







之前一直在看这篇小目标检测的论文,在看的过程中遇到了很多问题。在csdn上没有查到太多有关于这篇文章的讲解。因此我就把我读文献过程中遇到的知识点,学到的心得和感悟分享一下,如果再有读这篇文章的小伙伴可以借鉴一下。
引言
本文的核心主要有三点:
接下来我会在方法阶段逐一对这几个部分进行说明。
方法
整体的网络架构
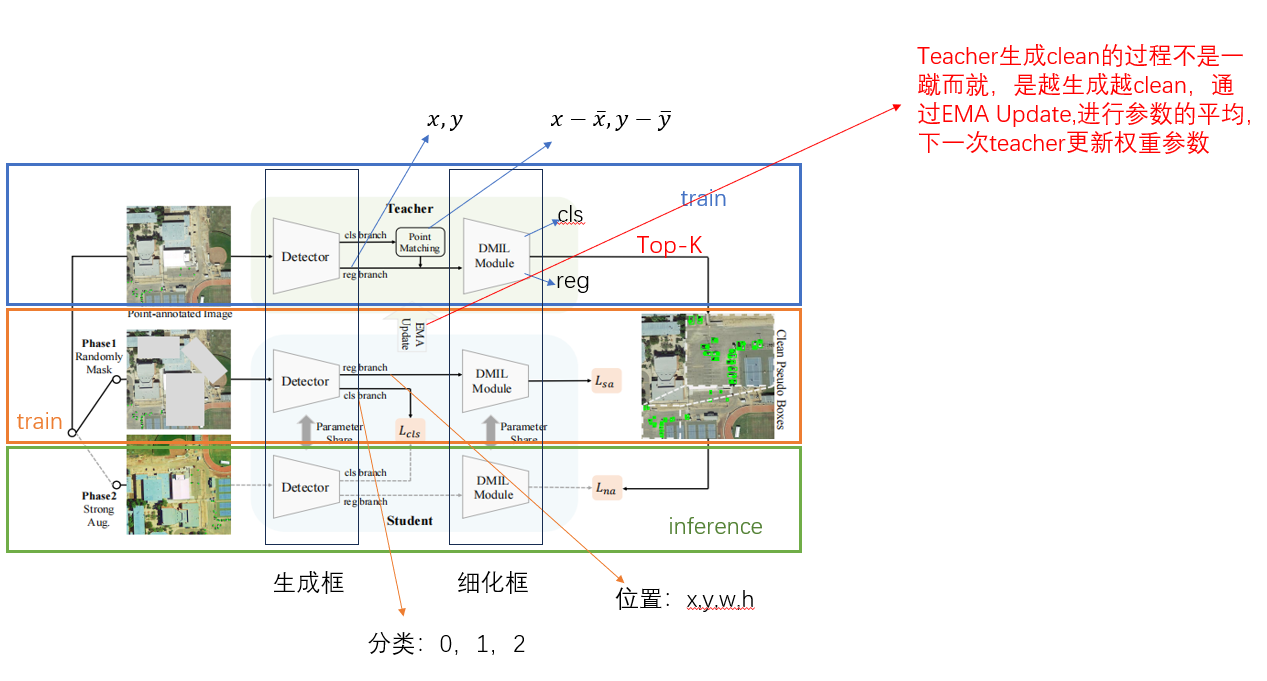
这是我在原论文图片上加注的说明。
教师网络训练原始输入图像,并且生成相对精确的伪标签,从点到框,并对学生网络进行监督
与此同时,学生网络的上面的分支也在同时进行学习,对有掩码的输入图像进行训练—检测器—DMIL
学生网络的下面的分支进行推理,对有原始输入图像进行训练—检测器—DMIL,最后对生成的框与教师端生成的为标签进行损失,并且反向优化迭代 。
总体来说,这张图片可以看作是三个部分:教师网路,学生网络可以分解成为两个部分,一个部分是train,一个部分是inference。教师网络的train和学生网络的train是同时进行的,教师网络通过训练生成一个相对来说较为精确的伪框,这个伪框作为学生训练的监督信号。与此同时,学生端的训练又会通过参数更新反向影响教师端生成的伪框。教师端不是一下子生成出‘clean’的伪框,而是生成的伪框越来越'clean'。
而我们最后要打到的目标是最下面的inference,即从一个粗略的输入图像,直接预测出精确的伪框。
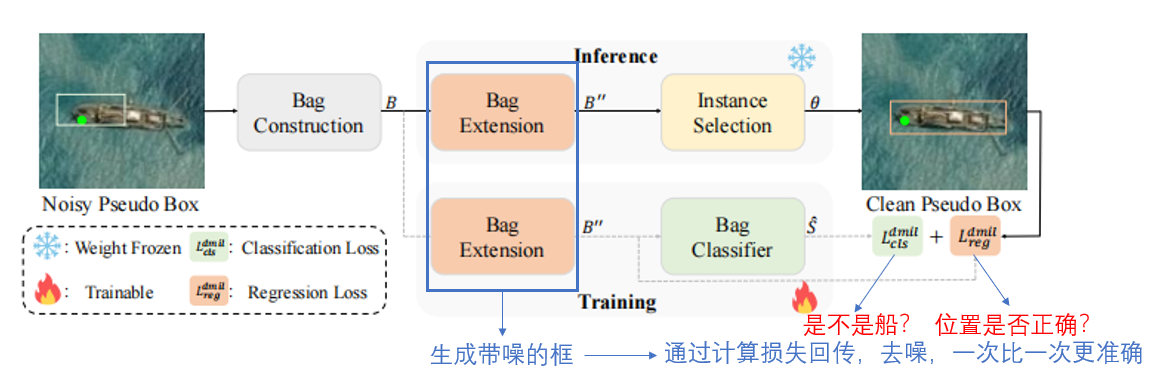
推理部分是直接对扩展后的框进行实例选择,选择准确的实例,作为“标准答案”。而训练部分对扩展出的框进行分类和回归,即将预测出来的框和“标准答案”进行回归,计算损失,进行梯度回传,优化网络。
空间感知框的生成(Spatial-aware Box Generation)
空间感知框的生成是图像中的这一部分:

