







就很快,YOLOv13它又来了。。。
Github仓库:https://github.com/iMoonLab/yolov13
论文:https://arxiv.org/pdf/2506.17733
YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception
1.模型概述和结构
1.1 推理速度和精度
- mAP比之前YOLO系列的模型都高
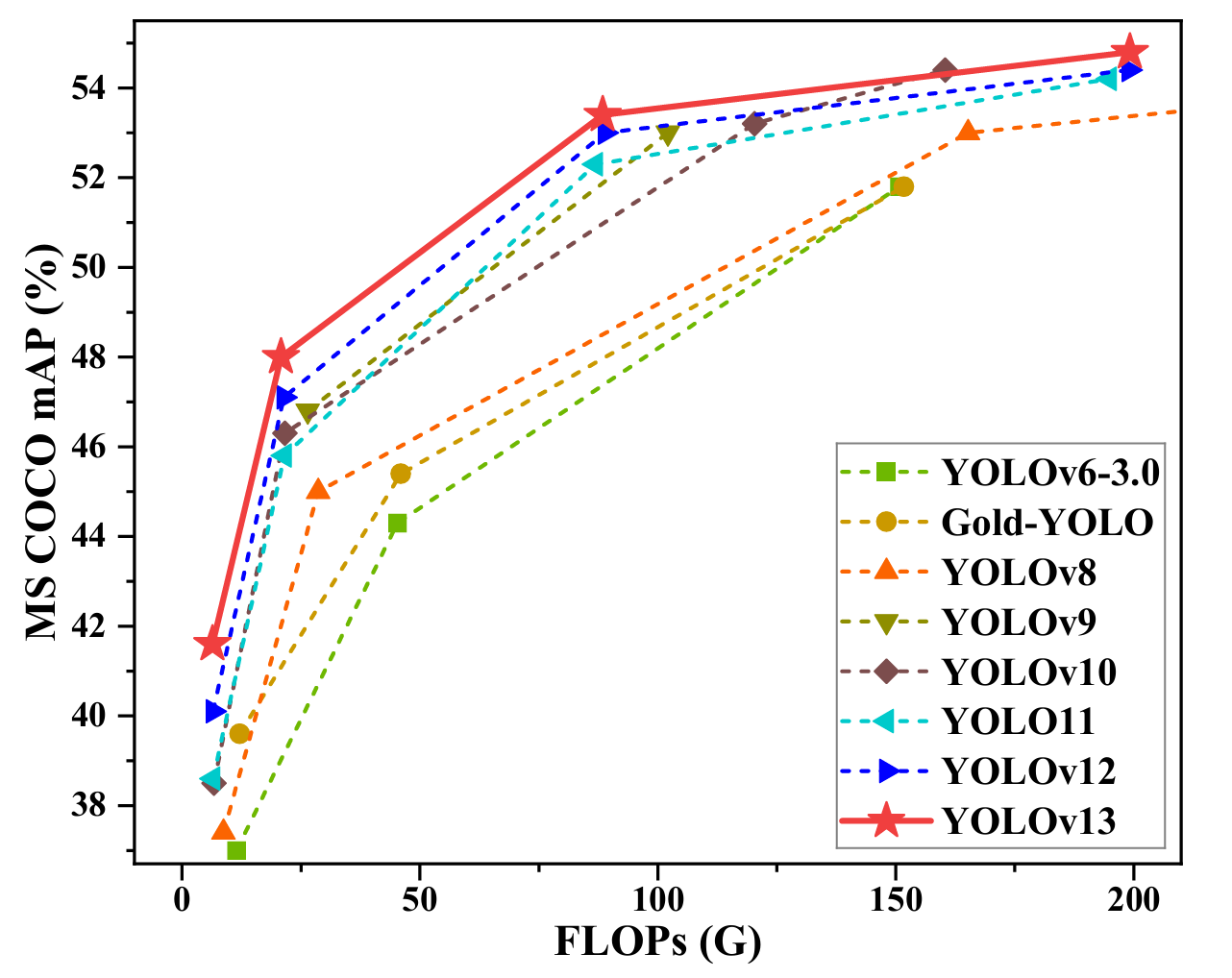
- 2.论文中对比了YOLO系列各模型的速度,可以看到速度方面不如yolov8、yolo11
1.2 模型结构
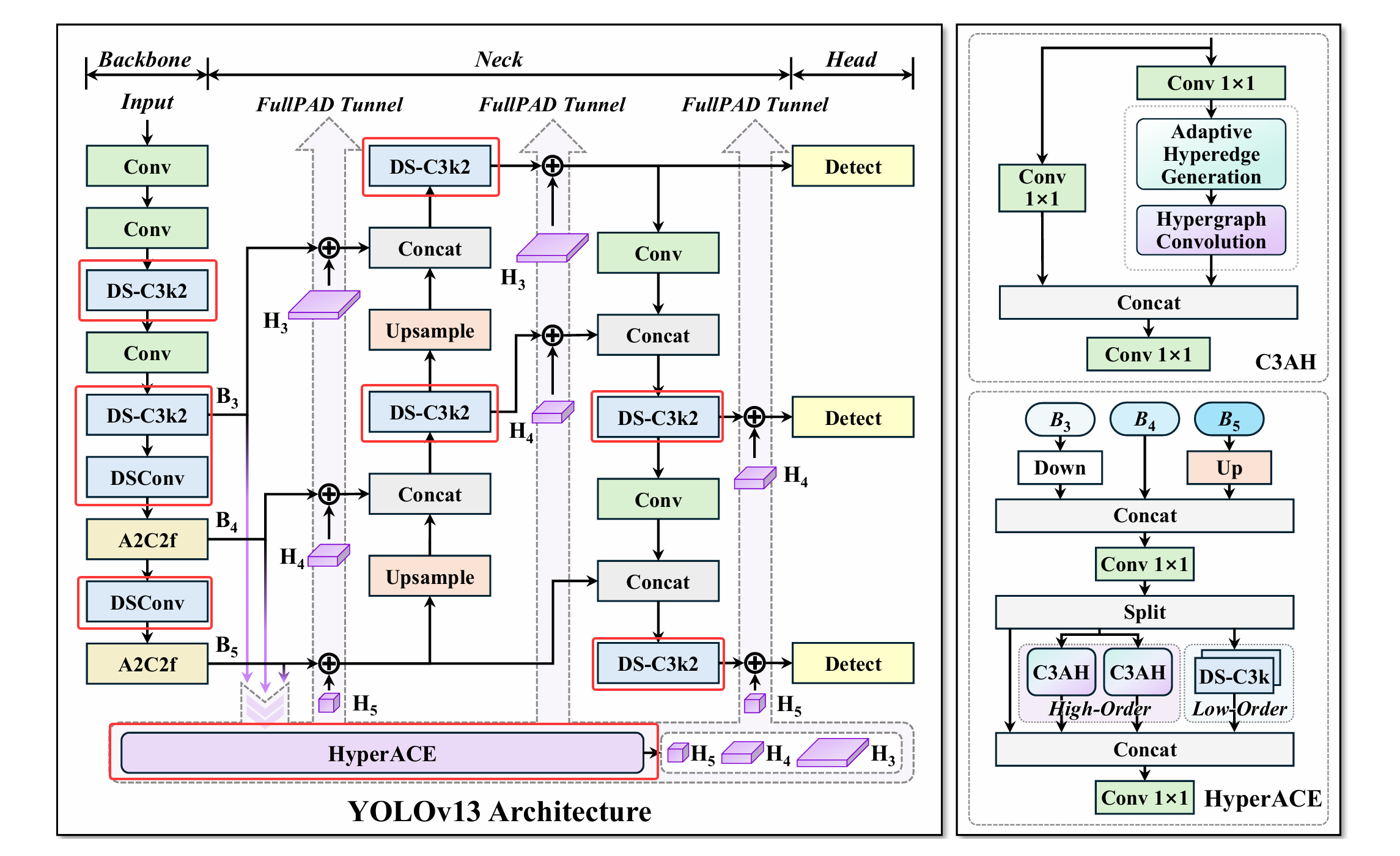
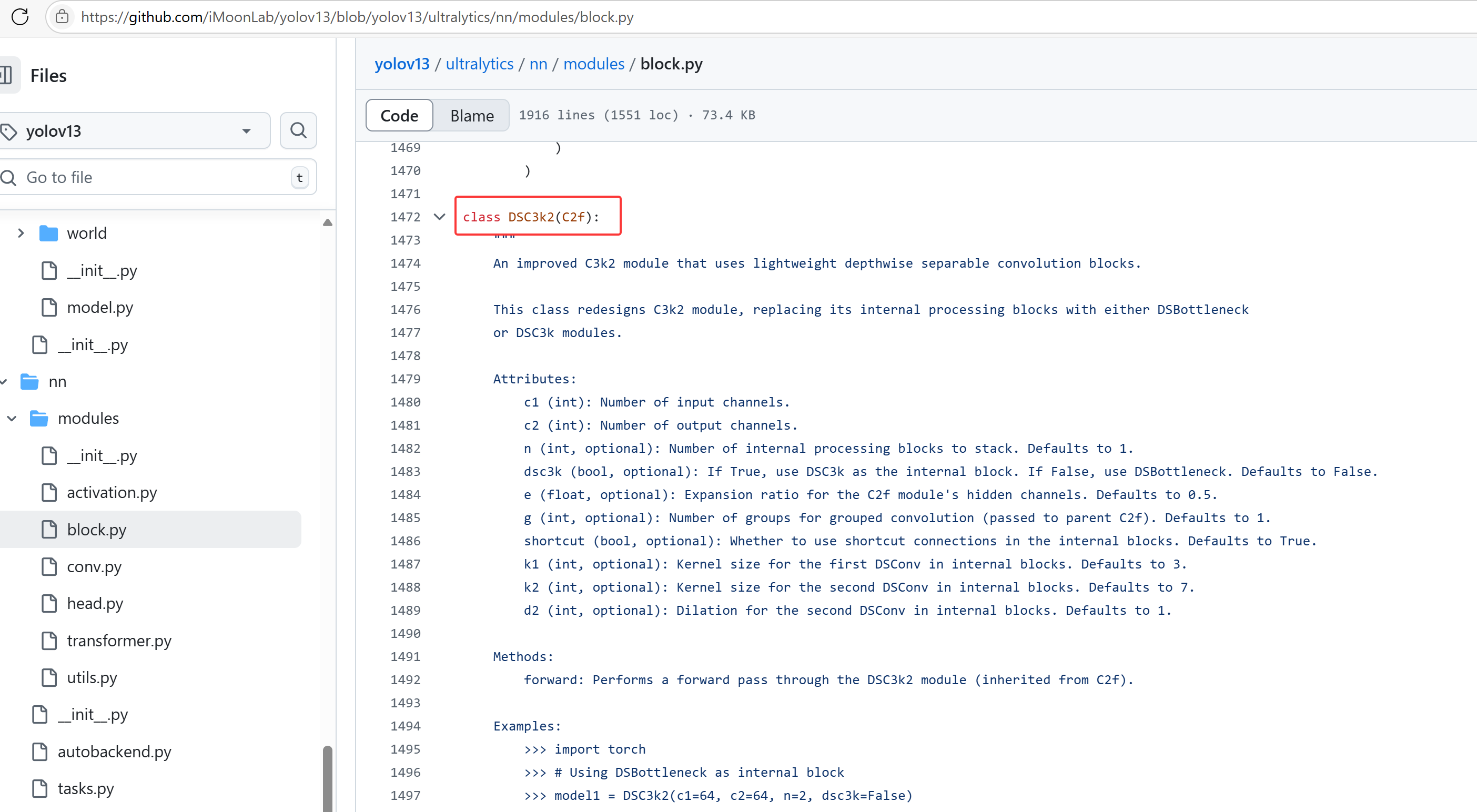
- 1.
深度可分离卷积(DSConv、DS-Bottleneck、DS-C3k、DS-C3k2)

大核卷积:
1.增加感受野:较大的卷积核可以一次性捕获更多的输入信息。比如,3x3卷积核只能捕获局部的信息,而5x5、7x7卷积核可以捕获更大范围的特征。
2.减少层数:使用大核卷积可以减少所需的卷积层数,因为它已经能够捕捉到更大的特征,避免了堆叠多个小核(如多个3x3卷积)的需要。
- 2.
