







深度学习中线性代数回顾
一、范数
在机器学习中,我们使用称为**范数(norm)**的函数来衡量向量的大小。
1. L p L^p Lp 范数
L p L^p Lp 范数定义如下:
∣
∣
x
∣
∣
p
=
(
∑
i
∣
x
i
∣
p
)
1
p
||\mathbf x||_p=(\sum_i |x_i|^p)^{\frac 1p}
∣∣x∣∣p=(i∑∣xi∣p)p1
其中,
p
∈
R
,
p
≥
1
p \in \mathbb R, \quad p \ge 1
p∈R,p≥1
范数(包括
L
p
L^p
Lp 范数)是将向量映射到非负值的函数,向量
x
⃗
\vec x
x 的范数衡量从原点到点
x
⃗
\vec x
x 的距离,有如下性质:
- f ( x ⃗ ) = 0 ⇒ x ⃗ = 0 f(\vec x)=0 \quad \Rightarrow \quad\vec x =0 f(x)=0⇒x=0
- f ( x ⃗ + y ⃗ ) ≤ f ( x ⃗ ) + f ( y ⃗ ) f(\vec x+\vec y) \le f(\vec x)+f(\vec y) f(x+y)≤f(x)+f(y) (triangle inequality)
- ∀ α ∈ R , f ( α x ⃗ ) = ∣ α ∣ f ( x ⃗ ) \forall \alpha \in \mathbb R,\quad f(\alpha\vec x)=|\alpha|f(\vec x) ∀α∈R,f(αx)=∣α∣f(x)
2. L 2 L^2 L2 范数(Euclidean norm)
L 2 L^2 L2 可以简单用 x T x \mathbf x ^T \mathbf x xTx 计算。
3. L 1 L^1 L1 范数
L
2
L^2
L2 范数在原点附近增长十分缓慢,某些机器学习情况下,需要区分恰好是0的元素和非零但值很小的元素非常重要,于是,我们使用在各个位置斜率相同,
并且保持简单数学形式的函数:
L
1
L^1
L1 范数,每当
x
\mathbf x
x 中某个元素从0增加
ϵ
\epsilon
ϵ ,对应的
L
1
L^1
L1 范数也增加
ϵ
\epsilon
ϵ
∣ ∣ x ∣ ∣ 1 = ∑ i ∣ x i ∣ ||\mathbf x||_1=\sum_i |x_i| ∣∣x∣∣1=i∑∣xi∣
4. L ∞ L^\infty L∞ 范数
也被称为最大范数,表示向量中具有最大幅值的元素的绝对值:
∣ ∣ x ∣ ∣ ∞ = max i ∣ x i ∣ ||\mathbf x||_\infty=\max_i |x_i| ∣∣x∣∣∞=imax∣xi∣
5. F r o b e n i u s Frobenius Frobenius 范数
∣
∣
A
∣
∣
F
=
∑
i
,
j
A
i
,
j
2
||\mathbf A||_F=\sqrt {\sum_{i,j}\mathbf A_{i,j}^2}
∣∣A∣∣F=i,j∑Ai,j2
用于衡量矩阵的大小,类似与向量的
L
2
L^2
L2 范数
二、矩阵分解
1.特征分解
关于特征分解的概念、计算以及相关性质不在此赘述,仅作补充