由图可以看出,空间感知框的生成是有如下流程:先是对初始图像进行掩码遮盖,防止模型对某些部分过拟合。接下来将遮盖后的图像传入Detector中,并在检测器中对掩码图像进行回归(reg)和分类(cls),并将回归后的分支输入DMIL模块(一会会详细介绍这一模块),最后会计算空间感知框生成阶段的整体损失(Lsa)。
DMIL--Dynamic Multiple Instance Learning Module(动态多实例学习模块)
刚开始对这一模块没有一点概念,完全不知道是做什么的,经过一番网络搜索,查找到的最多的就是Multiple Instance Learning,即多实例学习(不懂的同学可以自行搜索)。好在本文对DMIL模块的详细流程做了详细说明,整体来看DMIL模块分为如下四个部分--包构建、包扩展、包分类、实例选择。
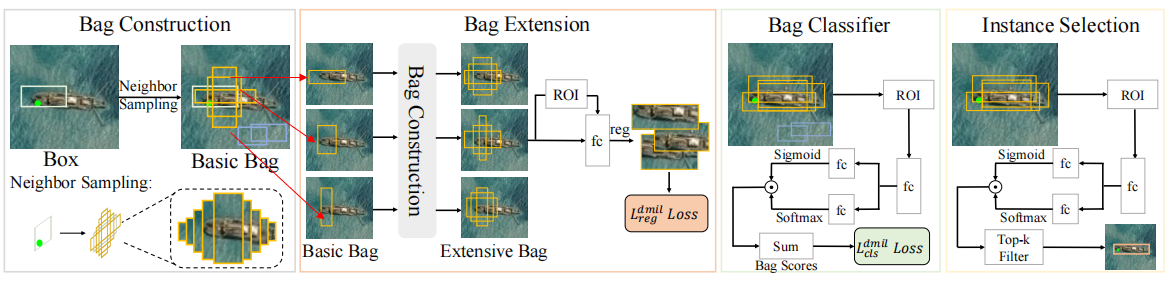
接下来,我逐一对每一部分进行说明。
包构建
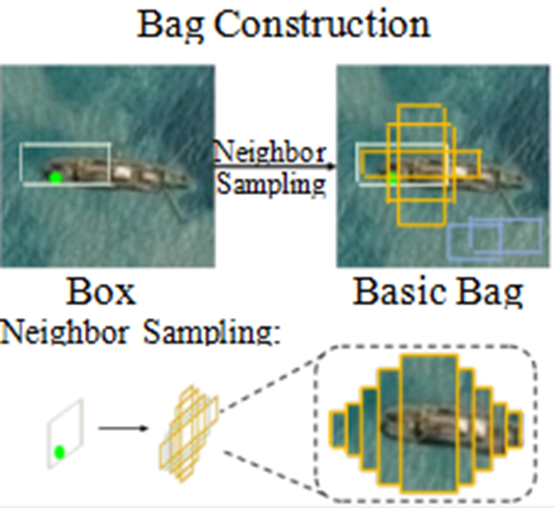
Given an image containing 𝑀 coarse pseudo boxes 𝑍 ∈ ℝ𝑀×4 (generated by the teacher network) and 𝑁 masked regions 𝑅 ∈ ℝ𝑁×4. we first perform Bag Construction for each box in 𝑍 and 𝑅. This process generates pseudobox proposal bags 𝐵𝑍 ∈ ℝ𝑀×𝑈1×4, mask proposal bags 𝐵𝑅 ∈ ℝ𝑁×𝑈1×4, and negative proposals 𝐵𝑛𝑒𝑔 ∈ ℝ 𝑈𝑛𝑒𝑔×4
以上一段是论文原文,具体构建的过程比较乱,我把同一种包用一种颜色进行标识。
首先就是蓝色:𝑍 ∈ ℝ𝑀×4--教师网络生成的框,𝐵𝑍 ∈ ℝ𝑀×𝑈1×4--通过邻域采样生成的一组框所构成的“教师包”。
然后是橘色:𝑅 ∈ ℝ𝑁×4--带有掩码的图像所生成的伪框,𝐵𝑅 ∈ ℝ𝑁×𝑈1×4--带有掩码图像所生成的伪框进一步通过邻域采样生成的“掩码包”。
