件为止。
具体地,梯度下降算法的参数更新规则可以表示为:
θ := θ - α * ∇J(θ)
其中,:= 表示赋值操作,α表示学习率(也称为步长),α * ∇J(θ)表示梯度的方向乘以学习率,θ表示更新后的参数值。
梯度下降算法的核心思想是不断迭代地更新参数,直到目标函数收敛到最小值或达到预先设定的停止条件。在每次迭代中,通过计算目标函数对参数的偏导数来得到梯度,然后利用梯度的方向和学习率来更新参数。
总结来说,梯度下降算法通过计算目标函数对参数的偏导数得到梯度,然后沿着梯度的负方向进行参数更新。这样,算法能够沿着目标函数下降的最快方向迭代调整参数,从而使目标函数达到最小值。
1.3 几何解释
梯度下降算法的几何解释可以从两个角度来理解:目标函数的等高线和参数更新的路径。
首先,我们可以将目标函数想象为一个山谷,其中的等高线代表着不同高度的点。我们的目标是找到山谷的最低点,也就是目标函数的最小值。在这种视角下,梯度表示了每个点上升最快的方向。
梯度的方向指向目标函数在当前点上升最快的方向。因此,我们可以利用梯度的方向来指导参数的更新。如果我们希望降低目标函数的值,就要朝着梯度的反方向移动。反之,如果我们希望增加目标函数的值,就要朝着梯度的方向移动。
其次,我们可以将参数更新的过程想象为在山谷中移动的路径。我们从一个初始点开始,根据梯度的方向和学习率来确定下一个点的位置。学习率决定了我们每次迭代时要走多远的距离。
通过不断迭代地更新参数,我们的路径会逐渐靠近山谷的最低点。当我们达到最低点时,梯度将变为零,参数更新的路径将停止,算法收敛。
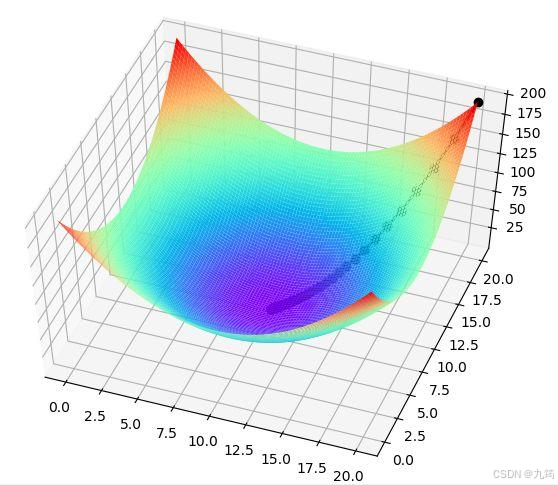
总结来说,梯度下降算法的几何解释是,在目标函数的等高线中,沿着梯度的反方向移动参数,通过不断迭代更新参数的路径,最终达到目标函数的最小值。这个过程类似于在山谷中找到最低点的路径,梯度指导了我们如何朝着最低点移动。
1.4 运行过程
梯度下降算法是一种优化算法,用于求解损失函数最小化的问题。其运行过程可以分为以下步骤:
- 初始化模型参数:首先需要初始化模型的参数,如权重和偏置。
- 计算损失函数:使用当前的模型参数计算损失函数的值。损失函数是衡量模型预测结果与实际结果之间的差距的函数。
- 计算梯度:通过求取损失函数对于每个参数的偏导数,得到模型参数的梯度。梯度指示了参数在当前位置上的变化速度和方向。
- 更新模型参数:根据学习率和梯度的方向,更新模型的参数。学习率控制每次参数更新的步长。
- 重复步骤2-4:重复进行步骤2-4,直到达到停止条件。停止条件可以是达到最大迭代次数,或者损失函数的变化小于设定的阈值。
通过不断迭代更新模型参数,梯度下降算法可以逐渐降低损失函数的值,从而使模型的预测结果更准确。
1.5 作用
梯度下降算法的主要作用是用于优化目标函数,并在参数空间中找到使目标函数达到最小值的参数值。在机器学习和深度学习中,梯度下降算法被广泛应用于模型训练过程中的参数优化。它通过计算目标函数对参数的梯度(即目标函数在参数空间中的变化率),并利用梯度的负方向来更新参数,逐步地迭代优化模型。
具体来说,梯度下降算法帮助解决以下问题:
- 参数估计:通过最小化目标函数,获得最优的参数估计值,使得模型能够与实际数据拟合得更好。
- 模型训练:在机器学习和深度学习中,通过梯度下降算法可以更新模型的参数,从而不断优化模型的预测能力。
- 损失函数最小化:梯度下降算法可以帮助找到使损失函数最小化的参数值,从而得到更准确的预测结果。
梯度下降算法的作用是在参数空间中搜索最优解,并向着最小化目标函数的方向迭代优化。它是优化算法中最常用的方法之一,有助于优化各种类型的模型,包括线性回归、逻辑回归、神经网络等。
2 梯度下降算法的类别
常用的梯度下降算法可以分为以下几个类别:批量梯度下降(Batch Gradient Descent,BGD)、随机梯度下降(Stochastic Gradient Descent,SGD)、小批量梯度下降(Mini-Batch Gradient Descent)。此外,还有一些梯度下降算法的变体,如动量梯度下降(Momentum Gradient Descent)、Nesterov加速梯度下降(Nesterov Accelerated Gradient Descent)和自适应梯度下降(Adaptive Gradient Descent)等。这些算法在参数更新的过程中引入了额外的因素,以提高收敛速度、稳定性或适应性。
2.1 批量梯度下降
批量梯度下降(Batch Gradient Descent,BGD)是梯度下降算法的一种形式,它使用所有样本的梯度来更新参数。在每次迭代中,计算所有样本的损失函数的梯度,并根据该梯度来更新参数。该方法的计算效率较低,但通常能获得较为准确的最优解。
具体而言,批量梯度下降的迭代步骤如下:
- 随机初始化参数θ。
