




 本文详细解析了DataX的执行流程,从入口类开始,包括配置封装、JobContainer和TaskGroupContainer容器的启动,重点介绍了TaskExecutor类在任务调度和执行中的作用。DataX通过PluginLoader加载插件,初始化Job和Task,根据配置进行任务切分,最后利用TaskExecutor执行读写操作,实现数据同步。
本文详细解析了DataX的执行流程,从入口类开始,包括配置封装、JobContainer和TaskGroupContainer容器的启动,重点介绍了TaskExecutor类在任务调度和执行中的作用。DataX通过PluginLoader加载插件,初始化Job和Task,根据配置进行任务切分,最后利用TaskExecutor执行读写操作,实现数据同步。
具体流程代码
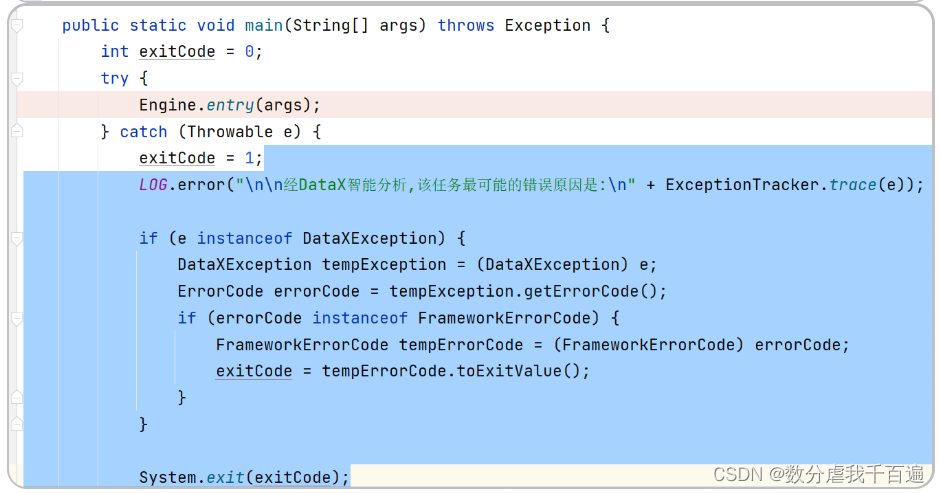
step1: 入口
知识点:
- 首先入口在
com.alibaba.datax.core.Engine类,命令行参数有-job、-jobid和-mode
options.addOption("job", true, "Job config.");
options.addOption("jobid", true, "Job unique id.");
options.addOption("mode", true, "Job runtime mode.");
step2: 封装配置
entry()先获取命令行参数-mode,-jobid,-job。- 解析系统配置的