最后是灰色:𝐵𝑛𝑒𝑔 ∈ ℝ 𝑈𝑛𝑒𝑔×4--表示背景框所构成的包,即“负包”。
以上内容就是包的构建,包构建的关键技术--邻域采样。不懂的同学自行搜索。
包扩展
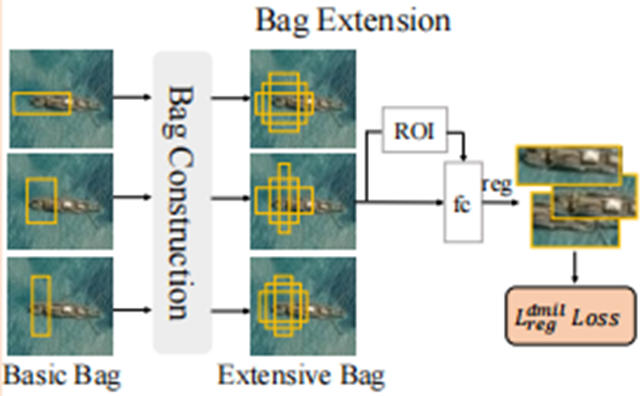
Therefore, in Bag Extension stage, we extend and refine the bags to ensure that more precise proposals can be sampled. For each proposal in bag 𝐵𝑍 and 𝐵𝑅, we perform neighbor sampling to expand it into an augmented set, 𝐵 ′ 𝑍 ∈ ℝ𝑀×𝑈1×𝑈2×4 and 𝐵 ′ 𝑅 ∈ ℝ𝑁×𝑈1×𝑈2×4, where 𝑈2 denotes the number of newly generated proposals during the bag extension process. Then, we refine the proposals in 𝐵 ′ 𝑍 and 𝐵 ′ 𝑅 to obtain more accurate proposal bags. Specifically, using 7 × 7 RoIAlign and two fully connected (fc) layers, the features of the proposals in 𝐵 ′ 𝑍 and 𝐵 ′ 𝑅 are extracted, denoted as 𝐹 ′ 𝑍 ∈ ℝ𝑀×𝑈1×𝑈2×𝐷 and 𝐹 ′ 𝑅 ∈ ℝ𝑁×𝑈1×𝑈2×𝐷. The regressor then takes the proposal bag and features as input and outputs a refined bag 𝐵 ′′ 𝑍 ∈ ℝ𝑀×𝑈1×𝑈2×4 and 𝐵 ′′ 𝑅 ∈ ℝ𝑁×𝑈1×𝑈2×4.
