






1、代码复盘
1、满二叉搜索树查找
给定2^n-1个不同的整数(1<=n<=10,n为整数),构建一棵平衡满二叉搜索树
二叉搜索树定义如下: 1)节点的左子树只包含小于当前节点的数。
2)节点的右子树只包含大于当前节点的数。
3)所有左子树和右子树自身必须也是二叉搜索树。例7个数字1234567构建的满二叉搜索树如下所示
4 2 6 1 3 5 7
再给一个待查找数,计算查找路径和结果。
输入
输入分2行, 第一行为2^n-1个未排序的整数,空格分隔,用于构建二叉搜索树,其中1<=n<=10
第二行为待查找的整数。
所有输入整数的取值范围为[-32768,32767]。
输出
搜索的路径和结果 路径从根节点开始,用S表示,查找左树用L表示,查找右树使用R表示,找到后使用Y表示,最终未找到使用N表示。
样例1
输入:
2 1 3 7 5 6 4 6
输出:
SRY
解释:从根节点开始,所以路径的第一部分为S,待查找数为6,大于4,所以要查找右树,路径增加R,正好找到。所以最后增加Y,最终输出SRY
样例2
输入:
4 2 1 3 6 5 7 5
输出:
SRLY
解释:从根节点开始,一次往右树,往左树查找,找到结果5,因此最终SRLY
样例3
输入:
1 2 3 4 5 6 7 8
输出:
SRRN
解释:从根节点开始查找,标记s,待查找数8比4大,所以查找右树,标记R, 8比6还大,继续查找右树标记R,8比右树节点7还大,但已经到了叶子,没有找到,因此最终标记SRRN
方法1:
#include <bits/stdc++.h>
using namespace std;
struct TreeNode{
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x): val(x),left(nullptr),right(nullptr){}
};
string res = "S";
TreeNode* help(vector<int>& num,int left,int right){
if(left>right){
return nullptr;
}
int mid = left+(right-left)/2;
TreeNode* root = new TreeNode(num[mid]);
root->left = help(num,left,mid-1);
root->right = help(num,mid+1,right);
return root;
}
void traver(TreeNode* root,int tar){
if(root ==nullptr) {
res = res+"N";
return;
}
if(root->val ==tar) {
res = res+"Y";
return;
}
if(root->val>tar){
if(root->left==nullptr){
res = res+"N";
return;
}else{
res = res+"L";
traver(root->left,tar);
}
}
if(root->val<tar){
if(root->right==nullptr){
res = res+"N";
return;
}else{
res = res+"R";
traver(root->right,tar);
}
}
}
int main() {
int a;
vector<int> in;
string s1;
getline(cin,s1);
stringstream ss1(s1);
while(ss1>>a){
in.push_back(a);
}
int target ;
cin>>target;
sort(in.begin(),in.end());
traver( help(in,0,in.size()-1),target);
cout<<res<<endl;
}
总体的算法复杂度:
时间复杂度:nlogn:排序的:两个函数的最坏的情况都是n
空间复杂度:n
分成两部分:
第一部分根据顺序数组建立搜索二叉树:
首先是排序:
sort(in.begin(),in.end()); 时间复杂度:n*lg(n) 实现原理:sort并不是简单的快速排序,它对普通的快速排序进行了优化,此外,它还结合了插入排序和推排序。系统会根据你的数据形式和数据量自动选择合适的排序方法,这并不是说它每次排序只选择一种方法,它是在一次完整排序中不同的情况选用不同方法,比如给一个数据量较大的数组排序,开始采用快速排序,分段递归,分段之后每一段的数据量达到一个较小值后它就不继续往下递归,而是选择插入排序,如果递归的太深,他会选择推排序。
根据排序数组建搜索二叉树
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
return helper(nums, 0, nums.size() - 1);
}
TreeNode* helper(vector<int>& nums, int left, int right) {
if (left > right) {
return nullptr;
}
// 总是选择中间位置右边的数字作为根节点
int mid = (left + right + 1) / 2;
TreeNode* root = new TreeNode(nums[mid]);
root->left = helper(nums, left, mid - 1);
root->right = helper(nums, mid + 1, right);
return root;
}
};
时间复杂度:O(n),其中 n 是数组的长度。每个数字只访问一次。
空间复杂度:O(logn),其中 n 是数组的长度。空间复杂度不考虑返回值,因此空间复杂度主要取决于递归栈的深度,递归栈的深度是 O(logn)。
作者:力扣官方题解
链接:https://leetcode.cn/problems/convert-sorted-array-to-binary-search-tree/solutions/312607/jiang-you-xu-shu-zu-zhuan-huan-wei-er-cha-sou-s-33/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
五、二叉查找树的时间复杂度分析
(一)、最差时间复杂度
在极端情况下,根节点的左右子树极度不平衡,已经退化成了链表,所以查找的时间复杂度就变成了 O(n)。

(二)、完全二叉搜索树时间复杂度分析
从我前面的例子、图,以及还有代码来看,不管操作是插入、删除还是查找,时间复杂度其实都跟树的高度成正比,也就是 O(height)。既然这样,现在问题就转变成另外一个了,也就是,如何求一棵包含 n 个节点的完全二叉树的高度?
