







题目一

遍历整个数组,调整每个位置上的数字,使得i位置上放的数是i+1,如果当前位置i不符合,将当前位置的数取出,放入到它该到的位置(根据值-1作为下标),那么又会有一个数取出,直到来到的位置上数已经是符合条件的,回到之前遍历到的位置i,继续遍历;当遍历到一遍之后,以数组中出现的数字-1为下标的位置都正确放入了数字,没出现的数字对应的位置,存储的数字不符合条件。
代码实现:
//下标连续怼
void p(vector<int>& arr, int val) {
while (arr[val - 1] != val) {
int temp = arr[val - 1];
arr[val - 1] = val;
val = temp;
}
}
vector<int> f(vector<int>arr) {
for (int i = 0; i < arr.size(); i++) {
if (arr[i] != i + 1) {
p(arr, arr[i]);
}
}
vector<int>res;
for (int i = 0; i < arr.size(); i++) {
if (arr[i] != i + 1) {
res.push_back(i + 1);
}
}
return res;
}
题目二
主播有一个初始时刻的人气值为a,想要到达的人气值为b,a、b都是偶数,且b>=a。有三种改变人气值的方式:1 点赞:花费x个金币,人气值+2;2 送礼:花费y个金币,人气值*2;3 私聊:花费z个金币,人气值-2。问人气值由a变成b至少需要花费多少金币?
错误的递归:见代码。该递归是跑不完的,因为只有递归的三个分支全部跑完,才能返回总的结果,例如对于-2的方式,永远存在-2的递归分支。缺乏递归的basecase。
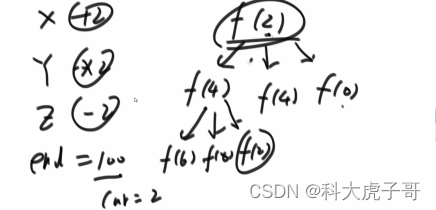
从问题的本身找basecase:1 找一个平凡解人为的增加basecase的限制条件:a b都是偶数,总能通过点赞的方式到达b,这意味着花费超过(b-a)*x/2的花费的都不是最终的答案,直接返回无穷大;2 人气值一定不会超过目标人气值的两倍,因为如果想要超过,必然在大于目标值的情况下继续增长,这是没有必要的
有时候写暴力尝试时,发现递归跑不完,两种思路优化:1) 找平凡解来增加递归结束的条件(basecase);2) 从业务中找不用递归的条件。平凡解是人为找到的一个满足题意,但不是最优的解,那么最终的答案一定不会比这个平凡解差,因此那些比平凡解差的答案一定不是最终答案,直接返回无效值。
代码实现:
//错误的递归
//x y z分别是三种改变人气值的方式花费
//ed:目标人气值
//cur:当前人气值
int f(int x, int y, int z, int ed, int cur) {
if (ed == cur) {
return 0;
}
int p1 = f(x, y, z, ed, cur + 2) + x;
int p2 = f(x, y, z, ed, cur * 2) + y;
int p3 = f(x, y, z, ed, cur - 2) + z;
return min(p1, min(p2, p3));
}
//正确的递归
//x y z分别是三种改变人气值的方式花费
//ed:目标人气值
//cur:当前人气值
//preMoney:之前的花费
//limitMoney:花费不能超过
// 两个可变参数:cur preMoney
//返回从cur到ed最少花费的钱数
int f2(int x, int y, int z, int ed, int cur, int preMoney, int limitMoney) {
if (ed == cur) {
return 0;
}
if (preMoney > limitMoney) {
return INT_MAX;
}
if (cur<0||cur >= 2*ed) {
return INT_MAX;
}
int p1 = f2(x, y, z, ed, cur + 2, preMoney + x, limitMoney);
int p2 = f2(x, y, z, ed, cur * 2, preMoney + y, limitMoney);
int p3 = f2(x, y, z, ed, cur - 2, preMoney + z, limitMoney);
p1 += p1 == INT_MAX ? 0 : x;
p2 += p2 == INT_MAX ? 0 : y;
p3 += p3 == INT_MAX ? 0 : z;
return min(p1, min(p2, p3));