json和用户自己编辑的json文件配置,然后统一封装成Configuration类,传给Engine.start()使用。
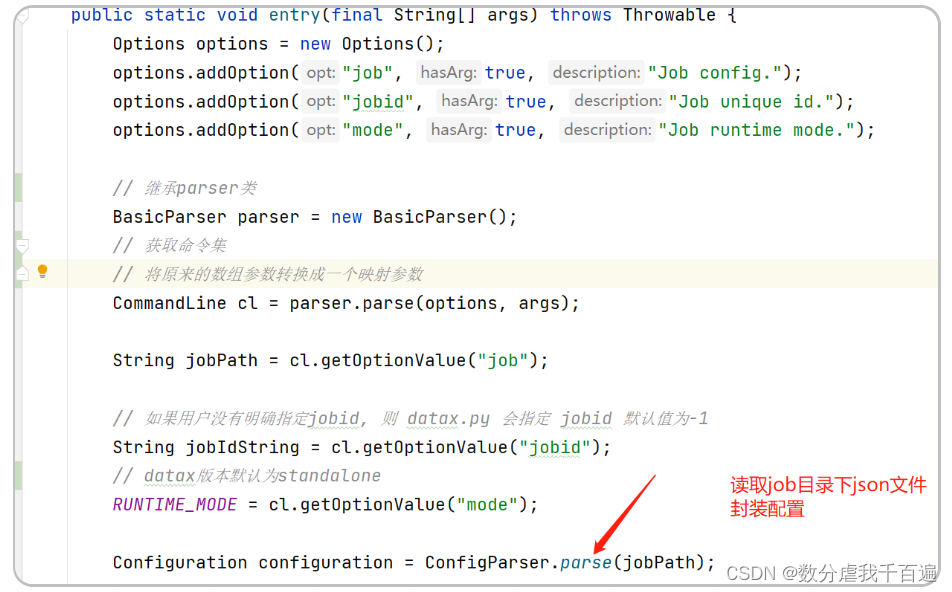
- 读取核心配置文件
core.json以及对应读写的plugin.json
configuration.merge(
// 读取核心core.json
ConfigParser.parseCoreConfig(CoreConstant.DATAX_CONF_PATH),
false);
// todo config优化,只捕获需要的plugin
String readerPluginName = configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_READER_NAME);
String writerPluginName = configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_WRITER_NAME);
- 这里获取的参数
jobid,如果用户没有明确的指定,则datax.py会指定jobid默认值为-1。
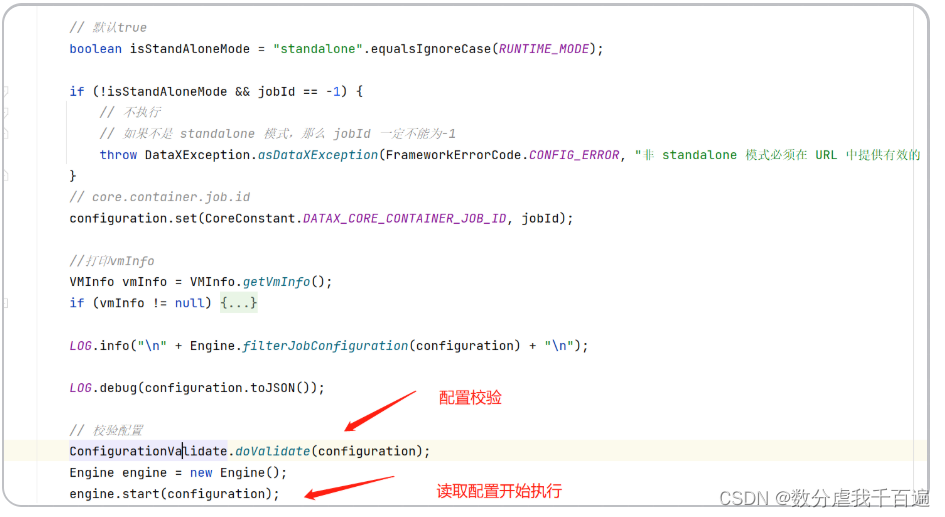
Engine的start()主要完成:
- 首先往配置类中绑定一些信息,比如ColumnCast等转换信息。
- 初始化PluginLoader(插件加载器), 用来获取插件配置
- 创建JobContainer,并且启动,JobContainer是一次数据同步job的运行容器.
