







Non-local Neural Networks(非局部神经网络):使用自注意力机制捕获远程依赖。
论文: https://arxiv.org/pdf/1711.07971.pdf
源码:https://gitcode.net/mirrors/facebookresearch/video-nonlocal-net
目录
三、Non-local Neural Networks(非局部神经网络)
长距离依赖关系,顾名思义,是要和远程建立关系,在long-range的情况下有关联。在cv领域,就是考虑一个像素的时候同时考虑其邻域,甚至是邻域的邻域....,能够建模两个较远像素之间的关系,例如是不是同属一个类等等。
引用博文:MedT
一、背景和出发点
卷积运算是一次处理一个局部邻域的构建块,在捕获远程依赖关系时有许多的局限,例如:它的计算效率很低;它会导致优化困难等。作者受经典的非局部均值方法(non-local means)的启发,提出了一种非局部模块作为一种高效、通用的组件,用于在深度神经网络中捕获远程依赖关系。
(该非局部模块结合了多头注意力机制。)
二、创新点
1. 与RNN和CNN的渐进行为相反,非局部运算通过计算任意两个位置之间的交互来直接捕获远程依赖,而不管它们的位置距离如何。
2. 正如本文在实验中所展示的,非局部操作是高效的,即使只有几层(例如5层),也能达到最佳效果。
3. 该非局部操作保持可变的输入大小,并且可以轻松地与其他操作(例如,我们将使用的卷积)组合。
三、Non-local Neural Networks(非局部神经网络)
3.1 非局部操作的一般定义
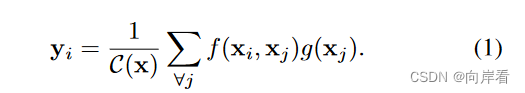
其中, 是输入特征中要被计算的位置,
是
所有可能关联到位置的索引。
是位置间的类同标量函数,用于计算两位置间的相关性。
是位置输入信号函数,对输入的特征进行赋权,C(x)是归一化因子。
上述的非局部操作看后可能会感到一头雾水,我们需要简单了解一下前继论文:non-local means,非局部均值滤波:
算法思想:图像的长边缘,纹理结构都是相似的,因此,在同一幅图像中, 对相似区域进行分类并加权平均得到的去噪图像,也应该能提高去噪效果。
方法:NLM是非局部均值操作,对每个滤波点都利用了整张图像的信息。对像素点
做NLM操作,先遍历整张图像,求出
公式:
其中,
表示为
表示像素点
的灰度值,
,
是
如果仅仅比较
像素值来作为相似度的依据,不能正确反映
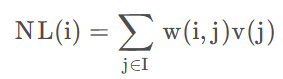
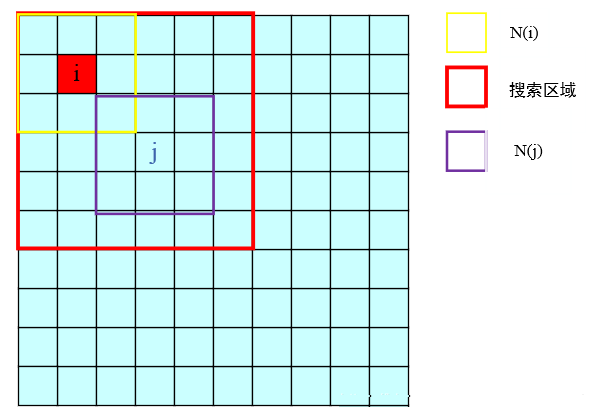
由上述的non-local means转到本文的Non-local操作的定义,可知, 用于计算像素域
和
的相似度,作为像素域
的权重,这样通过累加求均值,获得的
便捕获了整张图像的长距离依赖关系。(
可以看作整张图像与在
位置上的原像素的相似度相乘求均值得到的。)
3.2 实例
计算像素邻域间的相似性的四种方法:
1. 高斯函数
![]()
2. 嵌入式高斯函数
![]()
其中, 和
是两个嵌入件。
,
是要学习的权重矩阵,通过1x1x1卷积实现。(这里是对应视频分类任务,图像任务可采用1x1卷积)。
3. 点积
![]()
4. Concatenation(标注[40]提出的方法)
![]()
其中,[·,·] 表示维度拼接操作。
3.3 Non-local Block(NL模块)
NL模块由Non-local操作与多头注意力机制结合而来。可以采用以上的四种方法中的任意一种计算相似度。
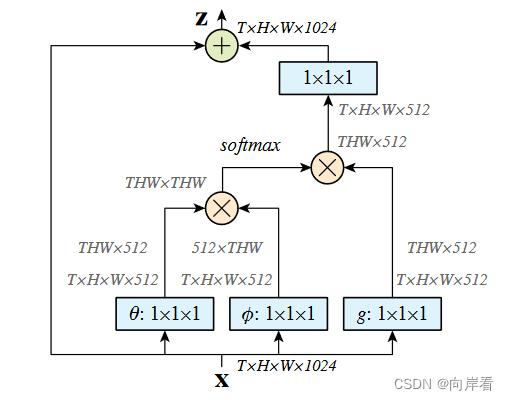
思想: 由上述的Non-local操作概述,我们可以得知要在一张图像上建立起长距离依赖关系只需要计算整张图像上每个像素值与其他像素值之间的相似度,以此作为其他像素值的权重,累加(![]() )求均值,得到的新值替代原来的像素值,最终得到的新的图像的像素值是按类别划分的,相似的像素值被整合为了一类,这样就完成了对长距离依赖关系的捕获。
)求均值,得到的新值替代原来的像素值,最终得到的新的图像的像素值是按类别划分的,相似的像素值被整合为了一类,这样就完成了对长距离依赖关系的捕获。
过程:以点积计算相似度的方法为例。首先,输入图像 通过三个1x1的卷积得到三个特征图
。
和
通过点积操作计算每个像素值与其他像素值之间的相似度,定义如下:
![]()
再通过softmax函数求均值(归一化的同时也进行均值操作),这里得到的相似度矩阵大小为WHxWH,也就是说每个像素都有对应的一个相似度矩阵(大小为W x H),每个大小为W x H的相似度矩阵作为权重与原特征图()按位相乘再相加(点积计算)得到的新的特征图(大小为WxHx512),即捕获到了图像的长距离依赖关系。定义如下:
再经过一个1x1的卷积将通道数恢复到1024,与原输入图像 进行残差连接,最终得到一个融合了图像长距离依赖关系的新特征图
,定义如下:
![]()
这里简单的说一下残差连接(参考深度残差网络ResNet),引入残差连接的好处在于允许将NL模块插入任何预先训练的模型中,而不会破坏其初始化表现,这样就保证了NL模块在其他网络中的通用性,即插即用。
四、实验
我们仅关注在2D图像上的实验。
数据集:CoCo数据集 。
主干网络:ResNet50、ResNet101或ResNeXt-152。
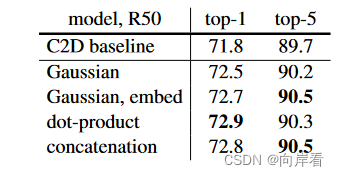
1. 验证四种相似度计算方法效果差异
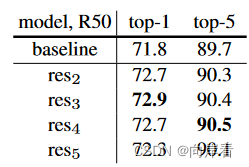
2. 比较单个NL模块添加到ResNet不同位置的情况
3. 比较添加不同数量的NL模块效果
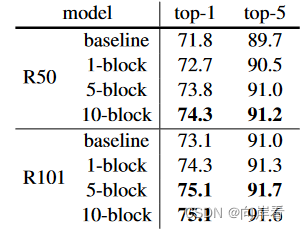