}
int minCoins(int x, int y, int z, int ed, int cur) {
int limitMoney = (ed-cur) * x / 2;
return f2(x, y, z, ed, cur, 0, limitMoney);
}
题目三
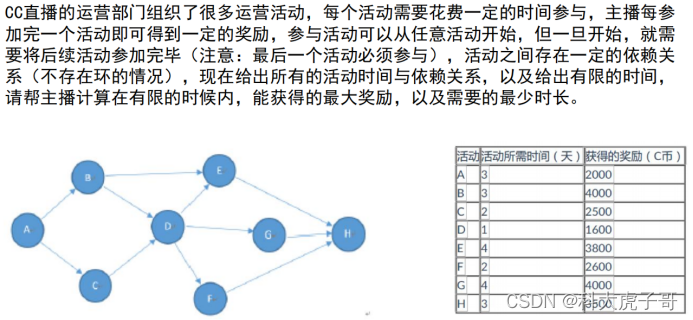

图的宽度利用优先遍历(反着遍历,从最后一个节点),遍历到每个点时建立自己的账目表map(key:从自己到做完最后一个活动需要的天数;value:从自己到做完最后一个活动获得的奖励);每个节点的账目表,要保证天数增加收益也增加,否则删除天数增加,收益减小的pair;最后将所有点的账目表合成一个大的账目表,也要保证天数增加收益也增加

代码实现:
//二维数组arr:每个活动的需要的天数和收益
//二维数组subActivity:每一行中的1表示当前活动紧跟着要完成的活动
//同时给定可用时长,返回最大收益和最少天数
class Node {
public:
int days;
int money;
map<int, int>mp;
vector<Node*>nexts;
vector<Node*>parents;//指向它的父节点,可能不止一个
};
//创建一个从最后一个活动一直往前指的树
Node* greatGraph(vector<vector<int>>& arr, vector<vector<int>>& subActivity) {
int N = arr.size();
vector<Node*>nodes(N);
//初始化各个节点
for (int i = 0; i < N; i++) {
nodes[i] = new Node();
nodes[i]->days = arr[i][0];
nodes[i]->money = arr[i][1];
}
//建立各结点的指向关系
for (int i = 0; i < N; i++) {
for (int j = 1; j < N; j++) {//第一列全部为0
if (subActivity[i][j] == 1) {
nodes[j]->nexts.push_back(nodes[i]);
nodes[i]->parents.push_back(nodes[j]);
}
}
}
//要求输入的依赖矩阵最后一行全为0
return nodes[N - 1];
}
//
void process(Node* head,Node*cur, map<int, int>&zong) {
if (cur == head) {
cur->mp.insert({ cur->days, cur->money });
zong.insert({ cur->days, cur->money });
}
else {
for (Node* parent : cur->parents) {//可能不知一个父节点,都要继承其他的账目表
for (pair<int, int>p : parent->mp) {
if ((cur->mp.find(cur->days + p.first) == cur->mp.end()) //之前没加入或者之前加入了,但是收益没有当前的高
|| (cur->mp[cur->days + p.first] < cur->money + p.second)) {
cur->mp[cur->days + p.first] = cur->money + p.second;
}
}
}
//当前节点的账目表建立完毕(可能不符合天数增收益也增,没关系,在总表中去重)
//将当前节点的账目表汇总到总的账目表
for (pair<int, int>p : cur->mp) {
if (zong.find(p.first) == zong.end() || zong[p.first] < p.second) {
zong[p.first] = p.second;
}
}
}
}
vector<int> f(vector<vector<int>>& arr, vector<vector<int>>& subActivity, int maxDays) {
int N = arr.size();//活动数
Node* head = greatGraph(arr, subActivity);
queue<Node*>q;
unordered_set<Node*>st;
q.push(head);
//st.insert(head);
map<int, int>zong;//总的账目表
//图的宽度优先遍历