树的高度就等于最大层数减一,为了方便计算,我们转换成层来表示。从图中可以看出,包含 n 个节点的完全二叉树中,第一层包含 1 个节点,第二层包含 2 个节点,第三层包含 4 个节点,依次类推,下面一层节点个数是上一层的 2 倍,第 K 层包含的节点个数就是 2^(K-1)。

不过,对于完全二叉树来说,最后一层的节点个数有点儿不遵守上面的规律了。它包含的节点个数在 1 个到 2^(L-1) 个之间(我们假设最大层数是 L)。如果我们把每一层的节点个数加起来就是总的节点个数 n。也就是说,如果节点的个数是 n,那么 n 满足这样一个关系:
n >= 1+2+4+8+...+2^(L-2)+1 n <= 1+2+4+8+...+2^(L-2)+2^(L-1)
借助等比数列的求和公式,我们可以计算出,L 的范围是[log2(n+1), log2n +1]。完全二叉树的层数小于等于 log2n +1,也就是说,完全二叉树的高度小于等于 log2n。
深度遍历的空间复杂度取决于树的高度,树的高度是h,栈的深度就是h乘以一个常数。最坏情况当然是O(n)的,但在随机情况下是不会发生的,只有在元素出现次序本身具有某些规律的情况才会发生。你的代码可能是这样的: 在有尾递归优化的情况下,最后一条语句不用压栈,不占用栈空间,因此空间复杂度为S(n)=S(left)+1 在平衡的时候,left=n/2,S(n)=S(n/2)+1,得S(n)=O(logn) 在树严重向左偏,left=n-1,S(n)=S(n-1)+1,得S(n)=O(n) 当树严重向右偏,left=1,S(n)=S(1)+1,得S(n)=O(1)
第二步搜索二叉树中寻找某个数并且标记路径
void traver(TreeNode* root,int tar){
if(root ==nullptr) {
res = res+"N";
return;
}
if(root->val ==tar) {
res = res+"Y";
return;
}
if(root->val>tar){
if(root->left==nullptr){
res = res+"N";
return;
}else{
res = res+"L";
traver(root->left,tar);
}
}
if(root->val<tar){
if(root->right==nullptr){
res = res+"N";
return;
}else{
res = res+"R";
traver(root->right,tar);
}
}
}
时间复杂度:O(N),其中 N 是二叉搜索树的节点数。最坏情况下二叉搜索树是一条链,且要找的元素比链末尾的元素值还要小(大),这种情况下我们需要递归 N 次。
空间复杂度:O(N)。最坏情况下递归需要 O(N) 的栈空间。
方法二:直接使用二分法
2、第二题 足球队员射门能力排序
球队有n个足球队员参与m次射门训练,每次射门进球用1表示,射失则用0表示,依据如下规则对该n个队员的射门能力做排序
1、进球总数更多的队员射门能力更强
2、若进球总数—样多,则比较最多—次连续进球的个数,最多的队员能力更强
3、若最多一次连续进球的个数一样多,则比较第一次射失的先后顺序,其中后射失的队员更强,若第一次射失顺序相同,则按继续比较第二次射失的顺序,后丢球的队员能术更强,依次类推
4、若前3个规则排序后还能力相等,则队员编号更小的能力更强
输入
第1行,足球队员数n,射门训练次数m。(队员编号从1开始,依次递增) 第2行,第1~n个队员从第1到m次训练的进球情况,每个队员进球情况为连续的1和0的组合,不同队员用空格分隔n和m均为正整数,0<n<=10 ^ 3,0<m<=10^3
输出
射门能力从强到弱的队员编号,用空格分隔
样例1
输入:
4 5 11100 00111 10111 01111
输出:
4 3 1 2
解释:4个队员,射门训练5次,队员3和4进球数均为4个,比队员1和2的3个更多,队员3连续进球数最多一次为3个,而队员4最大为4,因此队员4射门能力强于队员3,另外队员2比队员1先丢球,因此队员1射门能力强于队员2,排序为4312