public void start(Configuration allConf) {
// 绑定column转换信息 包括json中的字符信息
ColumnCast.bind(allConf);
/**
* 初始化PluginLoader,可以获取各种插件配置
*/
LoadUtil.bind(allConf);
// DATAX_CORE_CONTAINER_MODEL: core.container.model
boolean isJob = !("taskGroup".equalsIgnoreCase(allConf
.getString(CoreConstant.DATAX_CORE_CONTAINER_MODEL)));
//JobContainer会在schedule后再行进行设置和调整值
int channelNumber =0;
// 抽象容器类 有两种实现 JobContainer和TaskGroupContainer
AbstractContainer container;
long instanceId;
int taskGroupId = -1;
if (isJob) {
allConf.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, RUNTIME_MODE);
container = new JobContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, 0);
} else {
// 基本用不到
container = new TaskGroupContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);
taskGroupId = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID);
channelNumber = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL);
}
//缺省打开perfTrace
boolean traceEnable = allConf.getBool(CoreConstant.DATAX_CORE_CONTAINER_TRACE_ENABLE, true);
boolean perfReportEnable = allConf.getBool(CoreConstant.DATAX_CORE_REPORT_DATAX_PERFLOG, true);
//standalone模式的 datax shell任务不进行汇报
if(instanceId == -1){
perfReportEnable = false;
}
// todo 不太明白这里要做什么
int priority = 0;
try {
priority = Integer.parseInt(System.getenv("SKYNET_PRIORITY"));
}catch (NumberFormatException e){
LOG.warn("prioriy set to 0, because NumberFormatException, the value is: "+System.getProperty("PROIORY"));
}
// 总配置文件中提取出跟一个job有关的配置
Configuration jobInfoConfig = allConf.getConfiguration(CoreConstant.DATAX_JOB_JOBINFO);
//初始化PerfTrace
PerfTrace perfTrace = PerfTrace.getInstance(isJob, instanceId, taskGroupId, priority, traceEnable);
perfTrace.setJobInfo(jobInfoConfig,perfReportEnable,channelNumber);
container.start();
}
step3: 初始化并启动JobContainer容器
- 根据配置初始化不同的容器(
JobContainer和TaskGroupContainer)并启动,一般都使用Job容器,check job model first,位置com.alibaba.datax.core.JobContainer#start。 job实例运行在jobContainer容器中,它是所有任务的master,负责初始化、拆分、调度、运行、回收、监控和汇报,但它并不做实际的数据同步操作。JobContainer主要负责的工作全部在start()中,包括init、prepare、split、scheduler。init()负责Reader、Writer插件的初始化和热加载。prepare()方法做Read、Write前置准备(如Presql等)split()方法根据配置的并发参数(channel、bytes和Record必须配置其一,优先级bytes>=Record>channel),对job进行切分,返回多个task的配置列表。scheduler()是真正的调度任务与运行,task的调度方式按照轮询式。
@Override
public void start() {
LOG.info("DataX jobContainer starts job.");
boolean hasException = false;
boolean isDryRun = false;
try {
// 计时开始
this.startTimeStamp = System.currentTimeMillis();
// 预检查
isDryRun = configuration.getBool(CoreConstant.DATAX_JOB_SETTING_DRYRUN, false);
if(isDryRun) {
///...省略,几乎用不到
} else {
//clone一份配置,因为要做修改
userConf = configuration.clone();
//前置处理
this.preHandle();
//初始化read和write插件
this.init();
//进行插件的前置操作,有些插件不需要
this.prepare();
//切分任务,为并发做准备 主要adjustChannelNumber
this.totalStage = this.split();
//任务调度,启动任务 轮询式
this.schedule();
//和preparea对应,插件的后置操作
this.post();
//任务后置处理
this.postHandle();
//触发勾子 应该是用于异常检测
this.invokeHooks();
}
} catch (Throwable e) {
///...省略其他代码
} finally {
///...省略其他代码
}
}
-
init()方法