每个实对称矩阵都可以分解成特征向量和实特征值:
A
=
Q
Λ
Q
T
\mathbf A=\mathbf Q \Lambda \mathbf Q^T
A=QΛQT
其中
Q
\mathbf Q
Q 是
A
\mathbf A
A 的特征值组成的正交矩阵,
Λ
\Lambda
Λ 是对角矩阵。特征值
Λ
i
,
j
\Lambda _{i,j}
Λi,j 对应的特征向量是矩阵
Q
\mathbf Q
Q 的第
i
i
i 列,记作
Q
:
,
i
\mathbf Q_{:,i}
Q:,i
特征向量和特征值的作用效果如下图所示
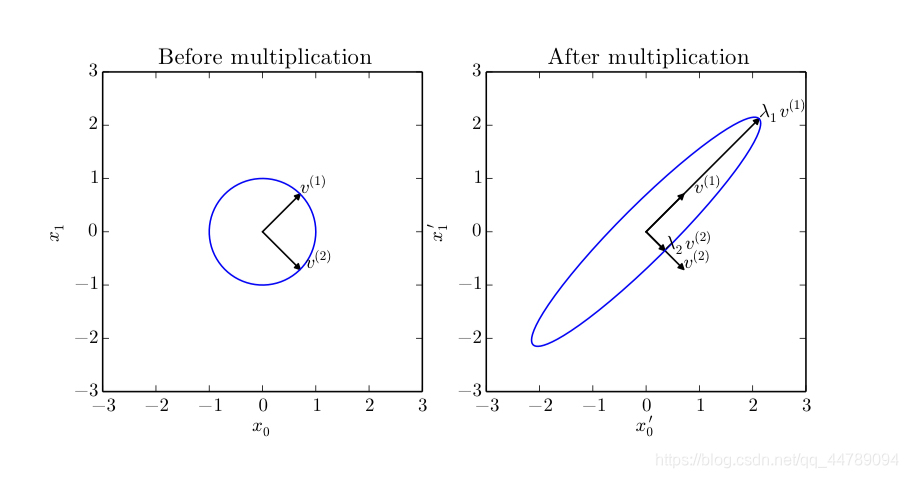
这里矩阵
A
\mathbf A
A 有两个标准正交的特征向量,对应特征值为
λ
1
\lambda _1
λ1 的
ν
(
1
)
\mathbf \nu ^{(1)}
ν(1) 以及对应特征值为
λ
2
\lambda _2
λ2 的
ν
(
2
)
\mathbf \nu ^{(2)}
ν(2)
左侧是所有单位向量
μ
∈
R
2
\mathbf\mu \in \mathbb R^2
μ∈R2 的集合;右侧是所有
A
μ
\mathbf A \mathbf \mu
Aμ 点的集合,通过观察
A
\mathbf A
A 拉伸单位圆的方式,我们看到它将
ν
(
i
)
\mathbf \nu ^{(i)}
ν(i) 方向的空间拉伸了
λ
i
\lambda _i
λi 倍
注:
- 所有特征值都是正数的矩阵称为正定(positive definite)
- 所有特征值都是非负数的矩阵称为半正定(positive semidefinite)
- 所有特征值都是负数的矩阵称为负定(negative definite)
- 所有特征值都是非正数的矩阵称为半负定(negative semidefinite)
2.奇异值分解(SVD)
每个实数矩阵都有一个奇异值分解,但不一定都有特征分解,如非方阵
A
=
U
D
V
T
\mathbf A = \mathbf U \mathbf D \mathbf V^T
A=UDVT
假设
A
\mathbf A
A 是一个
m
×
n
m \times n
m×n 的矩阵,那么
U
\mathbf U
U 是一个
m
×
m
m \times m
m×m 的矩阵,
D
\mathbf D
D 是一个
m
×
n
m \times n
m×n 的矩阵,
V
\mathbf V
V 是一个
n
×
n
n \times n
n×n 的矩阵
- 矩阵 U \mathbf U U 和 V \mathbf V V 都定义为正交矩阵,而矩阵 D \mathbf D D 定义为对角矩阵, D \mathbf D D 不一定为方阵
- 对角矩阵 D \mathbf D D 对角线上的元素称为 A \mathbf A A 的奇异值(singular value),矩阵 U \mathbf U U 的列向量称为左奇异向量(left singular vector),矩阵 V \mathbf V V 的列向量称为右奇异向量(right singular vector)