HyperACE:基于 Hypergraph 超图增强自适应的功能
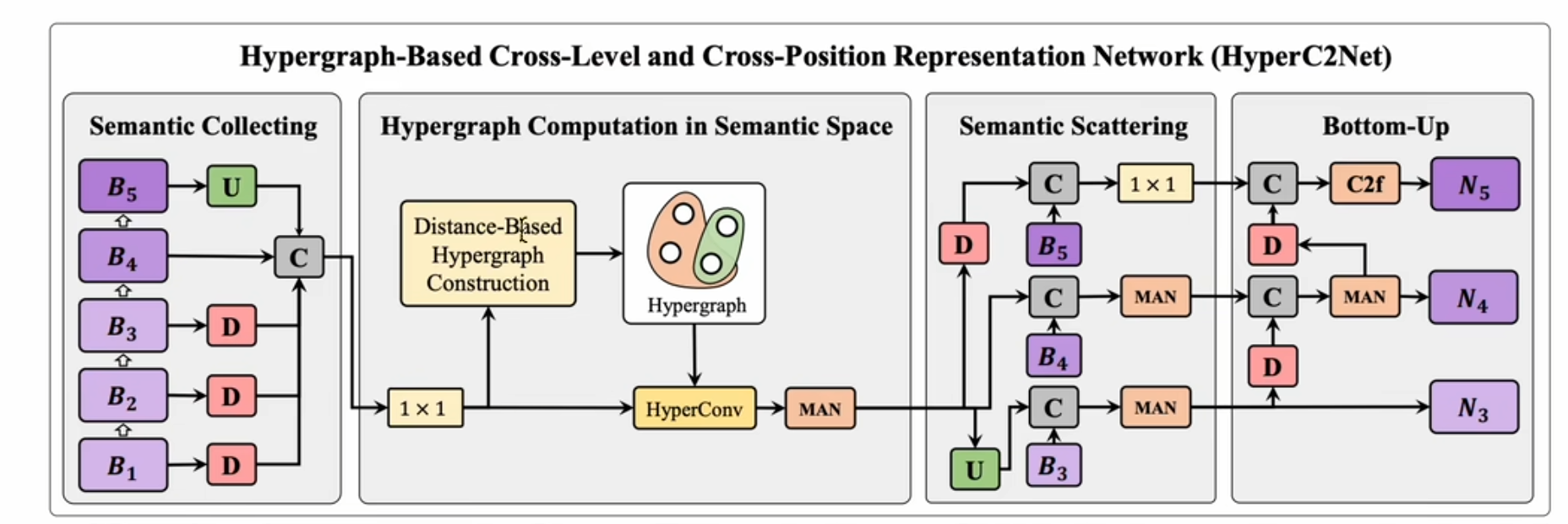
根据YOLOv13的网络结构可以看到将P3、P4、P5的特征都送到了超图增强的模块里面,再分别送出对应这三个尺度的特征,然后在不同位置都做了特征融合。
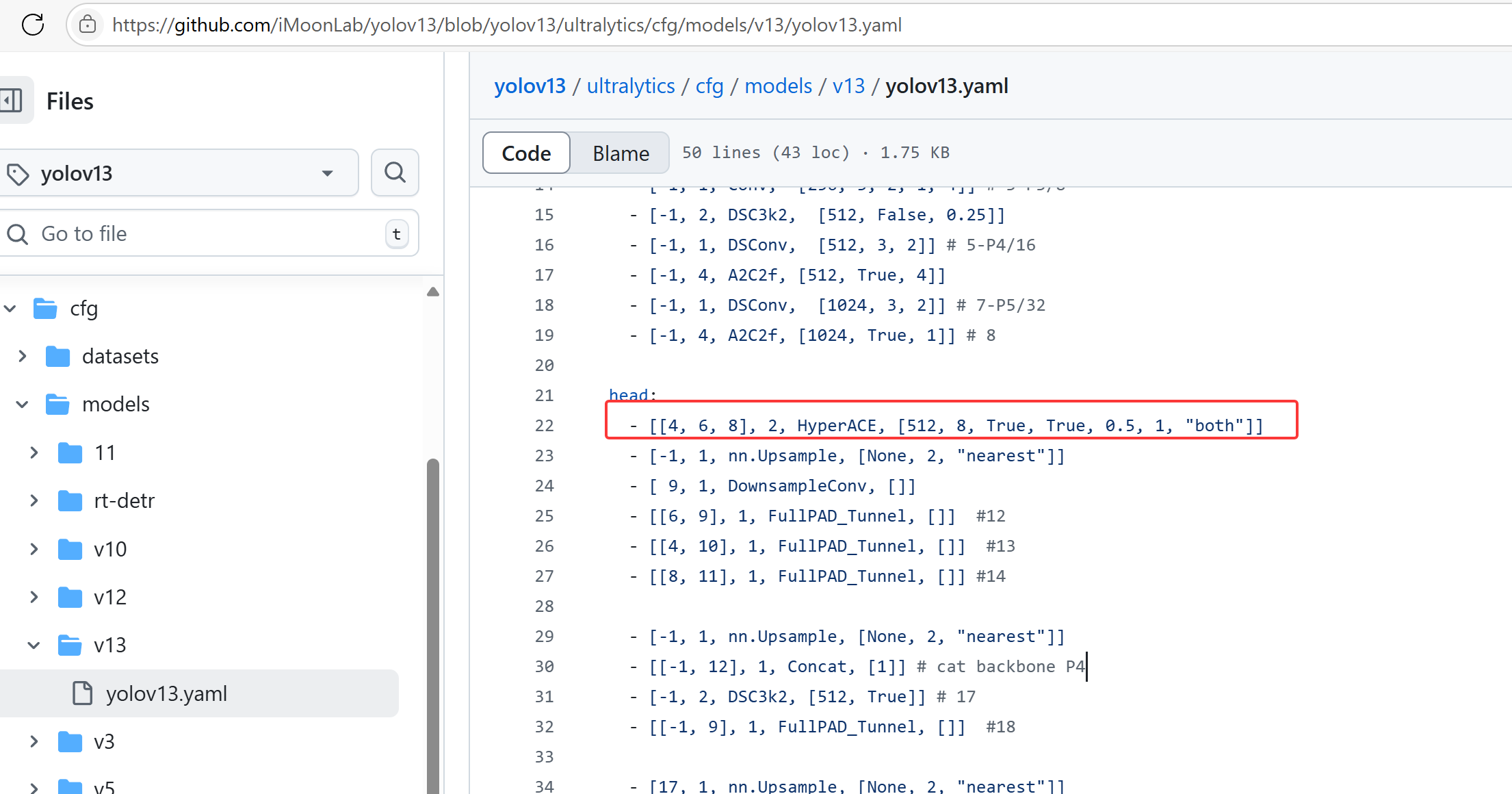