init()方法用于初始化read和writer插件,其中包括通过类加载器加载指定插件,将配置文件的内容赋值到read和write插件的内部变量,方便后续的调用。这里涉及到jar包热加载以及调用插件init()操作方法,初始化之后容器中的读写变量就是具体插件了。
private void init() {
this.jobId = this.configuration.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, -1);
if (this.jobId < 0) {
LOG.info("Set jobId = 0");
this.jobId = 0;
this.configuration.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_ID,
this.jobId);
}
// 开启线程
Thread.currentThread().setName("job-" + this.jobId);
// 这里不太懂
JobPluginCollector jobPluginCollector = new DefaultJobPluginCollector(
this.getContainerCommunicator());
//必须先Reader ,后Writer 因为jobWriter里有的参数是根据jobReader设置的
this.jobReader = this.initJobReader(jobPluginCollector);
this.jobWriter = this.initJobWriter(jobPluginCollector);
}
initJobReader()方法主要是利用了URLClassLoader()对插件进行了一个类加载,可以找到指定目录下的插件进行一个加载。加载到后会调用插件自己内部的init()方法进行个性初始化。
private Reader.Job initJobReader(
JobPluginCollector jobPluginCollector) {
// 读取源插件名
this.readerPluginName = this.configuration.getString(
CoreConstant.DATAX_JOB_CONTENT_READER_NAME);
// jar包热加载
classLoaderSwapper.setCurrentThreadClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.readerPluginName));
// 初始化reader插件
Reader.Job jobReader = (Reader.Job) LoadUtil.loadJobPlugin(
PluginType.READER, this.readerPluginName);
// 设置reader的jobConfig
jobReader.setPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_READER_PARAMETER));
// 设置reader的readerConfig
jobReader.setPeerPluginJobConf(this.configuration.getConfiguration(
CoreConstant.DATAX_JOB_CONTENT_WRITER_PARAMETER));
// 加入插件集合
jobReader.setJobPluginCollector(jobPluginCollector);
// 调用插件的init()方法
jobReader.init();
// 重置回原来的类加载器
classLoaderSwapper.restoreCurrentThreadClassLoader();
return jobReader;
}
以MysqlReader插件的init()为例, 使用通用关系型数据库的初始化方法, 处理username、password, 查询条件Where以及数据库配置:
@Override
public void init() {
this.originalConfig = super.getPluginJobConf();
Integer userConfigedFetchSize = this.originalConfig.getInt(Constant.FETCH_SIZE);
if (userConfigedFetchSize != null) {
LOG.warn("对 mysqlreader 不需要配置 fetchSize, mysqlreader 将会忽略这项配置. 如果您不想再看到此警告,请去除fetchSize 配置.");
}
this.originalConfig.set(Constant.FETCH_SIZE, Integer.MIN_VALUE);
this.commonRdbmsReaderJob = new CommonRdbmsReader.Job(DATABASE_TYPE);
this.commonRdbmsReaderJob.init(this.originalConfig);
}
- split()方法
经过init()方法和prepare()方法后进入到任务执行前最重要的一个步骤,也就是任务的切分。
split()主要是根据needChannelNumber对Reader和Writer进行拆分,每个reader和writer插件都有自己的split()方法。JobContainer中前面已经初始化的jobReader,会根据配置和自身条件,拆分内部配置好的Configuration(前面赋值了的对应配置文件,内包含需要同步的数据的全部信息)- 拆分之后会返回一个
Configuration的List,每个Configuration代表原先总配置文件中需要同步的数据的一部分。并加入到总配置文件存储,为后续调用提供配置的支持。 - 注意必须先切分
Reader,因为Writer是根据Reader切分后的数目进行切分的。也就是说读取源和写入源是1:1通道。 - 最终切分完成的
ReaderConfigration、WriterConfigration与TransformerConfigration会通过mergeReaderAndWriterTaskConfigs合并为一个整体的task的配置contentConfig。
private int split() {
// 调整切分数量
this.adjustChannelNumber();
//获取切分参考数,设置管道数量
if (this.needChannelNumber <= 0) {
this.needChannelNumber = 1;
}
List<Configuration> readerTaskConfigs = this
.doReaderSplit(this.needChannelNumber);
int taskNumber = readerTaskConfigs.size();
// 保证写入段切分的任务数和源端对等