以上是论文原文。我把关键的地方用红的标出。蓝色和橘色与包构建部分所对应的包类型一致。对于教师包和掩码包中的每一个框采用邻域采样的策略对框进行扩展,生成扩展后的教师包和掩码包𝐵 ′ 𝑍和𝐵 ′ 𝑅 。之后采用7 × 7 RoIAlign并且过两个全连接层,提取𝐵 ′ 𝑍和𝐵 ′ 𝑅 中的特征,并生成𝐹 ′ 𝑍 和𝐹 ′ 𝑅 。最后,再将特征输入回归器reg,生成细化后的包𝐵 ′′ 𝑍和𝐵 ′′ 𝑅 。
这就是包扩展的过程。
包分类
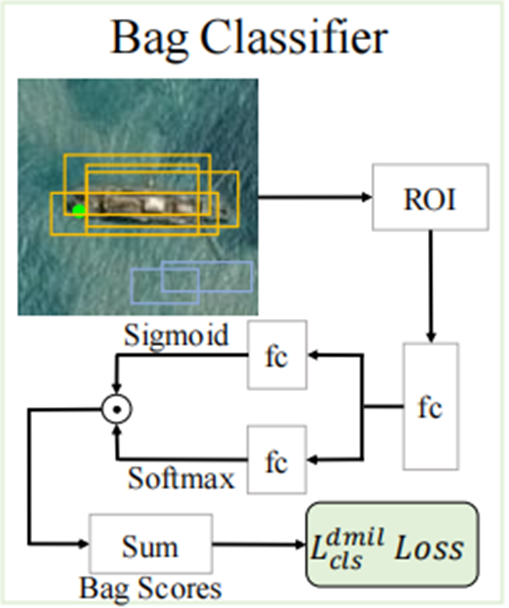
包分类阶段是通过对包扩展得到的扩展包计算包的分类分数来进行分类。具体过程如下:

最后,在计算完包的分类分数后,进行一步分类损失的计算:
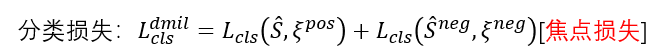
分别对正样本和负样本计算分类损失,其中的分类损失采用的是焦点损失(焦点损失不懂的小伙伴可以自行查询)。
实例选择
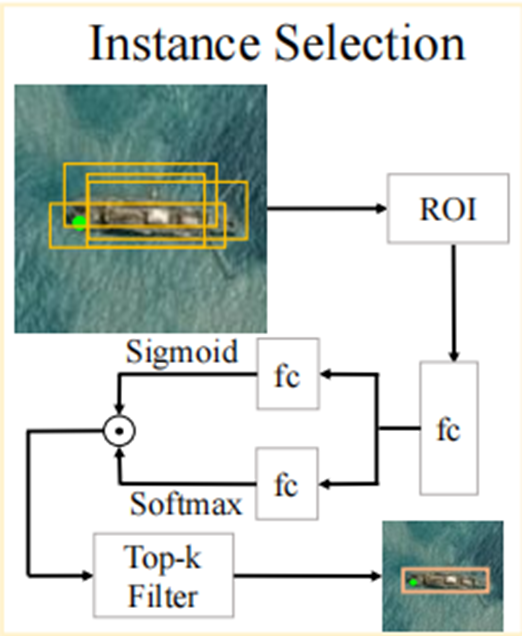
实例选择阶段的工作就是利⽤分类和实例得分从每个包中选择得分最高的前K个提议作为伪框。对于教师生成的框𝑍𝑗,我们过滤扩展包以选择最准确的前𝑘k个框,并将它们与𝑍𝑗合并以⽣成精确的伪
框𝜃𝑗。
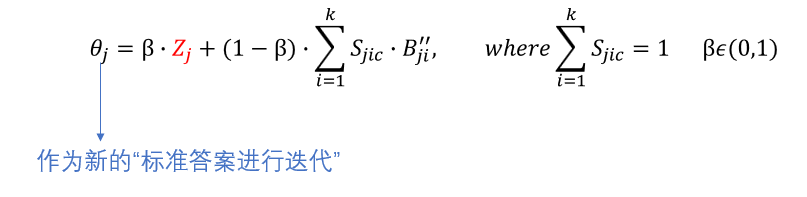
实例选择后生成的框𝜃𝑗,作为新的标准框,并作为新的监督信号,输入网络进行迭代。
空间感知框生成阶段的整体损失函数
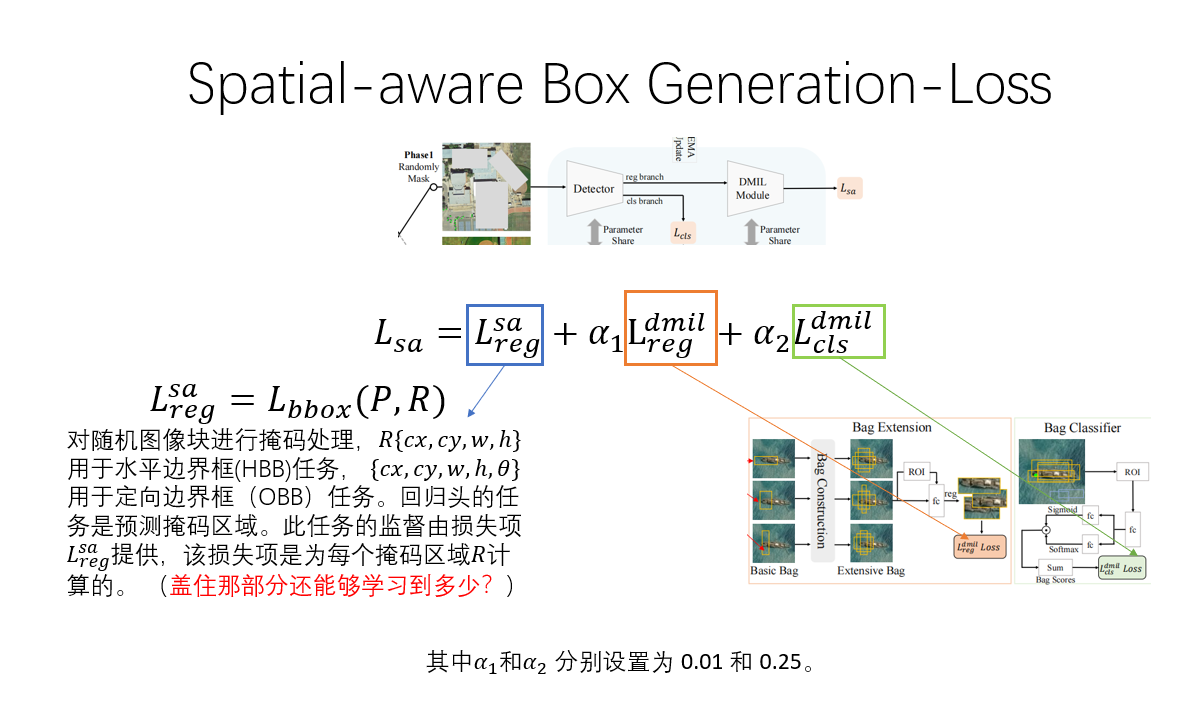