2.模型训练和部署
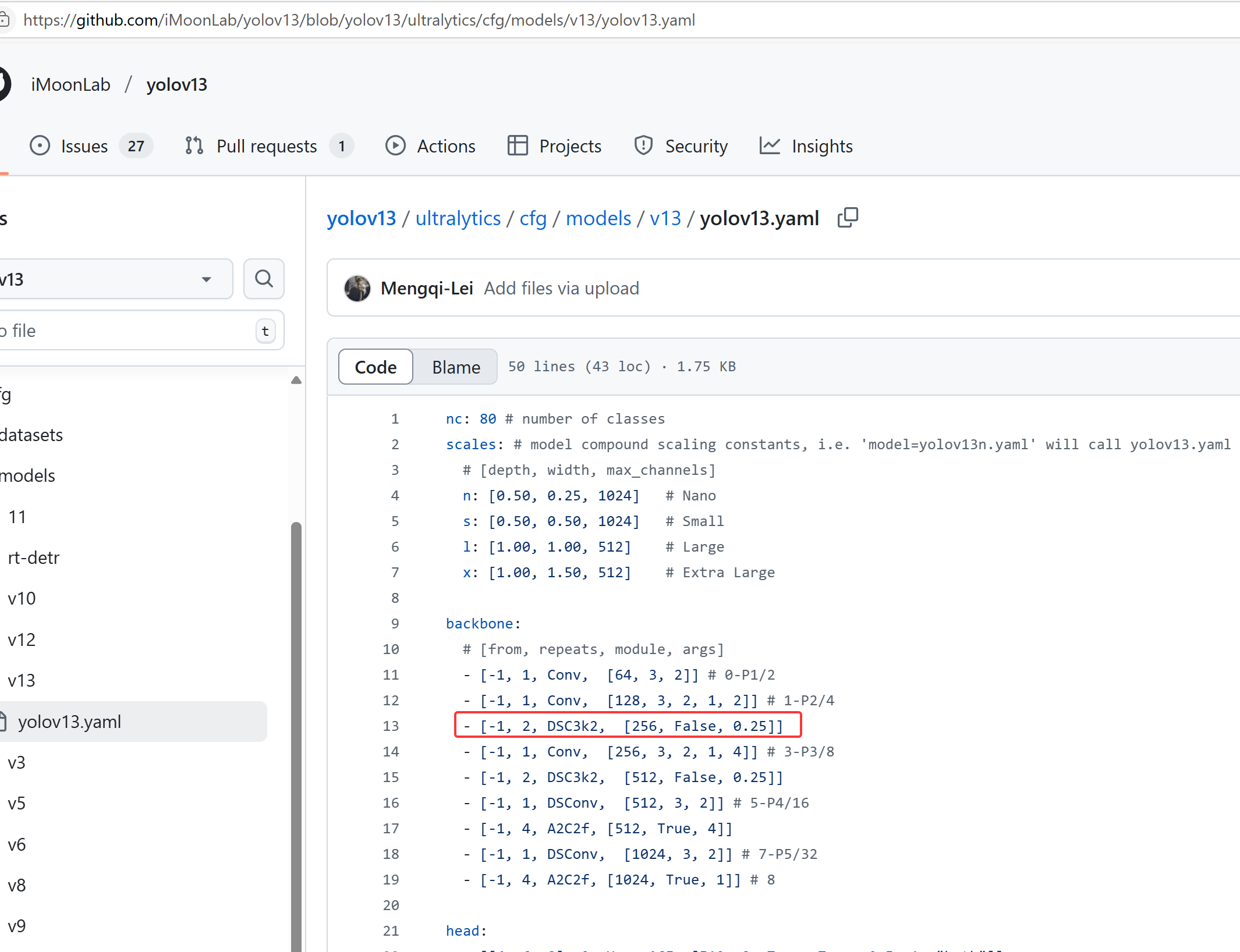
- 1.预训练模型下载,因为当前只有一个tag,直接下载相应的预训练模型
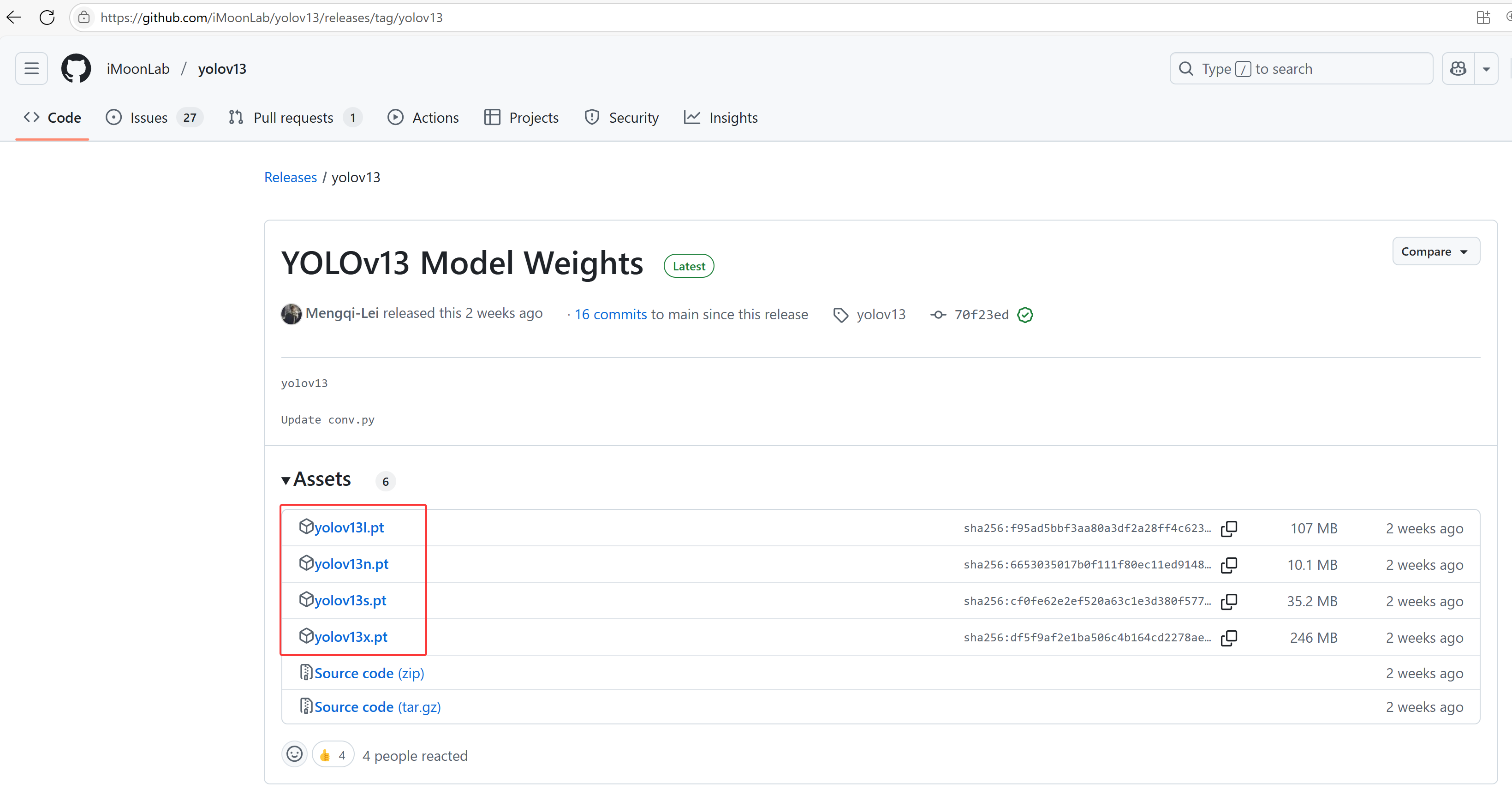
- 2.这里以
yolov13n.pt为例,通过如下代码将其转为ONNX格式