List<Configuration> writerTaskConfigs = this
.doWriterSplit(taskNumber);
//获取job.content[0].transformer的配置
List<Configuration> transformerList = this.configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT_TRANSFORMER);
LOG.debug("transformer configuration: "+ JSON.toJSONString(transformerList));
/**
* 输入是reader和writer的parameter list,输出是content下面元素的list
*/
List<Configuration> contentConfig = mergeReaderAndWriterTaskConfigs(
readerTaskConfigs, writerTaskConfigs, transformerList);
LOG.debug("contentConfig configuration: "+ JSON.toJSONString(contentConfig));
this.configuration.set(CoreConstant.DATAX_JOB_CONTENT, contentConfig);
return contentConfig.size();
}
此处以Mysql的Split()为例, 为通用关系型数据库的切分方法, 切分通过在querySql划分主键范围中。
@Override
public List<Configuration> split(int adviceNumber) {
return this.commonRdbmsReaderJob.split(this.originalConfig, adviceNumber);
}
split()方法内部会判断是否需要进行单表切分,当满足并发数要求较高,并且配置了splitPk(表分割的主键)参数时,则要求进行单表拆分,拆分个数前面已经经过计算得出,不然就是几张表开启几个并发,下方是单表拆分源码:主要是通过主键,表名,列名,where条件,组合成一句sql后,再通过往sql后加where条件,划分主键范围,再把分割后的sql传给对应配置文件类Configuration并形成列表,作为每个划分出来的任务的配置依据。
总结:
table模式 :当没有配置splitPk时,任务数量与table数量一样.比如table配置了2个(table1,table2) ,则至少开启两个任务,分别负责table1和table2。table模式 :配置splitPk时,配合channel一起使用。任务数 = (向上取整)(channel/table数量) ,最终任务数 = 任务数 * 5 + 1 。配置的splitPk会被整合进入Configuration中的querySql中,例如配置了id,querySql中会加上id>1 and id<5这样的条件,做到分割的效果。querySql模式 :有几条querySql, 生成相同数量的任务配置。Writer与Reader类似,writer只有table模式,单表时,保证任务数目与Reader相同,多表时任务数等于表数,此时不一定与Reader的任务数目相同,因此可能会报错。
- 任务调度方法: schedule()
进入schedule()方法,在执行任务前首先先要获取,task任务的数量(也就是前面切分出来的list的size),接着获取每个taskgroup运行的task数以及需要的taskgroup的数量。
//每个taskgroup运行的task数量 默认并发为5
int channelsPerTaskGroup = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);
//task总数
int taskNumber = this.configuration.getList(
CoreConstant.DATAX_JOB_CONTENT).size();
//taskgroup数量
this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);
接着通过获取配置信息得到每个taskGroup需要运行哪些tasks任务,确定数量之后,采用轮询法分配具体的task到具体的taskGroup,创建任务执行器,并执行任务。
/**
* /**
* 需要实现的效果通过例子来说是:
* <pre>
* a 库上有表:0, 1, 2
* a 库上有表:3, 4
* c 库上有表:5, 6, 7
*
* 如果有 4个 taskGroup
* 则 assign 后的结果为:
* taskGroup-0: 0, 4,
* taskGroup-1: 3, 6,
* taskGroup-2: 5, 2,
* taskGroup-3: 1, 7
*
* </pre>
*/
public static List<Configuration> assignFairly(Configuration configuration, int channelNumber, int channelsPerTaskGroup) {
Validate.isTrue(configuration != null, "框架获得的 Job 不能为 null.");
List<Configuration> contentConfig = configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT);
Validate.isTrue(contentConfig.size() > 0, "框架获得的切分后的 Job 无内容.");
Validate.isTrue(channelNumber > 0 && channelsPerTaskGroup > 0,
"每个channel的平均task数[averTaskPerChannel],channel数目[channelNumber],每个taskGroup的平均channel数[channelsPerTaskGroup]都应该为正数");
// 向上取整 确定taskgroup数量 并发数 / 每个taskgroup的并发数(默认为5)
int taskGroupNumber = (int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup);
Configuration aTaskConfig = contentConfig.get(0);
String readerResourceMark = aTaskConfig.getString(CoreConstant.JOB_READER_PARAMETER + "." +
CommonConstant.LOAD_BALANCE_RESOURCE_MARK);