这个整体的损失函数分为三个部分:掩码图像部分最初始有一个回归损失,目的是预测掩码区域。接下来,在DMIL模块的包扩展(Bag Extension)阶段会计算一个回归损失,在包分类(Bag Classifier)阶段会计算一个分类损失,并且这两个损失的前面具有权重。这两个部分分别表示位置是否准确和分类是否正确。(如上图)
噪声感知标签进化(Noise-aware Label Evolution)
噪声感知标签进化阶段由两个部分构成:点标注和框细化。
点匹配
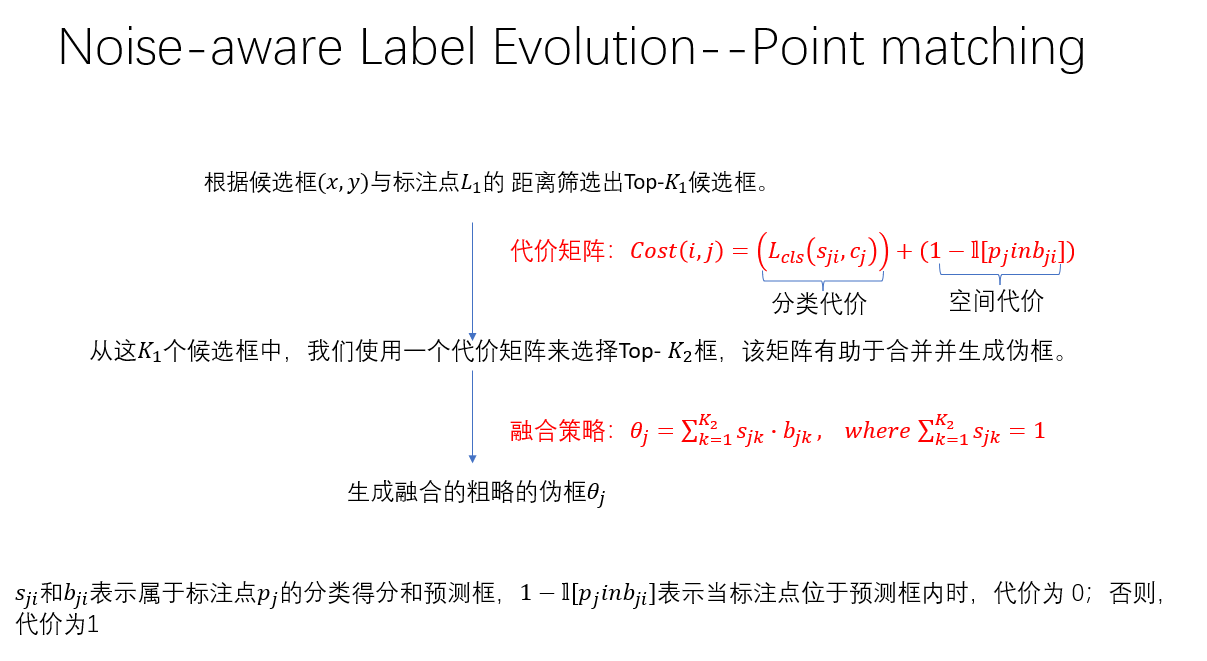
不同于以往的点匹配策略,这篇文章中的点匹配采用了两段的Top—K的点匹配方法。⾸先根据候选框与标注点的 距离筛选出Top-K1候选框。接着,从这 个候选框中,我们使⽤⼀个代价矩阵来选择Top-K2框,该矩阵有助于合并并⽣成伪框.代价矩阵主要由两个部分组成:分类代价和空间代价(如上图)。最后对这选出的·K2个伪框进行融合,得到新的伪框𝜃𝑗。
框细化
融合
Box Refinement: After obtaining the coarse pseudo boxes, the randomness of the annotated point leads to pseudo boxes with potential offsets and scale variations. To provide the student network with high-quality pseudo boxes, we first perform Bag Construction