- 在所有样本上计算损失函数L的梯度∇L(θ)。
- 更新参数θ:θ = θ - α * ∇L(θ),其中α是学习率(步长),控制参数更新的幅度。
- 重复步骤2和3,直到满足停止条件(如达到最大迭代次数、损失函数收敛等)。
批量梯度下降的优点是可以获得较为准确的最优解,因为每次迭代都利用了全局的梯度信息。然而,由于需要在每次迭代中计算所有样本的梯度,所以计算效率较低,尤其当样本数量很大时。此外,批量梯度下降可能会陷入局部最优解,且在参数更新过程中可能存在震荡现象。
为了克服这些问题,可以使用随机梯度下降(Stochastic Gradient Descent,SGD)或小批量梯度下降(Mini-Batch Gradient Descent),它们每次只使用一个样本或一小批样本的梯度来更新参数,从而提高计算效率和收敛速度。
2.2 随机梯度下降
随机梯度下降(Stochastic Gradient Descent,SGD)是梯度下降算法的一种优化形式,在每次迭代中仅使用一个样本的梯度来更新参数。相比于批量梯度下降(BGD),SGD的计算效率更高且具有更快的收敛速度。但由于每次只计算一个样本的梯度,该方法的计算效率较高。但由于单个样本的梯度可能带有较大噪声,因此可能会导致参数更新不稳定,难以达到最优解。
具体而言,随机梯度下降的迭代步骤如下:
- 随机初始化参数θ。
- 随机选择一个样本,并计算该样本的损失函数的梯度∇L(θ)。
- 更新参数θ:θ = θ - α * ∇L(θ),其中α是学习率(步长),控制参数更新的幅度。
- 重复步骤2和3,直到满足停止条件(如达到最大迭代次数、损失函数收敛等)。
相比于BGD,SGD具有以下优点:
- 计算效率高:每次迭代仅使用一个样本的梯度,计算开销较小。
- 内存占用低:不需要存储所有样本的梯度信息,只需存储当前样本的梯度。
- 收敛速度快:由于参数更新更频繁,SGD通常比BGD更快地收敛到局部最优解。
然而,SGD也存在一些问题:
- 参数更新的方差大:由于每次仅使用一个样本的梯度,参数更新的方向可能存在较大的波动,从而导致收敛过程中的震荡现象。
- 陷入局部最优解的可能性增加:由于每次迭代的参数更新依赖于单个样本的梯度,SGD在参数空间中可能陷入局部最优解,而无法达到全局最优解。
为了克服SGD的问题,可以使用小批量梯度下降(Mini-Batch Gradient Descent),它是将一小批样本的梯度作为参数更新的依据,既兼顾了计算效率,又减小了参数更新的方差。
2.3 小批量梯度下降
小批量梯度下降(Mini-Batch Gradient Descent)是梯度下降算法的一种变体,在每次迭代中使用一小批样本的梯度来更新参数。相比于批量梯度下降(BGD)和随机梯度下降(SGD),小批量梯度下降综合了两者的优点,既在计算效率上比BGD更高,又比SGD更稳定,能够获得较为准确的梯度信息。
具体而言,小批量梯度下降的迭代步骤如下:
- 随机初始化参数θ。
- 随机选择一个小批量样本(通常大小为n)。
- 计算该小批量样本的损失函数的梯度∇L(θ)。
- 更新参数θ:θ = θ - α * ∇L(θ),其中α是学习率(步长),控制参数更新的幅度。
- 重复步骤2~4,直到满足停止条件(如达到最大迭代次数、损失函数收敛等)。
小批量梯度下降在计算效率上比BGD更高,因为每次迭代只需要计算一小批样本的梯度。同时,与SGD相比,小批量梯度下降可以减少参数更新的方差,从而更稳定地收敛。此外,小批量梯度下降还可以利用并行计算的优势,在GPU等硬件上进行高效计算。
小批量梯度下降的小批量大小n通常是一个超参数,需要根据具体问题和计算资源进行选取。较小的批量大小可以增加参数更新的频率,但可能导致迭代过程中的震荡现象;较大的批量大小可以减少参数更新的方差,但会增加计算开销。因此,需要进行实验和调整来找到最优的小批量大小。
3 代码实现
3.1 单变量
3.1.1 代码
import numpy as np
import matplotlib.pyplot as plt
class GradientDescent:
def __init__(self, function, initial_x,lr=0.1):
self.function = function
self.initial_x = initial_x
self.lr = lr
self.trajectory = []
self.x_star = None
#采用微分的方式求导数
def get_gradient(self, x, epsilon=1e-5):
grad = (self.function(x + epsilon) - self.function(x)) / epsilon
return grad
#核心算法
def algorithm(self):
xi = self.initial_x
