






datax简介
DataX 是阿里开源的一个离线数据同步工具,目前在阿里巴巴集团内以及国内许多大厂都被广泛使用。DataX 实现了包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
datax设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
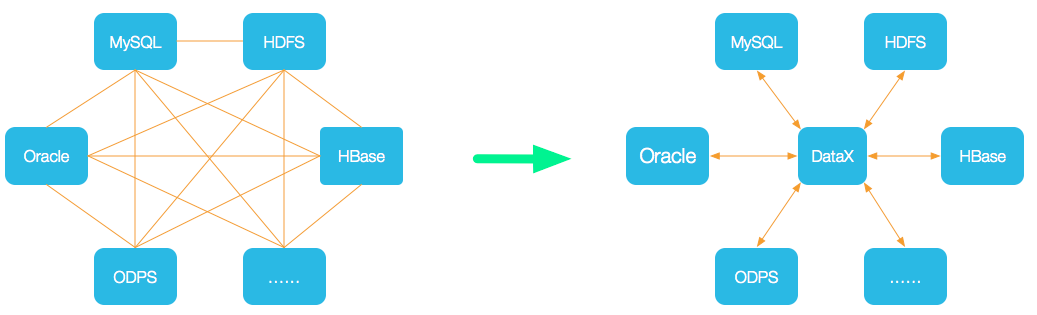
datax架构图

DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
- ReadPlugin:reader插件,负责从源读取数据,并将数据发送给FrameWork
- WriterPlugin:writer插件,负责从FrameWork中读取数据并写入目标源
- FrameWork:FrameWork负责连接Rreader和Writer,并负责处理缓存、并发、速率等核心问题
datax核心架构

以datax的standalone模式为例,启动datax任务进程,首先给任务创建一个job,再通过split方法将job拆分成多个task,然后通过各个taskgroup组来并行运行多个task,直至任务所有task都执行完毕,至此任务结束。
datax源码解读
接下来我们来看下datax代码的一个整体的执行步骤
- 运行入口:通过Engine.main方法启动,
// 解析入参并启动
Engine.entry(args);
- 初始化配置信息:从传入的参数中初始化jobId、mode,并通过ConfigParser.parse(jobPath)方法对主要配置文件进行解析,并装载进Configuration对象,有系统配置文件core.json、用户配置文件job.json、以及对应读写插件的配置文件plugin.json。
Options options = new Options();
options.addOption("job", true, "Job config.");
options.addOption("jobid", true, "Job unique id.");
options.addOption("mode", true, "Job runtime mode.");
BasicParser parser = new BasicParser();
CommandLine cl = parser.parse(options, args);
String jobPath = cl.getOptionValue("job");
// 如果用户没有明确指定jobid, 则 datax.py 会指定 jobid 默认值为-1
String jobIdString = cl.getOptionValue("jobid");
RUNTIME_MODE = cl.getOptionValue("mode");
// 解析系统配置文件core.json、用户配置文件job.json、插件配置文件plugin.json
Configuration configuration = ConfigParser.parse(jobPath);
- 启动实例:入口engine.start
// 启动
Engine engine = new Engine();
engine.start(configuration);
- 创建JobContainer对象,并调用其start方法
AbstractContainer container;
// 创建job实例
container = new JobContainer(allConf);
// 启动实例
container.start();
- job.start方法是整个任务执行的核心,在此方法中定义了整个job执行的一系列步骤,包括:preHandle、init、prepare、split、schedule、post、postHandle。
userConf = configuration.clone();
LOG.debug("jobContainer starts to do preHandle ...");
//
this.preHandle();
LOG.debug("jobContainer starts to do init ...");
//
this.init();
LOG.info("jobContainer starts to do prepare ...");
this.prepare();
LOG.info("jobContainer starts to do split ...");
this.totalStage = this.split();
LOG.info("jobContainer starts to do schedule ...");
this.schedule();
LOG.debug("jobContainer starts to do post ...");
this.post();
//
LOG.debug("jobContainer starts to do postHandle ...");
this.postHandle();
LOG.info("DataX jobId [{}] completed successfully.", this.jobId);
//
this.invokeHooks();
下面我们对这些方法逐个做分析:
- this.preHandle():支持用户自定义preHandle插件,只需要定以一个类继承AbstractJobPlugin类,重写preHandle方法,并定义好对应的配置文件、再将插件类打包到对应目录下,最后在任务的job.json中定义好preHandle插件即可生效,通常这边可以做一些全局化的预处理,也可以不做,放到prepare方法中对读、写分别做预处理
// 实例化handle
AbstractJobPlugin handler = LoadUtil.loadJobPlugin(handlerPluginType, handlerPluginName);
// 执行用户定义的preHandler方法
handler.preHandler(configuration);
- this.init():对读、写插件进行了初始化,并调用插件的init方法,我们可以在插件的init方法中做一些初始化的动作
//必须先Reader ,后Writer
this.jobReader = this.initJobReader(jobPluginCollector);
this.jobWriter = this.initJobWriter(jobPluginCollector);
在initJobReader、initJobWriter中分别调用了reader和writer插件的init方法