and Bag Extension for Θ𝑗 , generating the candidate proposals Bag 𝐵 ′′ 𝑗 and proposal scores 𝑆𝑗 . These are then passed to the Bag Classifier and Instance Selection stages, where the Top-𝐾3 most accurate proposals are chosen to generate the refined pseudo boxes Θ ′ 𝑗 . The fusion method is as follows:
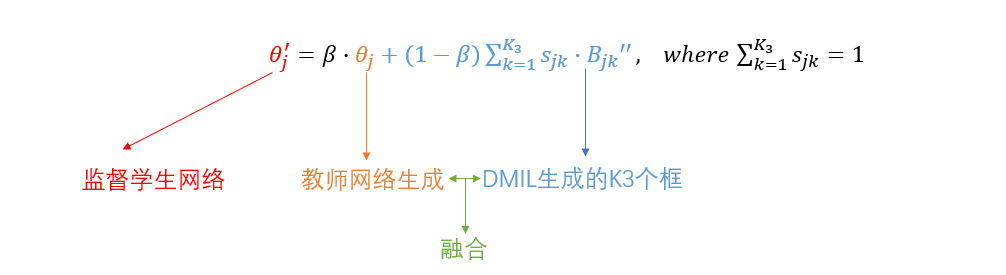
以上是原文对框细化的详细描述以及给出的公式。具体来说,将上一步得到的伪框𝜃𝑗进一步进行融合。具体来说,将上一步得到的伪框𝜃𝑗在过一次DMIL模块,并在实例选择阶段选出前K3个伪框进行融合,生成伪框𝜃𝑗‘。
增加扰动
最后为了让生成的伪框更加精确,对伪框增加了扰动处理,即用参数r对宽高进行扩展和缩放。

噪声感知标签进化阶段整体的损失函数
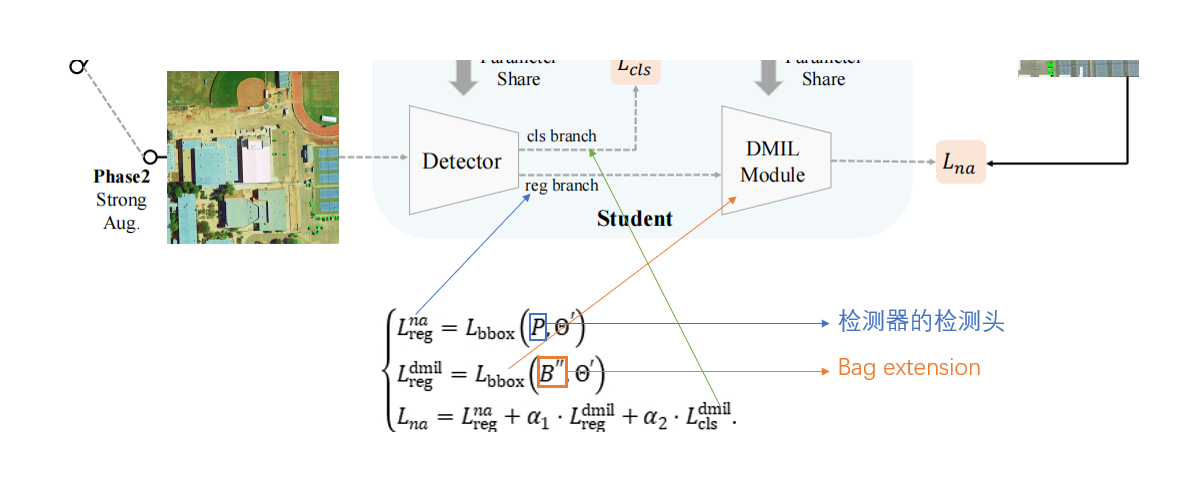
整体的损失函数由三部分构成,如图。第一部分是检测器检测头的的回归损失。第二部分是DMIL模块中包扩展的回归损失。第三部分是DMIL模块中包分类的分类损失。并且在后两个损失前同样有权重系数。
整个网络的损失

关于检测器