epochs = 0
while epochs < 50 and abs(self.get_gradient(xi)) > 1e-3:
self.trajectory.append(xi)
xi -= self.lr * self.get_gradient(xi)
epochs += 1
self.x_star = xi
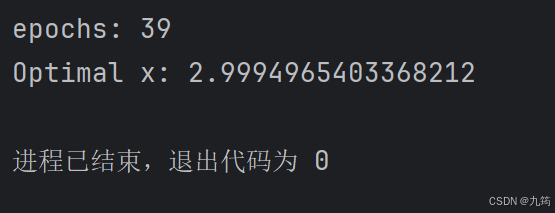
print(f"epochs: {epochs}")
print(f"Optimal x: {self.x_star}")
def plot_function_and_trajectory(self, x_range=(-2, 8), step=0.1):
x = np.arange(x_range[0], x_range[1], step)
y = self.function(x)
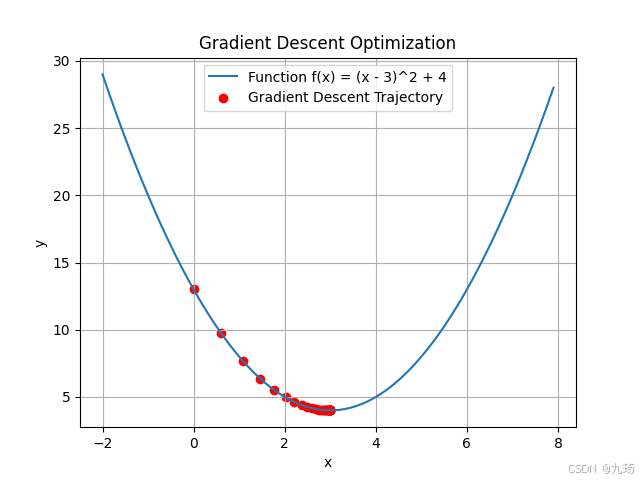
plt.plot(x, y, label='Function f(x) = (x - 3)^2 + 4')
x_trajectory = np.array(self.trajectory)
y_trajectory = self.function(x_trajectory)
plt.scatter(x_trajectory, y_trajectory, color='red', label='Gradient Descent Trajectory')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.title('Gradient Descent Optimization')
plt.grid(True)
plt.show()
def function(x):
return (x - 3) ** 2 + 4
if __name__ == "__main__":
initial_x = 0
epochs = 50
lr = 0.1
optimizer = GradientDescent(function, initial_x, lr)
optimizer.algorithm()
optimizer.plot_function_and_trajectory()
3.1.2 运行结果
3.2 多变量
3.2.1 代码
import numpy as np
import matplotlib.pyplot as plt
class GradientDescent:
def __init__(self, function, initial_point, lr=0.1):
self.function = function
self.initial_x, self.initial_y = initial_point
self.lr = lr
self.trajectory = []
self.x_star = None
self.y_star = None
#采用微分的方式求偏导数
def get_gradient(self, x, y, epsilon=1e-5):
#计算函数在点 (x, y) 处在 x 的偏导数(梯度)。
#通过计算函数在 (x + epsilon, y) 和 (x, y) 两点处的值之差,然后除以 epsilon 来近似。
#基于数值微分的思想,即当 epsilon 非常小时,这个比值接近于函数在 (x, y) 处关于 x 的真实偏导数。
grad_x = (self.function(x + epsilon, y) - self.function(x,y)) / epsilon
# 计算函数在点 (x, y) 处在 y 的偏导数(梯度)。
grad_y = (self.function(x, y + epsilon) - self.function(x,y)) / epsilon
return grad_x, grad_y
def algorithm(self):
xi, yi = self.initial_x, self.initial_y
epochs = 0
while epochs < 100:
self.trajectory.append((xi, yi))
grad_x, grad_y = self.get_gradient(xi, yi)
if max(abs(grad_x), abs(grad_y)) < 1e-7:
break
xi -= self.lr * grad_x
yi -= self.lr * grad_y
epochs += 1
self.x_star = xi
self.y_star = yi
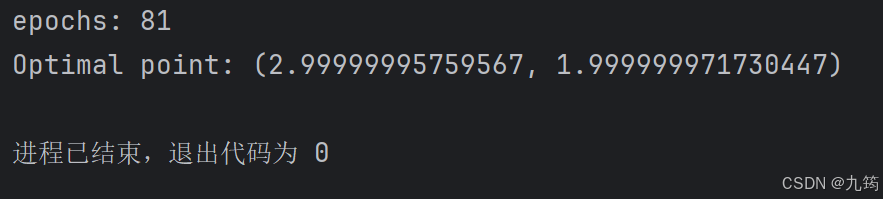
print(f"epochs: {epochs}")