// reader的初始化
jobReader.init();
// writer的初始化
jobWriter.init();
- this.prepare():由于init方法中已经对读、写插件进行了初始化,这边就是直接调用插件的prepare方法,这边一般是做读和写的预处理,比如可以在写插件中做一些数据清理,来确保任务的幂等性。
// 源的预处理
this.jobReader.prepare();
// 目标的预处理
this.jobWriter.prepare();
- this.split():此方法中主要是对job进行拆分为task,datax框架提供了一个默认方法,根据配置文件中配置的按字节、按记录计算合适的task个数,并将这个task个数作为一个建议值传入插件的split方法中,我们可以在插件的split方法中用这个建议值进行拆分,也自己定义split的逻辑,按照业务进行更合理的拆分
// 预先先计算一个合适的task个数
this.adjustChannelNumber();
// 对源进行拆分
List<Configuration> readerTaskConfigs = this.doReaderSplit(this.needChannelNumber);
int taskNumber = readerTaskConfigs.size();
// 对目标进行拆分
List<Configuration> writerTaskConfigs = this.doWriterSplit(taskNumber);
在doReaderSplit、doWriterSplit中分别调用了reader和writer插件的split方法
// 调用reader的split方法
List<Configuration> readerSlicesConfigs = this.jobReader.split(adviceNumber);
// 调用writer的split方法
List<Configuration> writerSlicesConfigs = this.jobWriter.split(readerTaskNumber);
拆分完后,在JobContainer.mergeReaderAndWriterTaskConfigs方法中做了两件事:
一、check拆分后的reader个数和writer个数是否相同
二、将一个个reader和writer绑定在一个task中
if (readerTasksConfigs.size() != writerTasksConfigs.size()) {
throw DataXException.asDataXException(
FrameworkErrorCode.PLUGIN_SPLIT_ERROR,
String.format("reader切分的task数目[%d]不等于writer切分的task数目[%d].",
readerTasksConfigs.size(), writerTasksConfigs.size())
);
}
List<Configuration> contentConfigs = new ArrayList<Configuration>();
for (int i = 0; i < readerTasksConfigs.size(); i++) {
Configuration taskConfig = Configuration.newDefault();
taskConfig.set(CoreConstant.JOB_READER_NAME,
this.readerPluginName);
taskConfig.set(CoreConstant.JOB_READER_PARAMETER,
readerTasksConfigs.get(i));
taskConfig.set(CoreConstant.JOB_WRITER_NAME,
this.writerPluginName);
taskConfig.set(CoreConstant.JOB_WRITER_PARAMETER,
writerTasksConfigs.get(i));
if(transformerConfigs!=null && transformerConfigs.size()>0){
taskConfig.set(CoreConstant.JOB_TRANSFORMER, transformerConfigs);
}
taskConfig.set(CoreConstant.TASK_ID, i);
contentConfigs.add(taskConfig);
}
- this.schedule():这个才是真正执行数据交换的方法,首先根据拆分结果和配置信息计算出需要的最小的taskgroup数量,将所有task平均分配到每个taskgroup中,再通过StandAloneScheduler调度器创建大小为taskgroup个数的固定线程池,将每个taskgroup放到线程池的一个线程中执行
public void startAllTaskGroup(List<Configuration> configurations) {
this.taskGroupContainerExecutorService = Executors
.newFixedThreadPool(configurations.size());
for (Configuration taskGroupConfiguration : configurations) {
TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
}
this.taskGroupContainerExecutorService.shutdown();
}
我们对其中一些关键点再进行逐一分析:
- 创建StandAloneScheduler类,在该类的父类ProcessInnerScheduler中创建准备执行taskgroup的线程池
- 创建TaskGroupContainer类,并将Configuration作为构造方法参数传入(Configuration中包含需要执行的部分task的信息),该类同时也是执行task具体逻辑的载体,再将TaskGroupContainer作为构造方法参数传入TaskGroupContainerRunner类并完成执行线程的准备工作
- 在线程中执行方法中调用TaskGroupContainer.start方法执行具体数据交换的逻辑
- TaskExecutor是真正执行task的执行器,TaskGroupContainer.start方法中,为每个task创建TaskExecutor实例,调用doStart开始执行,在doStart中分别创建了读写线程,读写同时进行,具体的数据传输通道是通过读写线程中的BufferedRecordExchanger类完成,他们都持有一个公共的Channel实现类MemoryChannel对象,其底层其实是一个ArrayBlockingQueue,来以此进行读写线程间的数据交换