- 矩阵 A \mathbf A A 的左奇异向量是 A A T \mathbf A\mathbf A^T AAT 的特征向量, A \mathbf A A 的右奇异向量是 A T A \mathbf A^T\mathbf A ATA 的特征向量
- A \mathbf A A 的非零奇异值是 A T A \mathbf A^T\mathbf A ATA 特征值的平方根,同时也是 A A T \mathbf A\mathbf A^T AAT 特征值的平方根
三、Moore-Penrose伪逆
- 用于非方阵求解线性方程问题
Definition Moore-Penrose pseudoinverse,矩阵 A \mathbf A A 的伪逆定义如下:
A
+
=
lim
α
↘
0
(
A
T
A
+
α
I
)
−
1
A
T
\mathbf A^+= \lim_{\alpha \searrow 0}(\mathbf A^T\mathbf A+\alpha \mathbf I)^{-1} \mathbf A^T
A+=α↘0lim(ATA+αI)−1AT
计算时,使用
A
+
=
V
D
+
U
T
\mathbf A^+=\mathbf V \mathbf D^+ \mathbf U^T
A+=VD+UT ,其中
U
\mathbf U
U 、
D
\mathbf D
D 和
V
\mathbf V
V 是矩阵
A
\mathbf A
A 奇异值分解后得到的矩阵。对角矩阵
D
\mathbf D
D 的伪逆
D
+
\mathbf D^+
D+ 是其非零元素取倒数之后再转置得到的。
- 对与线性方程
A
x
=
y
⟹
x
=
B
y
\mathbf A \mathbf x=\mathbf y\quad \Longrightarrow \quad \mathbf x=\mathbf B\mathbf y
Ax=y⟹x=By
- 当矩阵 A \mathbf A A 的列数多于行数时,使用伪逆求解线性方程时众多可能解法中的一种。特别地 x = A + y \mathbf x=\mathbf A^+\mathbf y x=A+y 是方程所有可行解中Euclidean norm ∣ ∣ x ∣ ∣ 2 ||\mathbf x||_2 ∣∣x∣∣2 最小的一个
- 当矩阵 A \mathbf A A 的列数少于行数时,可能没有解,通过伪逆得到的 x \mathbf x x 使得 A x \mathbf A \mathbf x Ax 和 y \mathbf y y 的Euclidean距离 ∣ ∣ A x − y ∣ ∣ 2 ||\mathbf A \mathbf x-\mathbf y||_2 ∣∣Ax−y∣∣2 最小
四、迹运算
- 迹运算返回的是矩阵对角元素的和:
T
r
(
A
)
=
∑
i
A
i
,
j
Tr(\mathbf A)=\sum_i \mathbf A_{i,j}
Tr(A)=i∑Ai,j
2. 迹运算描述矩阵
F
r
o
b
e
n
i
u
s
Frobenius
Frobenius 范数:
∣
∣
A
∣
∣
F
=
T
r
(
A
A
T
)
||\mathbf A||_F=\sqrt{Tr(\mathbf A\mathbf A^T)}
∣∣A∣∣F=Tr(AAT)
3.