print(f"Optimal point: {self.x_star,self.y_star}")
def function_trajectory(self, x_range=(-10, 10), y_range=(-10, 10), step=0.5):
x = np.arange(x_range[0], x_range[1], step)
y = np.arange(y_range[0], y_range[1], step)
X, Y = np.meshgrid(x, y)
Z = self.function(X, Y)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X, Y, Z, cmap='viridis')
trajectory_x, trajectory_y, trajectory_z = zip(
*[(p[0], p[1], self.function(p[0], p[1])) for p in self.trajectory])
ax.scatter(trajectory_x, trajectory_y, trajectory_z,
color='red', label='Gradient Descent Trajectory')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('f(x, y)')
ax.legend()
plt.title('Gradient Descent Optimization in 3D')
plt.show()
def contour_trajectory(self, x_range=(-10, 10), y_range=(-10, 10), step=0.5):
x = np.arange(x_range[0], x_range[1], step)
y = np.arange(y_range[0], y_range[1], step)
X, Y = np.meshgrid(x, y)
Z = self.function(X, Y)
plt.figure()
plt.contour(X, Y, Z, levels=50, cmap='viridis')
trajectory_x, trajectory_y = zip(*self.trajectory)
plt.plot(trajectory_x, trajectory_y, 'ro-',
label='Gradient Descent Trajectory')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.title('Gradient Descent Optimization Contour Plot')
plt.grid(True)
plt.show()
def function(x,y):
return (x - 3) ** 2 + (y - 2) ** 2+ 4
if __name__ == "__main__":
initial_point = [0, 0]
lr = 0.1
optimizer = GradientDescent(function, initial_point, lr)
optimizer.algorithm()
optimizer.contour_trajectory()
optimizer.function_trajectory()3.2.2 运行结果
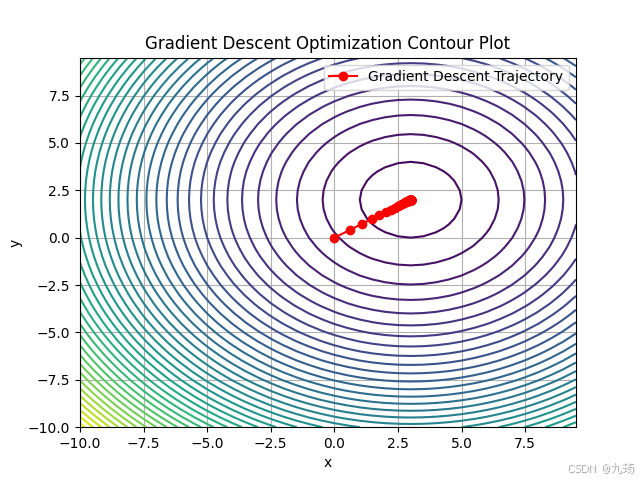
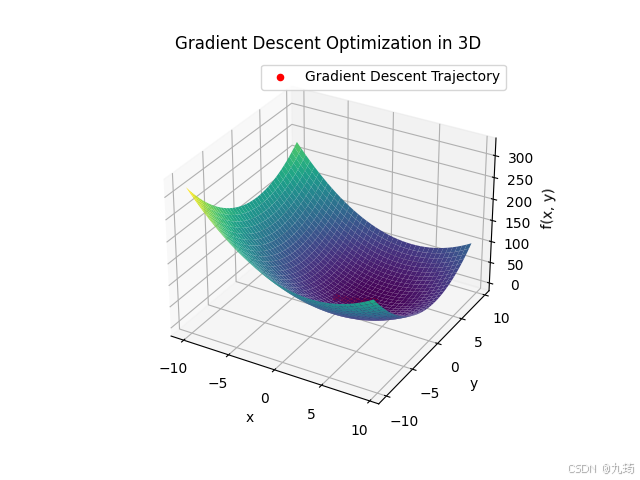
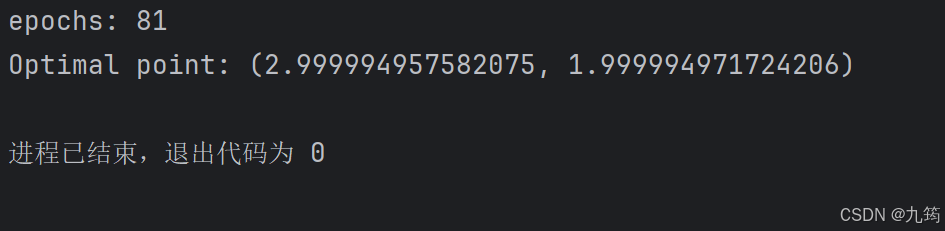
3.3 综合
3.3.1 代码
import numpy as np
import matplotlib.pyplot as plt
class GradientDescent:
def __init__(self, function, initial_point, lr=0.1):
self.function = function
self.initial_point = np.array(initial_point, dtype=np.float64)
self.lr = lr
self.trajectory = []
self.optimal_point = None
def get_gradient(self, point, epsilon=1e-5):
#单变量函数
if len(point) == 1:
grad = (self.function(point + epsilon) - self.function(point)) / epsilon
return grad[0]