String writerResourceMark = aTaskConfig.getString(CoreConstant.JOB_WRITER_PARAMETER + "." +
CommonConstant.LOAD_BALANCE_RESOURCE_MARK);
boolean hasLoadBalanceResourceMark = StringUtils.isNotBlank(readerResourceMark) ||
StringUtils.isNotBlank(writerResourceMark);
if (!hasLoadBalanceResourceMark) {
// fake 一个固定的 key 作为资源标识(在 reader 或者 writer 上均可,此处选择在 reader 上进行 fake)
for (Configuration conf : contentConfig) {
conf.set(CoreConstant.JOB_READER_PARAMETER + "." +
CommonConstant.LOAD_BALANCE_RESOURCE_MARK, "aFakeResourceMarkForLoadBalance");
}
// 是为了避免某些插件没有设置 资源标识 而进行了一次随机打乱操作
Collections.shuffle(contentConfig, new Random(System.currentTimeMillis()));
}
LinkedHashMap<String, List<Integer>> resourceMarkAndTaskIdMap = parseAndGetResourceMarkAndTaskIdMap(contentConfig);
// 进行分组
List<Configuration> taskGroupConfig = doAssign(resourceMarkAndTaskIdMap, configuration, taskGroupNumber);
// 调整 每个 taskGroup 对应的 Channel 个数(属于优化范畴)
adjustChannelNumPerTaskGroup(taskGroupConfig, channelNumber);
return taskGroupConfig;
}
接下来配置完一定参数和异常排除检查后,scheduler.schedule()方法会调用父类AbstractScheduler的startAllTaskGroup()方法,启动所有的taskgroup。
public void startAllTaskGroup(List<Configuration> configurations) {
//启动一个线程池,大小为taskGroup的数量
this.taskGroupContainerExecutorService = Executors
.newFixedThreadPool(configurations.size());
for (Configuration taskGroupConfiguration : configurations) {
//建立一个TaskGroupContainerRunner线程,接下来需要看run方法的实现
TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);
//开启线程运行taskgroup
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
}
this.taskGroupContainerExecutorService.shutdown();
}
线程启动后,会启动TaskGroupContainer来运行一个taskgroup里的全部任务。
@Override
public void run() {
try {
//设置线程名字
Thread.currentThread().setName(
String.format("taskGroup-%d", this.taskGroupContainer.getTaskGroupId()));
//启动TaskGroupContainer
this.taskGroupContainer.start();
this.state = State.SUCCEEDED;
} catch (Throwable e) {
this.state = State.FAILED;
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
}
}
step4: 启动TaskGroupContainer容器
接着TaskGroupContainer启动,TaskGroupContainer启动主要执行两个部分:
-
初始化
task执行相关的状态信息,分别是taskId->Cfg的map、待运行的任务队列taskQueue、运行失败任务taskFailedExecutorMap、运行中的任务runTasks、任务开始时间taskStartTimeMap。 -
循环判断各个任务执行的状态。
- 判断是否有失败的
task,如果有则放入taskFailedExecutorMap中,并查看当前的执行是否支持重跑和failOver,如果支持则重新放回执行队列中;如果没有失败,则标记任务执行成功,并从状态轮询map中移除。 - 如果发现有失败的任务,则向容器汇报状态,抛出异常。
- 查看当前执行队列的长度,如果发现执行队列还有通道,则构建
TaskExecutor加入执行队列,并从待运行移除。 - 检查执行队列和所有的任务状态,如果所有的任务都执行成功,则汇报
taskGroup的状态并从循环中退出。 - 检查当前时间是否超过汇报时间,如果超过了,就需要向全局汇报当前状态。
- 所有任务成功之后,向全局汇报当前的任务状态。
// 单个task任务的执行 taskExecutor.doStart(); public void doStart() { this.writerThread.start(); // reader没有起来,writer不可能结束 if (!this.writerThread.isAlive() || this.taskCommunication.getState() == State.FAILED) { throw DataXException.asDataXException( FrameworkErrorCode.RUNTIME_ERROR, this.taskCommunication.getThrowable()); } this.readerThread.start(); // 这里reader可能很快结束 if (!this.readerThread.isAlive() && this.taskCommunication.getState() == State.FAILED) { // 这里有可能出现Reader线上启动即挂情况 对于这类情况 需要立刻抛出异常 throw DataXException.asDataXException( FrameworkErrorCode.RUNTIME_ERROR, this.taskCommunication.getThrowable()); } }这里我们看到实际的
