







经典策略梯度算法
DDPG算法
DDPG 算法被提出的初衷其实是 DQN 算法的一个连续动作空间版本扩展。深度确定性策略梯度算法( deep deterministic policy gradient,DDPG),是一种确定性的策略梯度算法。
由于DQN算法中动作是通过贪心策略或者argmax的方式从Q函数间接得到。要想适配连续动作空间,考虑将选择动作的过程编程一个直接从状态映射到具体动作的函数 μ θ ( s ) \mu_\theta (s) μθ(s),也就是actor网络中求解Q函数以及贪心选择动作这两个过程合并为一个函数。Actor 的任务就是寻找这条曲线的最高点,并返回对应的横坐标,即最大 Q 值对应的动作。
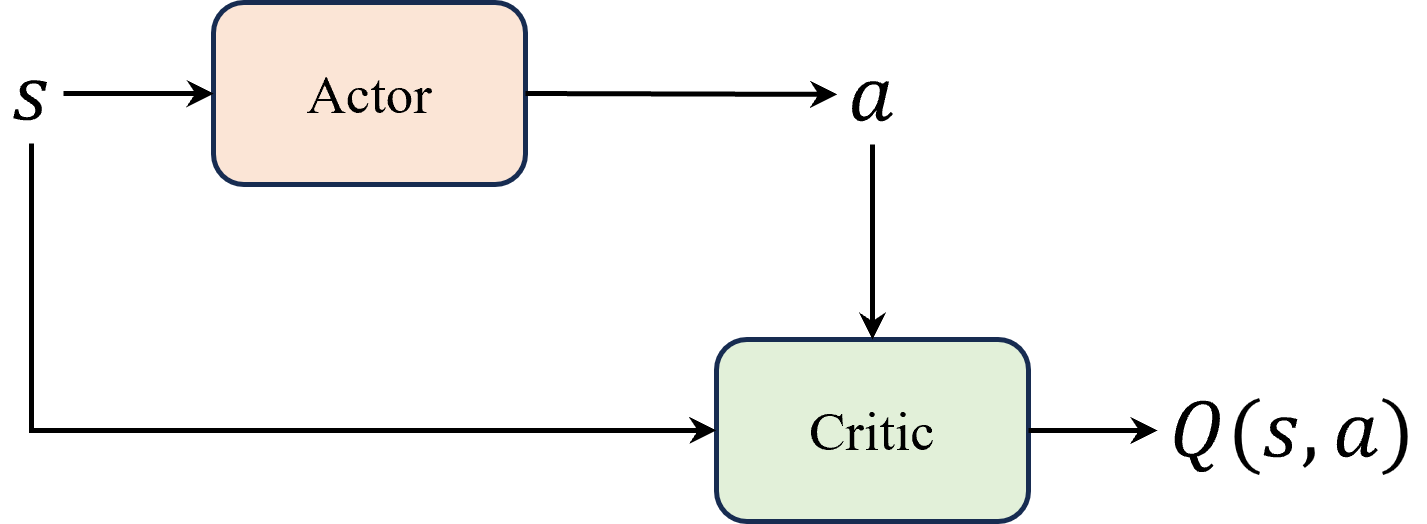
这里相当于是把 DQN 算法中 ε − greedy \varepsilon-\text{greedy} ε−greedy策略函数部分换成了 Actor 。注意 Actor 网络 μ θ ( s ) \mu_\theta (s) μθ(s) 与输出概率分布的随机性策略( stochastic policy )不同,输出的是一个值,因此也叫做确定性策略( deterministic policy )。
在强化学习基础算法的研究改进当中,基本无外乎几个亘古不变的主题:首先是如何提高对值函数的估计,保证其准确性,即尽量无偏且低方差,例如最开始的用深度神经网络替代简单的Q表、结合蒙特卡洛和时序差分的 TD(λ) 、引入目标网络以及广义优势估计等等;其次是如何提高探索以及平衡探索-利用的问题,尤其在探索性比较差的确定性策略中,例如 DQN 和 DDPG 算法都会利用各种技巧来提高探索,例如经验回放、 ε − greedy \varepsilon-\text{greedy} ε−greedy 策略、噪声网络等等。这两个问题是强化学习算法的基础核心问题,希望能够给读者在学习和研究的过程中带来一定的启发。
DDPG算法优缺点:
DDPG 算法的优点主要有:
- 适用于连续动作空间:DDPG 算法采用了确定性策略来选择动作,这使得它能够直接处理连续动作空间的问题。相比于传统的随机策略,确定性策略更容易优化和学习,因为它不需要进行动作采样,缓解了在连续动作空间中的高方差问题。
- 高效的梯度优化:DDPG 算法使用策略梯度方法进行优化,其梯度更新相对高效,并且能够处理高维度的状态空间和动作空间。同时,通过 Actor-Critic 结构,算法可以利用值函数来辅助策略的优化,提高算法的收敛速度和稳定性。
- 经验回放和目标网络:这是老生常谈的内容了,经验回放机制可以减少样本之间的相关性,提高样本的有效利用率,并且增加训练的稳定性。目标网络可以稳定训练过程,避免值函数估计和目标值之间的相关性问题,从而提高算法的稳定性和收敛性。
DDPG缺点:
- 只适用于连续动作空间:这既是优点,也是缺点。
- 高度依赖超参数:DDPG 算法中有许多超参数需要进行调整,除了一些 DQN的算法参数例如学习率、批量大小、目标网络的更新频率等,还需要调整一些 OU 噪声的参数 调整这些超参数并找到最优的取值通常是一个挑战性的任务,可能需要大量的实验和经验。
- 高度敏感的初始条件:DDPG 算法对初始条件非常敏感。初始策略和值函数的参数设置可能会影响算法的收敛性和性能,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