#多变量函数
else:
#使用 NumPy 的 zeros_like 函数创建一个与 point 形状相同但所有元素都为零的数组
#用于存储梯度
grad = np.zeros_like(point)
for i in range(len(point)):
point_copy = point.copy()
#将 point_copy 的第 i 个元素增加 epsilon,以计算函数在该点附近的一个新位置的值
point_copy[i] += epsilon
if len(point_copy) == 2:
grad[i] = (self.function(point_copy[0], point_copy[1]) -
self.function(point[0],point[1])) / epsilon
# 如果扩展到更多变量,可以继续编写
else:
raise NotImplementedError("目前只支持两个变量")
return grad
def algorithm(self):
point = self.initial_point.copy()
epochs = 0
#设定的一些条件,也可以统一设置
#tolerance=1e-7
#max_epochs=100
tolerance = 1e-7 if len(point) == 1 else 1e-3
max_epochs = 50 if len(point) == 1 else 100
while epochs < max_epochs:
self.trajectory.append(point.copy())
grad = self.get_gradient(point)
if np.linalg.norm(grad) < tolerance:
break
point -= self.lr * grad
epochs += 1
self.optimal_point = point.copy()
print(f"epochs: {epochs}")
print(f"Optimal point: {self.optimal_point}")
#绘图
def plot_results(self, x_range=(-10, 10),
y_range=(-10, 10), step=0.5, is_3d=False):
#单变量函数,只绘制函数梯度下降轨迹图
if len(self.initial_point) == 1:
x = np.arange(x_range[0], x_range[1], step)
y = self.function(x)
plt.plot(x, y, label='Function f(x)')
trajectory_x = np.array([p[0] for p in self.trajectory])
trajectory_y = self.function(trajectory_x)
plt.scatter(trajectory_x, trajectory_y,
color='red', label='Gradient Descent Trajectory')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.legend()
plt.title('Gradient Descent Optimization (1D)')
plt.grid(True)
plt.show()
#多变量函数
else:
x = np.arange(x_range[0], x_range[1], step)
y = np.arange(y_range[0], y_range[1], step)
X, Y = np.meshgrid(x, y)
Z = self.function(X, Y)
if is_3d:
#生成函数的三维图形
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X, Y, Z, cmap='viridis')
trajectory_x, trajectory_y = zip(*[(p[0], p[1]) for p in self.trajectory])
trajectory_z = [self.function(x, y) for x, y in zip(trajectory_x, trajectory_y)]
ax.scatter(trajectory_x, trajectory_y,
trajectory_z, color='red', label='Gradient Descent Trajectory')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('f(x, y)')
ax.legend()