样例2
输入:
2 10 1011100111 1011101101
输出:
2 1
解释:2个队员,射门训练10次,两个队员的进球总数均为7个,连续进球最多的均为3个,且第前两次丢球顺序均为第二次和第6次训练射门,而队员2第三次丢球为第9次训练,队员2为第7次训练,因此队员2的射门能力强于队员1,排序为21
#include <bits/stdc++.h>
using namespace std;
/*
4 5
11100 00111 10111 01111
*/
int number(string& s){
int res = 0;
if(s.size()==0) return res;
for(auto& a:s){
if(a == '1'){
res++;
}
}
return res;
}
// 这里两个变量:pre表示前面所有连续1的最大值
// res表示当前连续1的个数:
// 遇到1则res++
// 遇到0则更新前面所有连续1的最大值,并且将当前连续1的个数置0
// 返回当前1个数和之前连续1最大值的大值
int tar(string s){
int res = 0;
int pre = 0;
for(auto a:s){
if(a=='1'){
res++;
}
else if(a=='0'){
if(res>pre){
pre = res;
}
res = 0;
}
}
return max(res,pre);
}
// 比较第一次0:如果第一次0相同那就比较第二次0:
// 那就是两个都是1或者都是1我不管,只要找到第一次不相同的,谁先出现0谁排后面
bool tar3(string& s1 ,string& s2){
for(int i = 0;i<s1.size();i++){
if(s1[i]=='0'&&s2[i]=='1'){
return false;
}
if(s1[i]=='1'&&s2[i]=='0'){
return true;
}
}
return false;
}
int main() {
int n,m;
cin>>n>>m;
string x;
// 因为要返回的是下标:所以建立一个pair对,第一个参数放string,第二个放下标
// 并且是从小到大去放下标:这个时候第四个条件4、若前3个规则排序后还能力相等,则队员编号更小的能力更强
// 我在sort中就不需要再写了:没有这个判断条件,那么就保持不变:小下标的在前面
vector<pair<string,int>> in;
int index = 0;
while(n--){
cin>>x;
in.push_back({x,index});
index++;
}
sort(in.begin(),in.end(),[](pair<string,int>a,pair<string,int>b){
string s1 = a.first;
string s2 = b.first;
if(number(s1)>number(s2) ) return true;
else if(number(s1)<number(s2) ) return false;
else {
if(tar(s1)>tar(s2)) return true;
else if(tar(s1)<tar(s2)) return false;
else {
return tar3(s1,s2);
}
}
});
for(int i = 0;i<in.size()-1;i++){
cout<< in[i].second+1 << " ";
}
cout << in.back().second+1;
}
3、第三题 找到内聚值最大的微服务群组
开发团队为了调研微服务调用情况,对n个微服务调用数据进行了采集分析,微服务使用数字0至n-1进行编号,给你一个下标从0开始的数组edges , 其中edges[i]表示存在一条从微服务i到微服务edges[i]的接口调用。
我们将形成1个环的多个微服务称为微服务群组,一个微服务群组的所有微服务数量为L,能够访问到该微服务群组的微服务数量为V,这个微服务群组的内聚值H=L-V.