这篇文章还针对检测器进行了说明。由于微小目标缺乏尺度信息,现有的检测器不能够直接使用。这篇文章中⽤提出的⾃上⽽ 下的 FPN 聚合和尺度不变标签分配取代了 FPN 和标签分配。
⾃上⽽ 下的 FPN 聚合
使用1×1卷积(Conv)和上采样(Up)操作将从层P_3到P_7的特征聚合到单个输出层M中。对高层级特征进行1×1卷积(调整通道数或增强特征)。上采样至的P_i−1尺寸。将结果与低层级特征P_i−1相加,融合语义和细节信息。
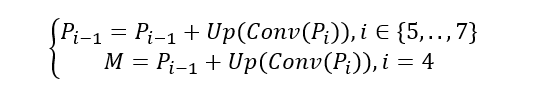
关于自顶向下FPN
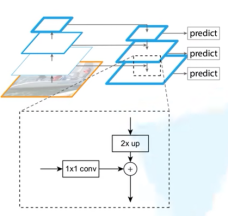
上采样(Upsample):将高层级特征图(如Conv5)放大至低层级特征图的尺寸。
横向连接(Lateral Connection):将上采样后的特征与对应的自底向上特征(如Conv4)通过逐元素相加(或拼接)融合。
重复操作:逐层传递融合后的特征,形成多尺度金字塔。
输出特征金字塔
每一层级输出一个融合后的特征图(如P3-P7),分别用于检测不同尺度的目标。
尺度不变标签分配策略
本实验中的标签分配策略与以往的有所不同,以往的方法是:挨个算IoU,如果大于0.5,说明是比较准确的预测框,与标准框做监督。而在本实验中尺度不变的标签分配是计算距离,选择距离最近的作为正样本,做监督。
以上就是这篇论文最主要最核心的部分。往后还有一些消融实验我没有介绍,如果有时间会再出一篇博客介绍一下消融实验。

















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