plt.title('Gradient Descent Optimization in 3D')
plt.show()
#生成等高线图
plt.figure()
plt.contour(X, Y, Z, levels=50, cmap='viridis')
plt.plot([p[0] for p in self.trajectory], [p[1] for p in self.trajectory], 'ro-',
label='Gradient Descent Trajectory')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.title('Gradient Descent Optimization Contour Plot (2D)')
plt.grid(True)
plt.show()
def function_1d(x):
return (x - 3) ** 2 + 4
def function_2d(x, y):
return (x - 3) ** 2 + (y - 2) ** 2 + 4
if __name__ == "__main__":
initial_point_1d = 0
lr_1d = 0.1
optimizer_1d = GradientDescent(function_1d, [initial_point_1d], lr_1d)
optimizer_1d.algorithm()
optimizer_1d.plot_results()
initial_point_2d = [0, 0]
lr_2d = 0.1
optimizer_2d = GradientDescent(function_2d, initial_point_2d, lr_2d)
optimizer_2d.algorithm()
optimizer_2d.plot_results(is_3d=True)3.3.2 运行结果
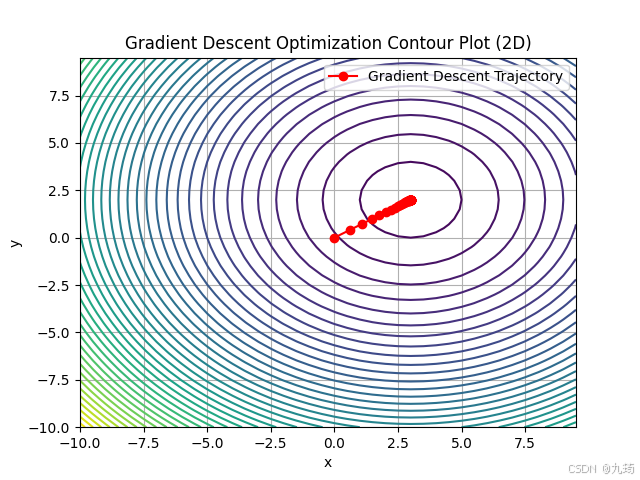

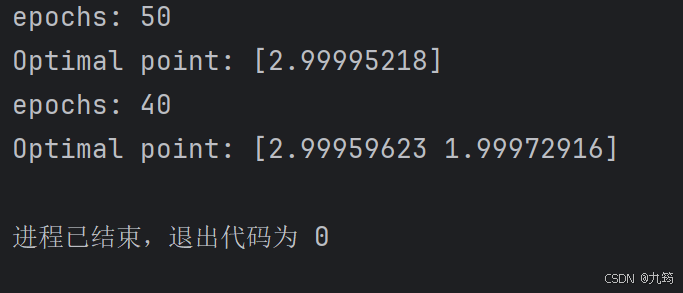
4 利用不太常见的库实现梯度下降
4.1 单变量
4.1.1 代码
import numpy as np
import matplotlib.pyplot as plt
from sympy import diff, symbols, lambdify
#diff:SymPy 中用于计算导数(包括偏导数)的函数,支持对单个变量或多个变量(对于多元函数)求偏导。
#symbols:用于定义符号变量。
#lambdify:用于将 SymPy 表达式转换为 Python 的可调用对象(如函数),这些对象可以接受数值输入并返回数值结果。
class GradientDescent:
def __init__(self, sympy_function, initial_x, lr):
#使用 SymPy 库的 symbols 函数定义一个符号变量 x,表示目标函数的自变量是 x。
self.x = symbols("x")
#将传入的 sympy_function 参数保存到实例变量 self.sympy_function。
self.sympy_function = sympy_function
#使用 lambdify 函数将 self.sympy_function 转换为 NumPy 函数,可以进行数值运算。
self.numpy_function = lambdify(self.x, self.sympy_function, 'numpy')
#使用 SymPy 的 diff 函数计算 self.sympy_function 关于 x 的导数(梯度)。
self.gradient = diff(self.sympy_function, self.x)
#print(self.gradient)
#同样使用 lambdify 函数将梯度的 SymPy 表达式转换为 NumPy 函数,可以进行数值运算。
self.numpy_gradient = lambdify(self.x, self.gradient, 'numpy')
self.initial_x = initial_x
self.lr = lr
self.trajectory = []
self.x_star = None
def get_gradient(self, x):
return self.numpy_gradient(x)
def algorithm(self):
xi = self.initial_x
epochs = 0
#while循环,当循环次数小于50且当前点 xi 处的梯度绝对值大于 1e-3
while epochs < 50 and abs(self.get_gradient(xi)) > 1e-3:
self.trajectory.append(xi)
xi -= self.lr * self.get_gradient(xi)
epochs += 1
self.x_star = xi
print(f"epochs: {epochs}")
print(f"Optimal x: {optimizer.x_star}")
#绘制函数轨迹
def function_trajectory(self, x_range=(-20, 20), step=0.1):
x = np.arange(x_range[0], x_range[1], step)
y = self.numpy_function(x)
plt.plot(x, y, label=self.sympy_function)
x_trajectory = np.array(self.trajectory)
y_trajectory = self.numpy_function(x_trajectory)
plt.scatter(x_trajectory, y_trajectory, color='red',
label='Gradient Descent Trajectory')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.title('Gradient Descent Optimization')
plt.grid(True)
plt.show()
if __name__ == "__main__":
x = symbols("x")
function = x ** 2 + 1
initial_x = -18
lr = 0.1
optimizer = GradientDescent(function, initial_x, lr)
optimizer.algorithm()
optimizer.function_trajectory()
4.1.2 运行结果
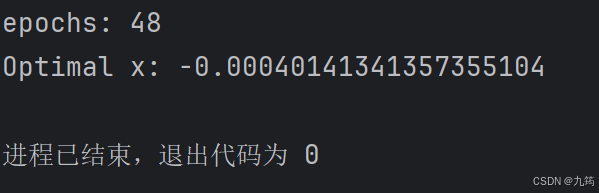
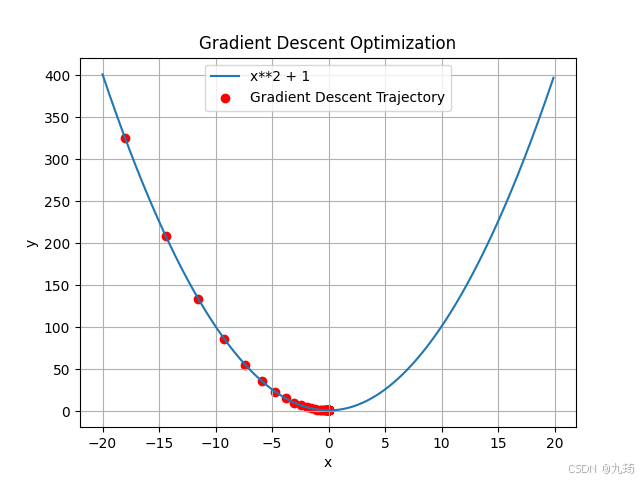
4.2 多变量
4.2.1 代码
import numpy as np
import matplotlib.pyplot as plt
from sympy import diff, symbols, lambdify
#diff:SymPy 中用于计算导数(包括偏导数)的函数,支持对单个变量或多个变量(对于多元函数)求偏导。
#symbols:用于定义符号变量。
#lambdify:用于将 SymPy 表达式转换为 Python 的可调用对象(如函数),这些对象可以接受数值输入并返回数值结果。
class GradientDescent:
def __init__(self, sympy_function, initial_point, lr):
# 使用 SymPy 库的 symbols 函数定义一个符号变量 x,y,表示目标函数的自变量是 x,y。
self.x, self.y = symbols("x y")
# 将传入的 sympy_function 参数保存到实例变量 self.sympy_function。
self.sympy_function = sympy_function
#使用 lambdify 函数将 self.sympy_function 转换为 NumPy 函数,可以进行数值运算。
self.numpy_function = lambdify((self.x, self.y), self.sympy_function, 'numpy')
#计算 self.sympy_function 关于 self.x 的偏导数,并使用 lambdify 将其转换为 NumPy 函数。
self.gradient_x = lambdify((self.x, self.y), diff(self.sympy_function, self.x), 'numpy')
#计算 self.sympy_function 关于 self.y 的偏导数,并使用 lambdify 将其转换为 NumPy 函数。
self.gradient_y = lambdify((self.x, self.y), diff(self.sympy_function, self.y), 'numpy')
self.initial_x, self.initial_y = initial_point
self.lr = lr
self.trajectory = []
self.x_star = None
self.y_star = None
def get_gradient(self, x, y):