TaskExecutor的执行是通过两个线程writerThread和readerThread来具体执行task任务的。 - 判断是否有失败的
step5: TaskExecutor类
TaskExecutor是TaskGroupContainer的内部类,是一个基本单位task的具体执行管理的地方。
- 初始化一些信息,比如初始化读写线程,实例化存储读数据的管道,获取
transformer的参数等。 - 初始化之后开启读写线程,正式开始单个
task(一部分数据同步任务)正式启动。 - 读操作(
ReaderRunner)利用jdbc,把从数据库中读出来的每条数据封装为一个个Record放入Channel中,当数据读完时,结束的时候会写入一个TerminateRecord标识。 - 写操作(
WriterRunner)不断从Channel中读取Record,直到读到TerminateRecord标识数据以取完,把数据全部读入数据库中。
class TaskExecutor {
private Configuration taskConfig; //当前任务配置项
private Channel channel; //管道 用于缓存读出来的数据
private Thread readerThread; //读线程
private Thread writerThread; //写线程
private ReaderRunner readerRunner;
private WriterRunner writerRunner;
/**
* 该处的taskCommunication在多处用到:
* 1. channel
* 2. readerRunner和writerRunner
* 3. reader和writer的taskPluginCollector
*/
private Communication taskCommunication;
public TaskExecutor(Configuration taskConf, int attemptCount) {
// 获取该taskExecutor的配置
this.taskConfig = taskConf;
//...
/**
* 由taskId得到该taskExecutor的Communication
* 要传给readerRunner和writerRunner,同时要传给channel作统计用
*/
this.taskCommunication = containerCommunicator
.getCommunication(taskId);
//实例化存储读数据的管道
this.channel = ClassUtil.instantiate(channelClazz,
Channel.class, configuration);
this.channel.setCommunication(this.taskCommunication);
/**
* 获取transformer的参数
*/
List<TransformerExecution> transformerInfoExecs = TransformerUtil.buildTransformerInfo(taskConfig);
/**
* 生成writerThread
*/
writerRunner = (WriterRunner) generateRunner(PluginType.WRITER);
this.writerThread = new Thread(writerRunner,
String.format("%d-%d-%d-writer",
jobId, taskGroupId, this.taskId));
//通过设置thread的contextClassLoader,即可实现同步和主程序不通的加载器
this.writerThread.setContextClassLoader(LoadUtil.getJarLoader(
PluginType.WRITER, this.taskConfig.getString(
CoreConstant.JOB_WRITER_NAME)));
/**
* 生成readerThread
*/
readerRunner = (ReaderRunner) generateRunner(PluginType.READER,transformerInfoExecs);
this.readerThread = new Thread(readerRunner,
String.format("%d-%d-%d-reader",
jobId, taskGroupId, this.taskId));
/**
* 通过设置thread的contextClassLoader,即可实现同步和主程序不通的加载器
*/
this.readerThread.setContextClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.taskConfig.getString(
CoreConstant.JOB_READER_NAME)));
}
//省略...
}
可以看到这里readerThread和writerThread都是通过generateRunner的多态方法来转换的.
在generateRunner方法中有下面一段代码
if (transformerInfoExecs != null && transformerInfoExecs.size() > 0) {
recordSender = new BufferedRecordTransformerExchanger(taskGroupId, this.taskId, this.channel,this.taskCommunication ,pluginCollector, transformerInfoExecs);
} else {
recordSender = new BufferedRecordExchanger(this.channel, pluginCollector);
}
这里会判断使用哪种 Exchange. Exchange 可以理解为外部与 channel 交互的中间件.BufferedRecordTransformerExchanger 指的是可以根据特定的格式转换。 BufferedRecordExchanger 仅仅是根据 Datax 的格式进行传输。这里是framework与plugins进行数据传输的位置。
ReaderRunner(WriterRunner类似)
ReaderRunner由Taskecutor的generateRunner进行初始化。
ReaderRunner的主要是从调用对应的plugin的task内部类,调用各个插件各自的init(),prepare()和startRead()、post()方法,开始进行数据库数据的读入。
public void run() {
//省略...