部分代码细节:
// 创建task执行器,并调用doStart方法执行
TaskExecutor taskExecutor = new TaskExecutor(taskConfigForRun, attemptCount);
taskStartTimeMap.put(taskId, System.currentTimeMillis());
taskExecutor.doStart();
// TaskExecutor构造方法,做一些读写线程的准备工作和初始化
public TaskExecutor(Configuration taskConf, int attemptCount) {
// 获取该taskExecutor的配置
this.taskConfig = taskConf;
Validate.isTrue(null != this.taskConfig.getConfiguration(CoreConstant.JOB_READER)
&& null != this.taskConfig.getConfiguration(CoreConstant.JOB_WRITER),
"[reader|writer]的插件参数不能为空!");
// 得到taskId
this.taskId = this.taskConfig.getInt(CoreConstant.TASK_ID);
this.attemptCount = attemptCount;
/**
* 由taskId得到该taskExecutor的Communication
* 要传给readerRunner和writerRunner,同时要传给channel作统计用
*/
this.taskCommunication = containerCommunicator
.getCommunication(taskId);
Validate.notNull(this.taskCommunication,
String.format("taskId[%d]的Communication没有注册过", taskId));
this.channel = ClassUtil.instantiate(channelClazz,
Channel.class, configuration);
this.channel.setCommunication(this.taskCommunication);
/**
* 获取transformer的参数
*/
List<TransformerExecution> transformerInfoExecs = TransformerUtil.buildTransformerInfo(taskConfig);
/**
* 生成writerThread
*/
writerRunner = (WriterRunner) generateRunner(PluginType.WRITER);
this.writerThread = new Thread(writerRunner,
String.format("%d-%d-%d-writer",
jobId, taskGroupId, this.taskId));
//通过设置thread的contextClassLoader,即可实现同步和主程序不通的加载器
this.writerThread.setContextClassLoader(LoadUtil.getJarLoader(
PluginType.WRITER, this.taskConfig.getString(
CoreConstant.JOB_WRITER_NAME)));
/**
* 生成readerThread
*/
readerRunner = (ReaderRunner) generateRunner(PluginType.READER,transformerInfoExecs);
this.readerThread = new Thread(readerRunner,
String.format("%d-%d-%d-reader",
jobId, taskGroupId, this.taskId));
/**
* 通过设置thread的contextClassLoader,即可实现同步和主程序不通的加载器
*/
this.readerThread.setContextClassLoader(LoadUtil.getJarLoader(
PluginType.READER, this.taskConfig.getString(
CoreConstant.JOB_READER_NAME)));
}
// 启动读写线程,并在对应的读写插件中执行数据的读取和写入
public void doStart() {
this.writerThread.start();
// reader没有起来,writer不可能结束
if (!this.writerThread.isAlive() || this.taskCommunication.getState() == State.FAILED) {
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
}
this.readerThread.start();
// 这里reader可能很快结束
if (!this.readerThread.isAlive() && this.taskCommunication.getState() == State.FAILED) {
// 这里有可能出现Reader线上启动即挂情况 对于这类情况 需要立刻抛出异常
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
}
}
以上就是schedule的一个大致流程,当然中间还有一些流控、实时统计的细节没有讲解,感兴趣的小伙伴可以自己研读源码
- this.post()、this.postHandle()、this.invokeHooks():这些就是做一些清尾的工作了,比如清除一些中间临时表、或者删除一些中间的临时文件等等,这个可根据具体需求和业务定制开发
至此,datax的一个主体流程就介绍完了,文末附上datax的官方地址,有兴趣的小伙伴可以下载源码深入学习!
datax的官方地址:https://github.com/alibaba/DataX

















 3096
3096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