while (!q.empty()) {
Node* cur = q.front();
q.pop();
process(head, cur, zong);
for (Node* n : cur->nexts) {
//一般图的宽度优先遍历要防止出现环,同时也让一个节点之访问一次,需要set记录已经访问的集合
//但是本题不会形成环,最重要的是,同一节点可能要访问多次
/*if (st.find(n) == st.end()) {
q.push(n);
st.insert(n);
}*/
q.push(n);
}
}
//总表去除天数增加但收益未增加的条目
map<int, int>::iterator it = zong.begin();
int pre = it->second;
it++;
while (it != zong.end()) {
if (it->second <= pre) {
//删除元素会使原来的迭代器失效,不能通过it++得到下一位置
//erase(iter)返回下一元素的迭代器
it = zong.erase(it);
}
else {
pre = it->second;
it++;
}
}
it = zong.upper_bound(maxDays);
it--;
vector<int>res;
res.push_back(it->first);
res.push_back(it->second);
return res;
}
题目四

在原始字符串进行逻辑运算的时候都要加上小括号,有多少加小括号的方式可用达到预期desired
假设每一个逻辑运算符都是最后结合的。范围上的尝试,int f(l,r,desire),从l…r字符串想要达到desire有多少加小括号的方式
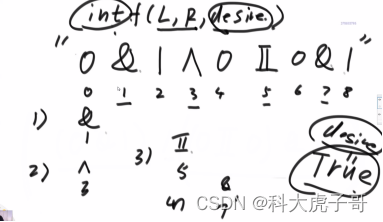
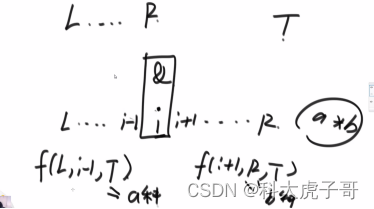
判断给出的字符串是否有效:
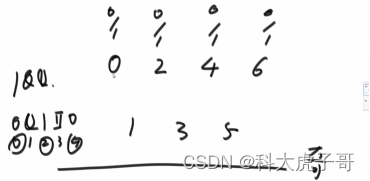
改动态规划:要观察哪些格子是不用填的,不用填的格子直接跳过
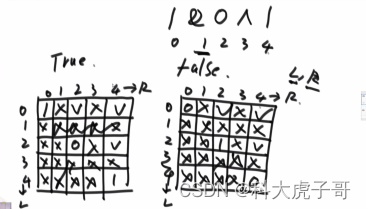
代码实现:
bool isValid(string s) {
if (s.length() % 2 == 0) {
return false;
}
for (int i = 0; i < s.length(); i += 2) {
if ((s[i] != '0' && s[i] != '1') ||
(i + 1 != s.length() && s[i + 1] != '|' && s[i + 1] != '&' && s[i + 1] != '^')) {
return false;
}
}
return true;
}
int p(string& s, int l, int r, bool desired) {
if (l == r) {
if (s[l] == '1') {
return desired ? 1 : 0;
}
else {
return desired ? 0 : 1;
}
}
int res = 0;
if (desired) {
for (int i = l + 1; i < r; i += 2) {
switch (s[i]) {
case '&':
res += p(s, l, i - 1, true) * p(s, i + 1, r, true);
break;
case '^':
res += p(s, l, i - 1, true) * p(s, i + 1, r, false);
res += p(s, l, i - 1, false) * p(s, i + 1, r, true);
break;
case '|':
res += p(s, l, i - 1, true) * p(s, i + 1, r, true);
res += p(s, l, i - 1, true) * p(s, i + 1, r, false);
res += p(s, l, i - 1, false) * p(s, i + 1, r, true);
break;
default:
break;
}
}
}
else {
for (int i = l + 1; i < r; i += 2) {
switch (s[i]) {
case '&':
res += p(s, l, i - 1, false) * p(s, i + 1, r, false);
res += p(s, l, i - 1, true) * p(s, i + 1, r, false);