channelWaitWrite.start();
LOG.debug("task reader starts to do init ...");
PerfRecord initPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_INIT);
initPerfRecord.start();
taskReader.init();
initPerfRecord.end();
LOG.debug("task reader starts to do prepare ...");
PerfRecord preparePerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_PREPARE);
preparePerfRecord.start();
taskReader.prepare();
preparePerfRecord.end();
LOG.debug("task reader starts to read ...");
PerfRecord dataPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_DATA);
dataPerfRecord.start();
taskReader.startRead(recordSender);
recordSender.terminate();
dataPerfRecord.addCount(CommunicationTool.getTotalReadRecords(super.getRunnerCommunication()));
dataPerfRecord.addSize(CommunicationTool.getTotalReadBytes(super.getRunnerCommunication()));
dataPerfRecord.end();
LOG.debug("task reader starts to do post ...");
PerfRecord postPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(), PerfRecord.PHASE.READ_TASK_POST);
postPerfRecord.start();
taskReader.post();
postPerfRecord.end();
// automatic flush
// super.markSuccess(); 这里不能标记为成功,成功的标志由 writerRunner 来标志(否则可能导致 reader 先结束,而 writer 还没有结束的严重 bug)
}
//省略...
}
以mysql为例子,mysqlReader会通过jdbc读取数据,并通过senderRecord以Record的形式通过Channel转发给对应的Writer。
public void startRead(Configuration readerSliceConfig, RecordSender recordSender, TaskPluginCollector taskPluginCollector, int fetchSize) {
String querySql = readerSliceConfig.getString("querySql");
String table = readerSliceConfig.getString("table");
PerfTrace.getInstance().addTaskDetails(this.taskId, table + "," + this.basicMsg);
LOG.info("Begin to read record by Sql: [{}\n] {}.", querySql, this.basicMsg);
PerfRecord queryPerfRecord = new PerfRecord(this.taskGroupId, this.taskId, PHASE.SQL_QUERY);
queryPerfRecord.start();
Connection conn = DBUtil.getConnection(this.dataBaseType, this.jdbcUrl, this.username, this.password);
DBUtil.dealWithSessionConfig(conn, readerSliceConfig, this.dataBaseType, this.basicMsg);
int columnNumber = false;
ResultSet rs = null;
try {
rs = DBUtil.query(conn, querySql, fetchSize);
queryPerfRecord.end();
ResultSetMetaData metaData = rs.getMetaData();
int columnNumber = metaData.getColumnCount();
PerfRecord allResultPerfRecord = new PerfRecord(this.taskGroupId, this.taskId, PHASE.RESULT_NEXT_ALL);
allResultPerfRecord.start();
long rsNextUsedTime = 0L;
for(long lastTime = System.nanoTime(); rs.next(); lastTime = System.nanoTime()) {
rsNextUsedTime += System.nanoTime() - lastTime;
//把记录通过recordSender传输给channel
this.transportOneRecord(recordSender, rs, metaData, columnNumber, this.mandatoryEncoding, taskPluginCollector);
}
allResultPerfRecord.end(rsNextUsedTime);
LOG.info("Finished read record by Sql: [{}\n] {}.", querySql, this.basicMsg);
} catch (Exception var20) {
throw RdbmsException.asQueryException(this.dataBaseType, var20, querySql, table, this.username);
} finally {
DBUtil.closeDBResources((Statement)null, conn);
}
}
//把记录通过recordSender传输给channel
this.transportOneRecord(recordSender, rs, metaData, columnNumber, this.mandatoryEncoding, taskPluginCollector);
}
allResultPerfRecord.end(rsNextUsedTime);
LOG.info("Finished read record by Sql: [{}\n] {}.", querySql, this.basicMsg);
} catch (Exception var20) {
throw RdbmsException.asQueryException(this.dataBaseType, var20, querySql, table, this.username);
} finally {
DBUtil.closeDBResources((Statement)null, conn);
}
}

















 3433
3433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