from ultralytics import YOLO
model = YOLO('yolov13n.pt')
model.export(format="onnx", half=False)
通过网络结构可以看到,yolov13和之前的yolo11、yolov8等输入与输出一样,没有变化
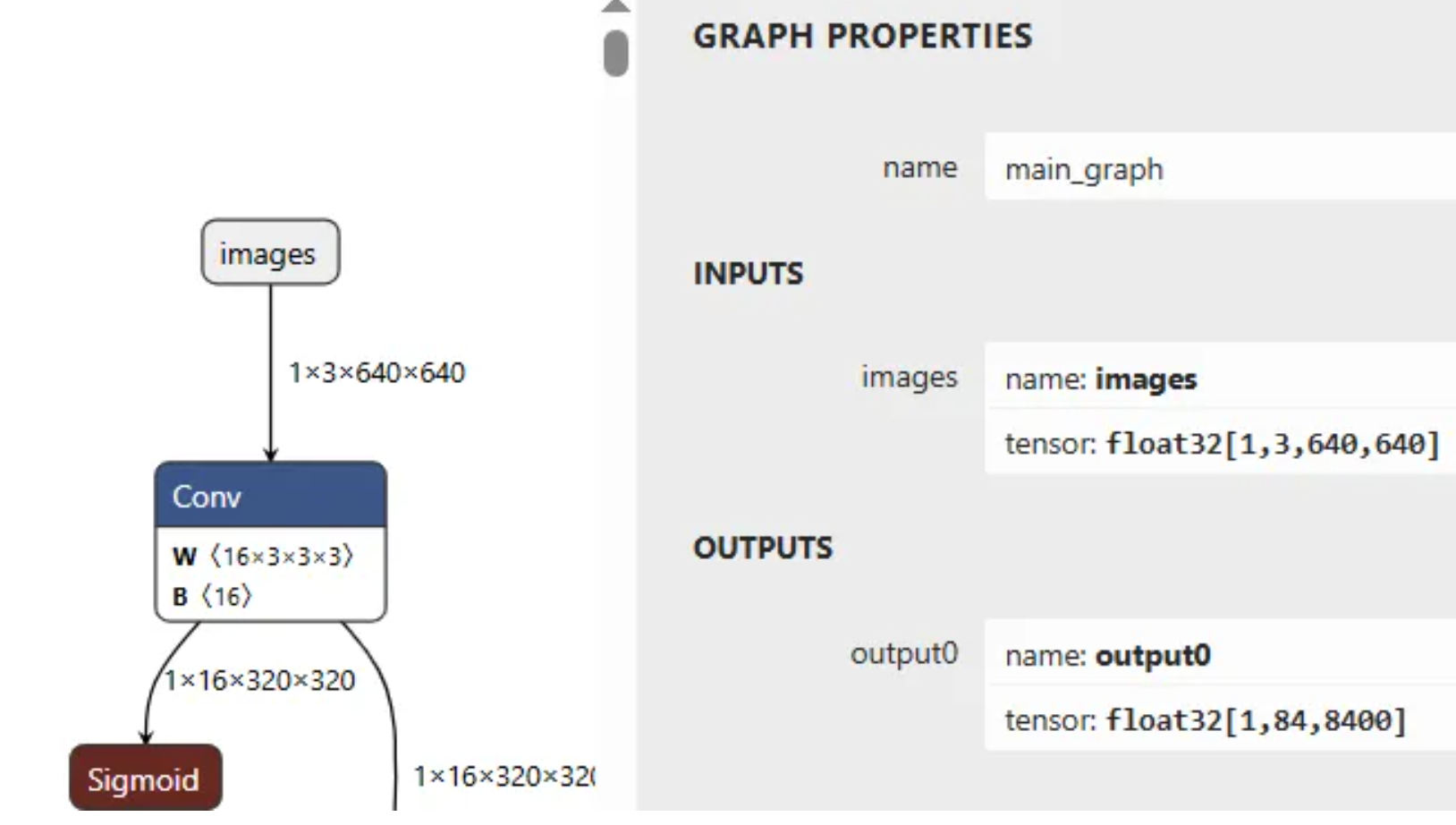