res += p(s, l, i - 1, false) * p(s, i + 1, r, true);
break;
case '^':
res += p(s, l, i - 1, true) * p(s, i + 1, r, true);
res += p(s, l, i - 1, false) * p(s, i + 1, r, false);
break;
case '|':
res += p(s, l, i - 1, false) * p(s, i + 1, r, false);
break;
default:
break;
}
}
}
return res;
}
//改动态规划
int p2(string& s, bool desired) {
int len = s.length();
vector<vector<int>>dpTrue(len, vector<int>(len));
vector<vector<int>>dpFalse(len, vector<int>(len));
for (int i = 0; i < len; i += 2) {
if (s[i] == '1') {
dpTrue[i][i] = 1;
dpFalse[i][i] = 0;
}
else {
dpTrue[i][i] = 0;
dpFalse[i][i] = 1;
}
}
for (int k = 2; k < len; k += 2) {
for (int row = 0; row + k < len; row += 2) {
int col = row + k;
//上面几行代码表示按对角线遍历
for (int i = row + 1; i < col; i += 2) {
switch (s[i]) {
case '&':
dpTrue[row][col] += dpTrue[row][i - 1] * dpTrue[i + 1][col];
dpFalse[row][col] += dpFalse[row][i - 1] * dpFalse[i + 1][col];
dpFalse[row][col] += dpTrue[row][i - 1] * dpFalse[i + 1][col];
dpFalse[row][col] += dpFalse[row][i - 1] * dpTrue[i + 1][col];
break;
case '^':
dpTrue[row][col] += dpTrue[row][i - 1] * dpFalse[i + 1][col];
dpTrue[row][col] += dpFalse[row][i - 1] * dpTrue[i + 1][col];
dpFalse[row][col] += dpTrue[row][i - 1] * dpTrue[i + 1][col];
dpFalse[row][col] += dpFalse[row][i - 1] * dpFalse[i + 1][col];
break;
case '|':
dpTrue[row][col] += dpTrue[row][i - 1] * dpTrue[i + 1][col];
dpTrue[row][col] += dpTrue[row][i - 1] * dpFalse[i + 1][col];
dpTrue[row][col] += dpFalse[row][i - 1] * dpTrue[i + 1][col];
dpFalse[row][col] += dpFalse[row][i - 1] * dpFalse[i + 1][col];
break;
default:
break;
}
}
}
}
return desired ? dpTrue[0][len - 1] : dpFalse[0][len - 1];
}
题目五

**看到子串/子数组的问题就想以每个位置为结尾怎么样。**本题就是以i位置为结尾的最长无重复子串的长度;第一个瓶颈:当前字符s[i]上一次出现的位置,以当前字符为结尾的子串一定到不了该字符上一次出现的位置;第二个瓶颈:以s[i-1]为结尾的最长无重复子串的长度,再往前就有重复字符了
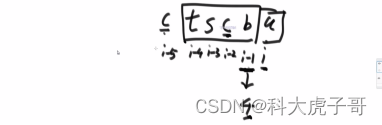
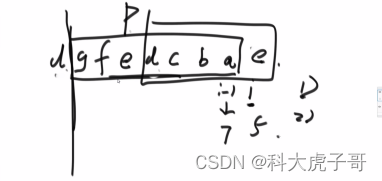
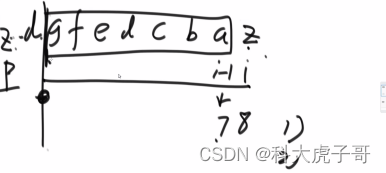
代码实现:
int maxUnique(string& s) {
if (s.length() == 0) {
return 0;
}
vector<int>mp(256, -1);//存放s[i]字符上次出现的位置
