







一、本文介绍
🔥本文介绍使用IDConv模块改进YOLOv13网络模型,IDConv通过将传统的大核深度卷积操作分解为多个小的并行卷积分支(包括小方形卷积核、带状卷积核和身份映射),优化了计算效率。这种分解方式减少了计算量,同时保持了大感受野,增强了模型对长程依赖的捕捉能力。
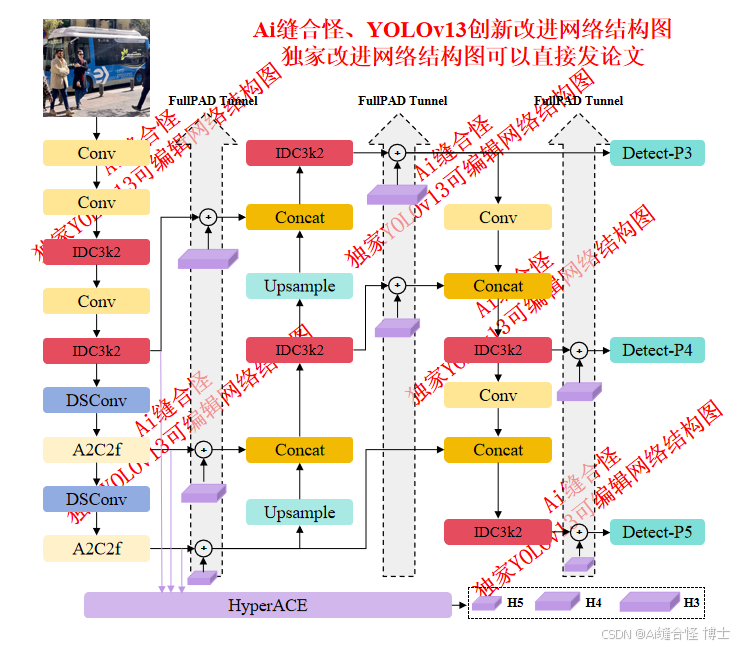
展示部分YOLOv13改进后的网络结构图、供小伙伴自己绘图参考:
🚀 创新改进结构图: yolov13n_IDC3k2.yaml
专栏改进目录:YOLOv13改进包含各种卷积、主干网络、各种注意力机制、检测头、损失函数、Neck改进、小目标检测、二次创新模块、HyperACE二次创新、独家创新等几百种创新点改进。
全新YOLOv13创新改进专栏链接:全新YOLOv13创新改进高效涨点+永久更新中(至少500+改进)+高效跑实验发论文
本文目录
1.首先在ultralytics/nn/newsAddmodules创建一个.py文件
2.在ultralytics/nn/newsAddmodules/__init__.py中引用
🚀 创新改进1 : yolov13n_IDC3k2.yaml
🚀 创新改进2 : yolov13n_INBC3k2.yaml
二、IDConv模块介绍

摘要:受到ViT(Vision Transformer)在长程建模能力方面的启发,最近大核卷积被广泛研究和应用,以扩大感受野并提高模型性能,例如ConvNeXt,它采用了7×7的深度卷积。尽管这种深度卷积操作的FLOPs较少,但由于高内存访问成本,它在强大计算设备上的效率较低。例如,ConvNeXt-T的FLOPs与ResNet-50相似,但在使用A100 GPU进行全精度训练时,其吞吐量仅为60%。虽然减小ConvNeXt的卷积核大小可以提高速度,但这会导致性能显著下降。如何在保留大核卷积CNN模型性能的同时提高速度仍不明确。为了解决这个问题,我们受Inception启发,提出将大核深度卷积分解为沿通道维度的四个并行分支,即小的方形卷积核、两个正交带状卷积核和身份映射。通过这种新的Inception深度卷积,我们构建了一系列网络,即InceptionNeXt,它不仅享有较高的吞吐量,而且保持了竞争力的性能。例如,InceptionNeXt-T比ConvNeX-T的训练吞吐量提高了1.6倍,同时在ImageNet-1K数据集上的Top-1准确率提高了0.2%。我们预期I

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 5013
5013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









