




 本文详细介绍Pandas库在数据处理中的应用技巧,包括数据创建、存储、查看、操作、合并及时间处理等方面,助您快速掌握Pandas核心功能。
本文详细介绍Pandas库在数据处理中的应用技巧,包括数据创建、存储、查看、操作、合并及时间处理等方面,助您快速掌握Pandas核心功能。
重点,敲黑板了
- 首先,本文遵循,传统教学,点到为止!只介绍个人使用比较频繁的一些函数或处理方式。
- 本文的示例只是演示所用,示例一般是不修改原数据的,如果代码会修改原数据会标明(在原数据上进行修改),自己使用时一定要注意是否修改了原数据。一旦报错,首先检查自己的代码是否改变了原数据。
# 未修改原数据 df.drop('name', axis = 1) # 修改原数据 df.drop('name', axis = 1, inplace=True) # 修改原数据 df = df.drop('name', axis = 1)
pandas之所以强大是因为它拥有各种数据处理的函数,各个函数互相组合,灵活多变,并且与numpy、matplotlib、sklearn、>pyspark、sklearn等众多科学计算库交互,真正想要融会贯通实战是必经之路。- 原创不易,码字也很累。如果觉得文章不错,💗 一定记得三连哦💗 ~ 在此提前感谢各位。

文章目录
DataFrame创建
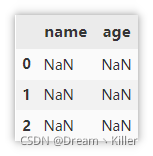
创建空的 DataFrame
创建一个空的 , 包含三行空数据。
df = pd.DataFrame(columns=['name', 'age'], index=[0, 1, 2])
常规 DataFrame 创建方式
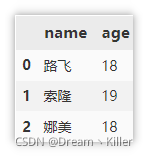
这里只介绍常见的三种,数组创建、字典创建、外部文件创建。常见文件读取的时候直接指定文件路径即可,对于 xlsx 文件可能存在多个 sheet 这时就需要指定 sheet_name 。
# 数组创建
df = pd.DataFrame(data=[['路飞', 18],
['索隆', 19],
['娜美', 18]],
columns=['name', 'age'])
# 通过字典创建
df = pd.DataFrame({
'name': ['路飞','索隆', '娜美'],
'age':[18, 19, 18]})
# 通过外部文件创建,csv,xlsx,json等
df = pd.read_csv('XXX.csv')
DataFrame存储
常见存储方式(csv, json, excel, pickle)
保存时,一般情况下是不需要保存索引的,因为读取的时候会自动生成索引。
df.to_csv('test.csv', index=False) # 忽略索引
df.to_excel('test.xlsx', index=False) # 忽略索引
df.to_json('test.json') # 保存为json
df.to_pickle('test.pkl') # 保存为二进制格式
DataFrame查看数据信息
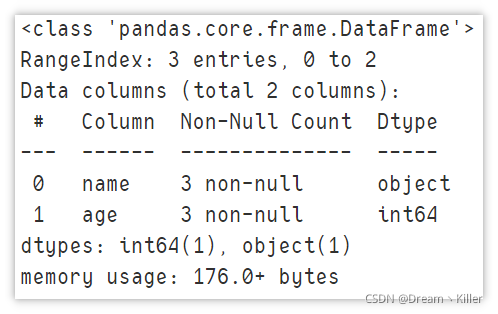
显示摘要信息
在我们使用 DataFrame 之前都会查看数据的信息,个人首选 info ,它展现了数据集的行列信息,以及每列中的非空值的数量。
df.info()
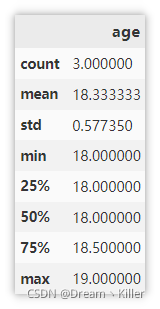
显示描述性统计信息
能够较为直观的查看数值列的基本统计信息。
df.describe()
显示 前 / 后 n行
默认显示5行,可指定显示的行数。
df.head(n) # 可指定整数,输出前面n行
df.tail(n) # 可指定整数,输出后面n行
显示索引、列信息
显示索引及列的基本信息。
df.columns # 列信息
df.index # 索引信息

显示每列的数据类型
显示列的名称及对应的数据类型。
df.dtypes

显示占用的内存大小
显示给列占用内存的大小,单位是 :字节(byte)。
df.memory_usage()

定位某行数据
重点:无论是 loc 还是 iloc 使用的要领都是先指定行,再指定列,并且行与列表达式用 , 分隔。如:df.loc[:, :] 获取所有行所有列的数据。
使用 loc() 定位
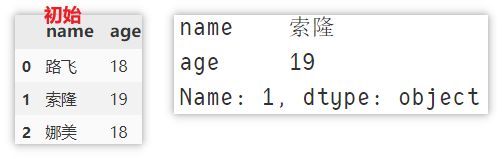
比如现在要定位 [索隆] 这行数据,有以下
df.loc[1, :] # loc[index , columns] 行索引,列名,返回 Series 对象
df.loc[df['age'] > 18] # 返回 DataFrame 对象
# 或者 df[df['age'] > 18]
# df.loc[df['name'] == '索隆']

使用 iloc 定位
使用 iloc 取第二行(索引从0开始),所有列的数据。
df.iloc[1, :] # iloc[index1, index2] 行索引, 列索引
添加一行数据
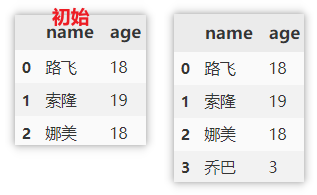
使用 loc 定位并添加
使用 loc 定位到 index = 3 的行,再进行赋值(在原数据上进行修改)
df.loc[len(df)] = ['乔巴', 3]
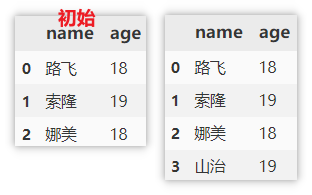
使用 append 添加
append 添加数据时需要指定列名,列值,如果某列未指定的话,则默认填充 NaN。
df.append({
'name': '山治', 'age': 19}, ignore_index=True)
删除数据
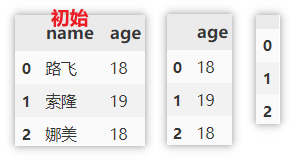
根据列名删除列
使用 drop 来删除某列,指定要删除的轴,与对应 列/行 的 名称/索引。
df.drop('name', axis = 1) # 删除单列
df.drop(['name', 'age'], axis = 1) # 删除多列
根据索引删除行
与上面删除列的方式相似,不过这里指定的是索引。
df.drop(0, axis=0) # 删除单行
df.drop([0, 1], axis=0) # 删除多行
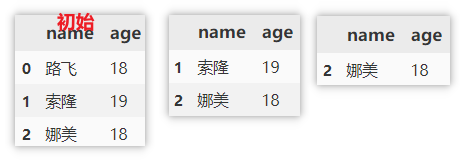
使用 loc 定位数据并删除
先使用 loc 定位某条件的数据,再获取索引 index ,然后使用 drop 删除。
df.drop(df.loc[df['name' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1862
1862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