int len = 0;
int pre = -1;//前一个字符出现重复的位置
int cur = 0;//当前最大无重复子串的长度
for (int i = 0; i < s.length(); i++) {
pre = max(pre, mp[s[i]]);
cur = i - pre;
len = max(len, cur);
mp[s[i]] = i;
}
return len;
}
题目六

本题是距离编辑问题,每年都会出现
动态规划,dp[i][j]表示s1[0…i-1]编辑成s2[0…j-1]的最小代价;basecese:dp[0][j]表示空串编辑成s2[0…j-1]的最小代价,显然等于j×插入代价、dp[i][0]表示s1[0…i-1]编辑成空串的最小代价,显然等于i×删除代价;一般情况:
dp[i][j]=min(dp[i-1][j]+删除代价,dp[i][j-1]+插入代价,dp[i-1][j-1]+替换代价(如果最后一个字符相同,则替换代价为0))
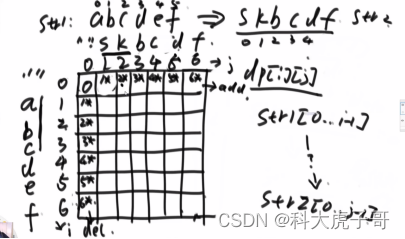

代码实现:
//ic:插入代价
//dc:删除代价
//rc:替换代价
int minCost(string& s1, string& s2, int ic, int dc, int rc) {
int len1 = s1.length();
int len2 = s2.length();
vector<vector<int>>dp(len1 + 1, vector<int>(len2+1));
for (int j = 0; j < len2; j++) {
dp[0][j] = j * ic;
}
for (int i = 0; i < len1; i++) {
dp[i][0] = i * dc;
}
for (int i = 1; i < len1+1; i++) {
for (int j = 1; j < len2+1; j++) {
if (s1[i] == s2[j]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = dp[i - 1][j - 1] + rc;
}
dp[i][j] = min(dp[i][j], dp[i - 1][j] + dc);
dp[i][j] = min(dp[i][j], dp[i][j - 1] + ic);
}
}
return dp[len1][len2];
}
题目七

首先建立词频表;遍历字符串,没到一个位置将对应的字符在词频表中减1,直到出现减完之后等于0的字符,从当前位置往前划定范围,该范围之内的选择一个字符并删除其左侧的所有字符都不会使字符串缺少一种字符;选择其中ASCII码最小的保留,并且删除左侧的所有字符,以及删除右侧所有选定的字符;重新建立词频表;重复上述操作,直到字符串为空。
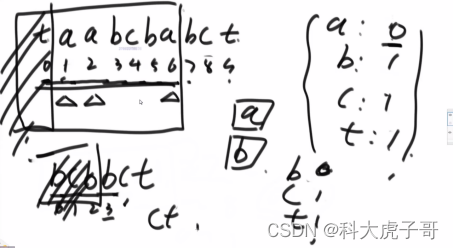
string removeStr(string s) {
if (s.length() < 2) {
return s;
}
vector<int>mp(26);//小写字母的ASCII的范围:97-122
for (char c : s) {
mp[c - 97]++;
}
int minAsciiIndex = 0;
for (int i = 0; i < s.length(); i++) {
mp[s[i] - 97]--;
minAsciiIndex = s[i] < s[minAsciiIndex] ? i : minAsciiIndex;
if (mp[s[i] - 97] == 0) {
break;
}
}
string res = "";
res+=s[minAsciiIndex];
s.erase(0, minAsciiIndex);//erase(int pos, int n):删除从Pos开始的n个字符
int i = s.find(res[0]);//find(char c)查找字符c在字符串中第一次出现的位置,找到返回位置,找不到返回-1
while (i != -1) {
s.erase(i, 1);
i = s.find(res[0]);
}
return res + removeStr(s);
}
题目八

abcdefghi…z中的所有子序列进行编号,字典序靠前的号越小,a…z分别为1…26;ab为27、ac为28…;注意不是而十六进制,是对子序列进行编号,不存在ASCII码大的字符位于ASCII码小的字符前面的情况。给定一个子序列,输出他的编号?