T
r
(
A
B
C
)
=
T
r
(
C
A
B
)
=
T
r
(
B
C
A
)
Tr(\mathbf A\mathbf B \mathbf C)=Tr(\mathbf C\mathbf A\mathbf B)=Tr(\mathbf B \mathbf C \mathbf A)
Tr(ABC)=Tr(CAB)=Tr(BCA)
更一般地:
T
r
(
∏
i
=
1
n
F
(
i
)
)
=
T
r
(
F
(
n
)
∏
i
=
1
n
−
1
F
(
i
)
)
Tr(\prod_{i=1}^n \mathbf F^{(i)})=Tr(\mathbf F^{(n)} \prod_{i=1}^{n-1}\mathbf F^{(i)})
Tr(i=1∏nF(i))=Tr(F(n)i=1∏n−1F(i))
4. 即使循环转置后矩阵乘积得到的矩阵形状变了,迹运算地结果不变,假设矩阵
A
∈
R
m
×
n
\mathbf A \in \mathbb R^{m \times n}
A∈Rm×n ,矩阵
B
∈
R
n
×
m
\mathbf B \in \mathbb R^{n \times m}
B∈Rn×m
T
r
(
A
B
)
=
T
r
(
B
A
)
Tr(\mathbf A\mathbf B)=Tr(\mathbf B \mathbf A)
Tr(AB)=Tr(BA)
尽管
A
B
∈
R
m
×
m
\mathbf A\mathbf B \in \mathbb R^{m \times m}
AB∈Rm×m 和
B
A
∈
R
n
×
n
\mathbf B \mathbf A \in \mathbb R^{n \times n}
BA∈Rn×n
五、矩阵求导
1.行向量对元素求导
设 y T = [ y 1 , . . . , y n ] y^T = [y_1,...,y_n] yT=[y1,...,yn]是 n n n维行向量, x x x是元素,则 ∂ y T ∂ x = [ ∂ y 1 ∂ x , . . . , ∂ y n ∂ x ] \frac{\partial y^T}{\partial x}=[\frac{\partial y_1}{\partial x},...,\frac{\partial y_n}{\partial x}] ∂x∂yT=[∂x∂y1,...,∂x∂yn]
2.列向量对元素求导
设 y = [ y 1 ⋮ y m ] y=\left[ \begin{matrix}y_1\\ \vdots \\ y_m\end{matrix}\right] y=⎣⎢⎡y1⋮ym⎦⎥⎤是 m m m维列向量, x x x是元素,则 ∂ y ∂ x = [ ∂ y 1 ∂ x ⋮ ∂ y m ∂ x ] \frac{\partial y}{\partial x}=\left[\begin{matrix}\frac{\partial y_1}{\partial x}\\ \vdots \\ \frac{\partial y_m}{\partial x}\end{matrix}\right] ∂x∂y=⎣⎢⎡∂x∂y1⋮∂x∂ym⎦⎥⎤
3.矩阵对元素求导
设 Y = [ y 11 ⋯ y 1 n ⋮ ⋱ ⋮ y m 1 ⋯ y m n ] Y=\left [\begin{matrix}y_{11} & \cdots & y_{1n}\\ \vdots & \ddots & \vdots \\y_{m1} & \cdots & y_{mn}\end{matrix}\right] Y=⎣⎢⎡y11⋮ym1⋯⋱⋯y1n⋮ymn⎦⎥⎤是 m × n m \times n m×n矩阵, x x x是元素,则
∂ Y ∂ x = [ ∂ y 11 ∂ x ⋯ ∂ y 1 n ∂ x ⋮ ⋱ ⋮ ∂ y m 1 ∂ x ⋯ ∂ y m n ∂ x ] \frac{\partial Y}{\partial x}=\left [ \begin{matrix} \frac{\partial y_{11}}{\partial x} & \cdots & \frac{\partial y_{1n}}{\partial x}\\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m1}}{\partial x} & \cdots & \frac{\partial y_{mn}}{\partial x} \end{matrix} \right] ∂x∂Y=⎣⎢⎡∂x∂y11⋮∂x∂ym1⋯⋱⋯∂x∂y1n⋮∂x∂ymn⎦⎥⎤
4.元素对行向量求导
设 y y y是元素, X T = [ x 1 , . . . , x q ] X^T = [x_1,...,x_q] XT=[x1,...,xq]是 q q q维行向量,则 ∂ y ∂ X T = [ ∂ y ∂ x 1 , . . . , ∂ y ∂ x q ] \frac{\partial y}{\partial X^T}=[\frac{\partial y}{\partial x_1},...,\frac{\partial y}{\partial x_q}] ∂XT∂y=[∂x1∂y,...,∂xq∂y]
5.元素对列向量求导