- 3.后面的推理和部署可以直接用yolo11的那套代码,无缝衔接
https://blog.youkuaiyun.com/qq_45445740/article/details/145509386
3.总结
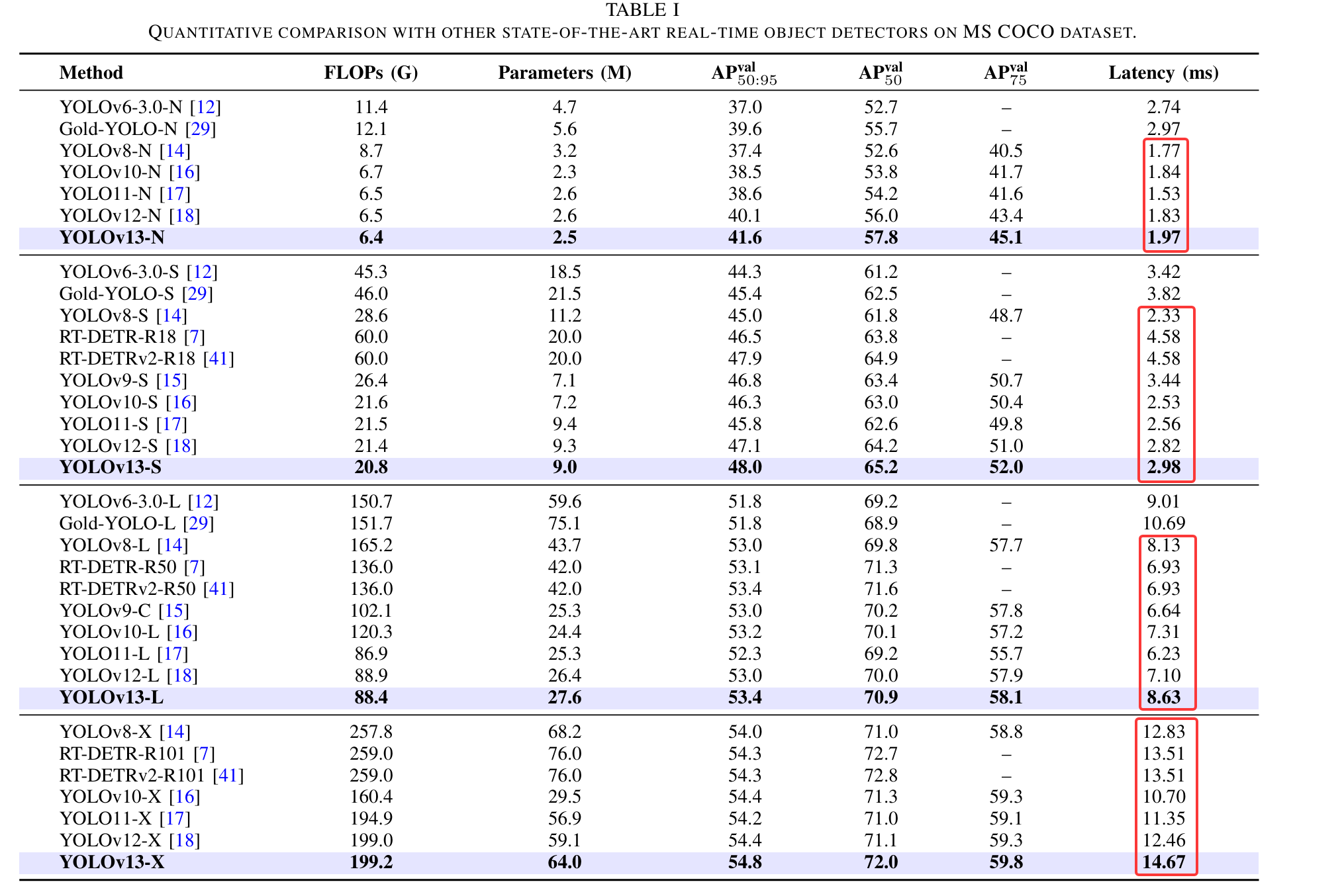
- 1.在推理速度方面,yolov13比不上yolo11、yolov8等,论文显示mAP稍微高点。
- 2.创新方面,深度可分离卷积和基于 Hypergraph 超图增强。
- 3.官方目前只提供了对象检测相关的预训练模型,其他如分割、关键点检测等预训练模型尚未提供,工程化落地目前不太友好。


















 2539
2539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