f(N):长度为N的子序列一共有多少个
g(char,len):以char为开头的长度为len的子序列一共有多少个
假设给定的字符串为dhv,他的编号一定在这么几部分之后:1) 长度为1的所有子序列和长度为2的所有子序列;2) 以a/b/c开头的所有长度为3的所有子序列;3) 以d开头,以e/f/g为第二个字符的所有子序列;4 以dh为开头,以h/i/j…u为第三个字符的所有子序列。以上几个部分相加再加一就是dhv的编号。
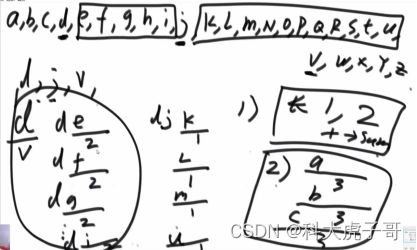
代码实现:
//返回以abcdef..z中的第i个字符为开头长度为len的子序列多少个
//i从1开始
int g(int i, int len) {
if (len == 1) {//如果len大于i到z的长度,最后的返回为0,basecase没有问题
return 1;
}
int sum = 0;
for (int j = i + 1; j <= 26; j++) {
sum += g(j, len - 1);
}
return sum;
}
//返回长度为len的子序列的个数
int f(int len) {
int sum = 0;
for (int i = 1; i <= 26; i++) {
sum += g(i, len);
}
return sum;
}
//获得编码
int getCode(string& s) {
int sum = 0;
int len = s.length();
//所有长度小于len的子序列
for (int i = 1; i < len; i++) {
sum += f(i);
}
//长度为len,开头字符小于s[0]的子序列
for (int j = 1; j < s[0] - 'a' + 1; j++) {
sum += g(j, len);
}
//s前i个字符固定
for (int i = 1; i < len; i++) {
for (int j = s[i - 1] - 'a' + 2; j < s[i] - 'a' + 1; j++) {
//注意j不能从1开始,因为要满足子序列的条件
//j必须比s[i-1]的字符大
sum += g(j, len - i);
}
}
return sum + 1;
}
//动态规划版
//g函数改动态规划
vector<vector<int>> gdp() {
//dp[i][j]:以第i个字符开始,长度为j的子序列长度
//i从1开始
vector<vector<int>>dp(27, vector<int>(27));//i=0行不用;j=0列也不用
for (int i = 1; i < 27; i++) {
dp[i][1] = 1;
}
for (int j = 2; j < 27; j++) {
for (int i = 1; i < 27; i++) {
for (int k = i + 1; k < 27; k++) {
dp[i][j] += dp[k][j - 1];
}
}
}
return dp;
}
//f函数改动态规划
vector<int> fdp() {
vector<int>dp(27);//0位置不用
vector<vector<int>>gDp = gdp();
for (int i = 1; i < 27; i++) {
for (int j = 1; j < 27; j++) {
dp[i] += gDp[j][i];
}
}
return dp;
}
//获得编码
int getCodeByDp(string& s) {
vector<vector<int>>gDp = gdp();
vector<int>fDp = fdp();
int sum = 0;
int len = s.length();
for (int i = 1; i < len; i++) {
sum += fDp[i];
}
for (int j = 1; j < s[0] - 'a' + 1; j++) {
sum += gDp[j][len];
}
for (int i = 1; i < len; i++) {
for (int j = s[i - 1] - 'a' + 2; j < s[i] - 'a' + 1; j++) {
sum += gDp[j][len-i];
}
}
return sum + 1;
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