设 y y y是元素, X = [ x 1 ⋮ x p ] X=\left[\begin{matrix}x_1\\ \vdots \\ x_p\end{matrix}\right] X=⎣⎢⎡x1⋮xp⎦⎥⎤是 p p p维列向量,则 ∂ y ∂ X = [ ∂ y ∂ x 1 ⋮ ∂ y ∂ x p ] \frac{\partial y}{\partial X}=\left[\begin{matrix}\frac{\partial y}{\partial x_1}\\ \vdots \\ \frac{\partial y}{\partial x_p}\end{matrix}\right] ∂X∂y=⎣⎢⎢⎡∂x1∂y⋮∂xp∂y⎦⎥⎥⎤
6.元素对矩阵求导
设 y y y是元素, X = [ x 11 ⋯ x 1 q ⋮ ⋱ ⋮ x p 1 ⋯ x p q ] X=\left [\begin{matrix}x_{11} & \cdots & x_{1q}\\\vdots & \ddots & \vdots \\x_{p1} & \cdots & x_{pq}\end{matrix}\right] X=⎣⎢⎡x11⋮xp1⋯⋱⋯x1q⋮xpq⎦⎥⎤是 p × q p \times q p×q矩阵,则
∂ y ∂ X = [ ∂ y ∂ x 11 ⋯ ∂ y ∂ x 1 q ⋮ ⋱ ⋮ ∂ y ∂ x p 1 ⋯ ∂ y ∂ x p q ] \frac{\partial y}{\partial X}=\left [ \begin{matrix} \frac{\partial y}{\partial x_{11}} & \cdots & \frac{\partial y}{\partial x_{1q}}\\ \vdots & \ddots & \vdots \\ \frac{\partial y}{\partial x_{p1}} & \cdots & \frac{\partial y}{\partial x_{pq}} \end{matrix} \right] ∂X∂y=⎣⎢⎢⎡∂x11∂y⋮∂xp1∂y⋯⋱⋯∂x1q∂y⋮∂xpq∂y⎦⎥⎥⎤
7.行向量对列向量求导
设 y T = [ y 1 , . . . , y n ] y^T = [y_1,...,y_n] yT=[y1,...,yn]是n维行向量, X = [ x 1 ⋮ x p ] X=\left[\begin{matrix}x_1\\ \vdots \\ x_p\end{matrix}\right] X=⎣⎢⎡x1⋮xp⎦⎥⎤ 是 p p p维列向量,则
∂ y T ∂ X = [ ∂ y 1 ∂ x 1 ⋯ ∂ y n ∂ x 1 ⋮ ⋱ ⋮ ∂ y 1 ∂ x p ⋯ ∂ y n ∂ x p ] \frac{\partial y^T}{\partial X}=\left [ \begin{matrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_n}{\partial x_1}\\ \vdots & \ddots & \vdots \\ \frac{\partial y_1}{\partial x_p} & \cdots & \frac{\partial y_n}{\partial x_p} \end{matrix} \right] ∂X∂yT=⎣⎢⎢⎡∂x1∂y1⋮∂xp∂y1⋯⋱⋯∂x1∂yn⋮∂xp∂yn⎦⎥⎥⎤
8.列向量对行向量求导
设 y = [ y 1 ⋮ y m ] y=\left[\begin{matrix}y_1\\ \vdots \\ y_m\end{matrix}\right] y=⎣⎢⎡y1⋮ym⎦⎥⎤是 m m m维列向量, X T = [ x 1 , . . . , x q ] X^T = [x_1,...,x_q] XT=[x1,...,xq]是 q q q维行向量,则
∂ y ∂ X T = [ ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x q ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x q ] \frac{\partial y}{\partial X^T}=\left [ \begin{matrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_1}{\partial x_q}\\ \vdots & \ddots & \vdots \\ \frac{\partial y_m}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_q} \end{matrix} \right] ∂XT∂y=⎣⎢⎢⎡∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xq∂y1⋮∂xq∂ym⎦⎥⎥⎤
注:参考《Deep Learning》,lan Goodfellow, Yoshua Bengio, Aaron Courville

















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