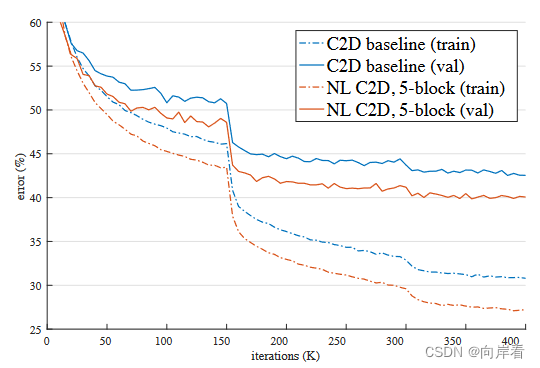
分别添加1,5,10个NL模块在ResNet50和ResNet100。
4. 单个NL模块添加在res3位置的进行对象检测和实例分割
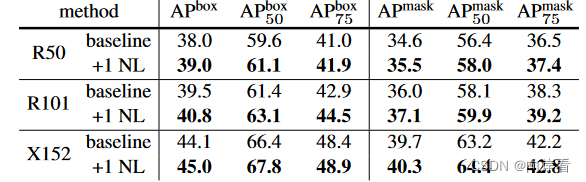
五、结论
NLNet通过非局部操作捕获远程依赖关系,NL模块通过残差连接保证了可以与任何现有架构相结合。NL模块巧妙地将非局部操作与多头注意力机制相结合的方法至今依然是热门的参考架构。正如本文在实验中所展示的,非局部操作是十分高效的,即使只有几层(例如5层),也能达到最佳效果。
六、代码实现
论文中给出的源码针对的是视频分类任务,在此贴出针对2D图像的源码:
# -*- coding: utf-8 -*-
"""
@Author : zhwzhong
@License : (C) Copyright 2013-2018, hit
@Contact : zhwzhong.hit@gmail.com
@Software: PyCharm
@File : nlrn.py
@Time : 2019/5/5 16:27
@Desc :
"""
import torch
from torch import nn
from torch.nn import functional as F
class _NonLocalBlockND(nn.Module):
def __init__(self, in_channels, gamma=0, inter_channels=None, dimension=3, sub_sample=True, bn_layer=True):
super(_NonLocalBlockND, self).__init__()
assert dimension in [1, 2, 3]
self.gamma = nn.Parameter(torch.ones(1)) * gamma
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0),
bn(self.in_channels)
)
# 参数数量与 channel 有关
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.phi = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)
def forward(self, x):
"""
:param x: (b, c, t, h, w)
:return:
"""
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1)
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
theta_x = theta_x.permute(0, 2, 1)
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
f = torch.matmul(theta_x, phi_x)
f_div_C = F.softmax(f, dim=-1)
y = torch.matmul(f_div_C, g_x)
y = y.permute(0, 2, 1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)
z = self.gamma * W_y + x
return z
class NONLocalBlock1D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock1D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=1, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock2D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock3D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock3D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=3, sub_sample=sub_sample,
bn_layer=bn_layer)
if __name__ == '__main__':
import torch
for (sub_sample, bn_layer) in [(True, True), (False, False), (True, False), (False, True)]:
img = torch.zeros(2, 3, 20)
net = NONLocalBlock1D(3, sub_sample=sub_sample, bn_layer=bn_layer)
out = net(img)
print(out.size())
img = torch.zeros(2, 3, 20, 20)
net = NONLocalBlock2D(3, sub_sample=sub_sample, bn_layer=bn_layer)
out = net(img)
print(out.size())
img = torch.randn(2, 3, 8, 20, 20)
net = NONLocalBlock3D(3, sub_sample=sub_sample, bn_layer=bn_layer)
out = net(img)
print(out.size())



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