已知提供的数据中有1个或多个微服务群组,请按照内聚值H的结果从大到小的顺序对所有微服务群组((H相等时,取环中最大的数进行比较)排序,输出排在第一的做服务群组,输出时每个微服务群组输出的起始编号为环中最小的数。
输入
入参分为两行输入: 第一行为n,表示有n个微服务 第二行为数组edges,其中edges[i]表示存在一条从微服务i到微服务edges[i]的接口调用,数字以空格分隔
输入范围说明: n== edges.length 2<= n <=10^5 0 <= edges[i] <= n-1
edges[i] !=i
输出
输出排在第一的微服务群组的编号数组,按照环的访问顺序输出,起始编号为环中最小的数,数字以空格分隔
样例1
输入:
4 3 3 0 1
输出:
0 3 2
解释:
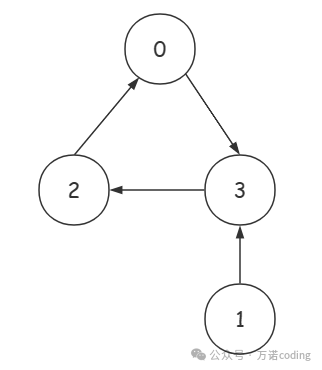
0,3,2组成了微服务群组 (环)a,他的L值为3,对于a来说,只有编号为1的1个微服务可以访问到a,因此a的为1答案输出微服务群组为0 3 2
样例2
输入:
12 2 6 10 1 6 0 3 0 5 4 5 8
输出:
0 2 10 5
解释:
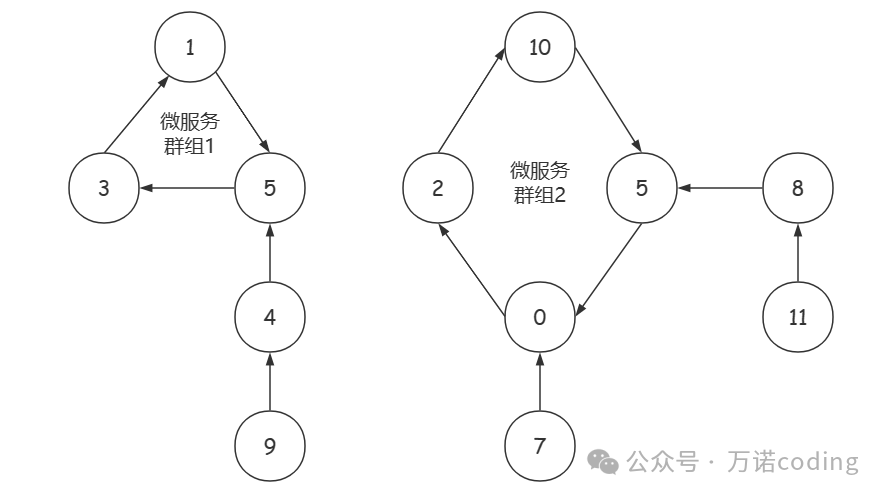
-
1,6,3组成了微服务群组(环) a1,L1值为3,编号为4、9的2个微服务可以访问到a1,因此√1值为2,H1为L1V1 =1;
-
0,2,10,5组成了微服务群组 (环) a2,L2值为4,编号为7、8、11的3个微服务可以访问到2,因此v2值为3,H2为L2-V2=1;
-
先对比H值,H1=H2,H值相等;
-
再对比环中序号最大值,a1中最大数为6.a2中最大数为10,a2排前面,因此输出答案为:0 2 10 5
思路与代码
本题的关键是要找到环,然后对环的内聚值进行排序。至于如何找到环,可以用拓扑排序,由于每个节点只有一个出边,所以找环非常简单(重复遍历即可,不需要复杂的dfs或bfs)。由于需要计算内聚值,其中的“能够访问到该微服务群组的微服务数量为V”,也就是连接到该环的节点数,可以在拓扑排序的时候进行累加,最终赋值给环中的各个节点。
排序的时候,按照内聚值和环的最大节点排序;输出的时候,从环的最小节点开始输出。
#include <sstream>
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <queue>
using namespace std;
int n;
int main()
{
cin >> n;
vector<int> edges(n);
vector<int> in(n, 0);
// 每个节点的子节点数目
vector<int> nums(n, 0);
for (int i = 0; i < n; ++i) {
cin >> edges[i];
in[edges[i]]++;
}
queue<int> q;
for (int i = 0; i < n; ++i) {
if (in[i] == 0) q.push(i);
}
while (!q.empty()) {
int sz = q.size();
while (sz--) {
int f = q.front(); q.pop();
in[edges[f]]--;
nums[edges[f]] += nums[f] + 1;
if (in[edges[f]] == 0) {
q.push(edges[f]);
}
}
}
vector<vector<int>> cir;
vector<int> value;
vector<int> mx;
for (int i = 0; i < n; ++i)
if (in[i] == 0) continue;
int c = i, v = 0, mx_no = i;
vector<int> path;
while (in[c]) {
v += nums[c];
path.push_back(c); in[c] = 0;
c = edges[c];
mx_no = max(mx_no, c);
}
cir.push_back(path);
mx.push_back(mx_no);
value.push_back(path.size() - v);
}
vector<int> idx(value.size());
for (int i = 0; i < value.size(); ++i) idx[i] = i;
sort(idx.begin(), idx.end(), [&](auto& a, auto& b) {
return value[a] == value[b] ? mx[a] > mx[b] : value[a] > value[b];
});
auto& path = cir[idx[0]];
int start = *min_element(path.begin(), path.end());
for (int i = 0; i < path.size(); ++i) {
cout << start;
start = edges[start];
if (i != path.size() - 1) cout << " ";
}
return 0;
}

















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