return self.gradient_x(x, y), self.gradient_y(x, y)
def algorithm(self):
xi, yi = self.initial_x, self.initial_y
epochs = 0
#while循环,小于100
while epochs < 100:
self.trajectory.append((xi, yi))
grad_x, grad_y = self.get_gradient(xi, yi)
#如果梯度小于1e-7,结束循环
if max(abs(grad_x), abs(grad_y)) < 1e-7:
break
xi -= self.lr * grad_x
yi -= self.lr * grad_y
epochs += 1
self.x_star = xi
self.y_star = yi
print(f"epochs: {epochs}")
print(f"Optimal point: {self.x_star,self.y_star}")
#绘制梯度下降轨迹
def function_trajectory(self, x_range=(-10, 10), y_range=(-10, 10), step=0.5):
x = np.arange(x_range[0], x_range[1], step)
y = np.arange(y_range[0], y_range[1], step)
X, Y = np.meshgrid(x, y)
Z = self.numpy_function(X, Y)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X, Y, Z, cmap='viridis')
trajectory_x, trajectory_y, trajectory_z = zip(
*[(p[0], p[1], self.numpy_function(p[0], p[1])) for p in self.trajectory])
ax.scatter(trajectory_x, trajectory_y, trajectory_z,
color='red', label='Gradient Descent Trajectory')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('f(x, y)')
ax.legend()
plt.title('Gradient Descent Optimization in 3D')
plt.show()
#绘制等高线图
def contour_trajectory(self, x_range=(-10, 10), y_range=(-10, 10), step=0.5):
x = np.arange(x_range[0], x_range[1], step)
y = np.arange(y_range[0], y_range[1], step)
X, Y = np.meshgrid(x, y)
Z = self.numpy_function(X, Y)
plt.figure()
plt.contour(X, Y, Z, levels=50, cmap='viridis')
trajectory_x, trajectory_y = zip(*self.trajectory)
plt.plot(trajectory_x, trajectory_y, 'ro-',
label='Gradient Descent Trajectory')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.title('Gradient Descent Optimization Contour Plot')
plt.grid(True)
plt.show()
if __name__ == "__main__":
x, y = symbols("x y")
function = (x - 3) ** 2 + (y - 2) ** 2 + 19
initial_point = [0, 0]
lr = 0.1
optimizer = GradientDescent(function, initial_point, lr)
optimizer.algorithm()
optimizer.contour_trajectory()
optimizer.function_trajectory()4.2.2 运行结果

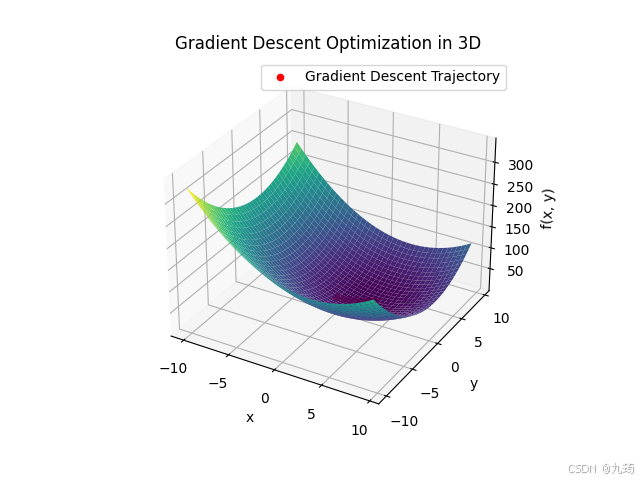

















 2177
2177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









