







 本文详细介绍了Python中使用matplotlib库进行数据可视化的各种图表绘制,包括柱状图、水平条形图、直方图、饼状图和散点图的创建方法,涵盖了参数设置、颜色、标签、透明度等细节,并提供了丰富的示例代码,帮助理解并应用到实际数据分析中。
本文详细介绍了Python中使用matplotlib库进行数据可视化的各种图表绘制,包括柱状图、水平条形图、直方图、饼状图和散点图的创建方法,涵盖了参数设置、颜色、标签、透明度等细节,并提供了丰富的示例代码,帮助理解并应用到实际数据分析中。
目录
一、柱状图的绘制pyplot.bar()
matplotlib.pyplot.bar(x, height, width=0.8, bottom=None,
*, align=‘center’, data=None, **kwargs)
参数说明
x:表示x坐标,数据类型为float类型,一般为np.arange()生成的固定步长列表
height:表示柱状图的高度,也就是y坐标值,数据类型为float类型,一般为一个列表,包含生成柱状图的所有y值
width:表示柱状图的宽度,取值0-1之间,默认值为0.8
bottom:柱状图的起始位置,也就是y轴的起始坐标,默认值为None
align:柱状图的中心位置,“center”,“lege"边缘,默认值为"center”
color:柱状图颜色,默认为蓝色
alpha:透明度,取值在0-1之间,默认值为1
label:标签,设置后需要调用plt.legend()生成
edgecolor: 边框颜色(ec)
linewidth:边框宽度,浮点数或类数组,默认为None
tick_label:柱子的刻度标签,字符串或字符串列表,默认值为None
linestyle:线条样式(ls)
举例:
x = range(5)
data = [5,20,15,25,10]
plt.title("基本柱状图")
plt.grid(ls="--", alpha=0.5)
plt.bar(x, data)
plt.rcParams['font.sans-serif'] = ['SimHei']
输出:
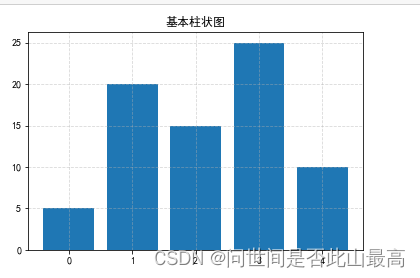
bottom参数:
#柱状图的起始位置,也就是Y轴的起始坐标,默认值为None
x = range(5)
data = [5,20,15,25,10]
plt.title("基本柱状图")
plt.grid(ls="--", alpha=0.5)
plt.bar(x,data,bottom=[10,20,5,0,10])
#注意data=[5,20,15,25,10]----对应的bottom---->[10,20,5,0,10]
'''
--- a.形状要一致
--- b.每个图形y轴的起始位置
'''
输出:
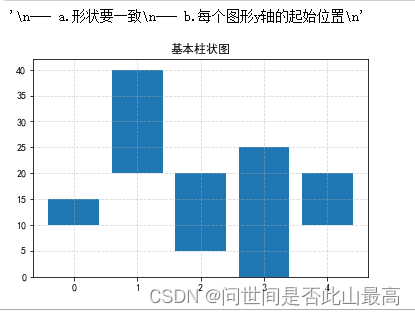
柱状图颜色
x = range(5)
data = [5,20,15,25,10]
plt.title("基本柱状图")
plt.grid(ls="--", alpha=0.5)
plt.bar(x,data,facecolor="green")
输出:
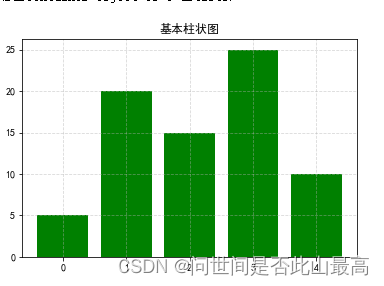
多种颜色:
x = range(5)
data = [5,20,15,25,10]
plt.title("基本柱状图")
plt.grid(ls="--", alpha=0.5)
plt.bar(x,data,color=['r','g','b'])
'''
facecolor和color设置单个颜色时使用方式一样
color可以设置多个颜色值,facecolor不可以
'''
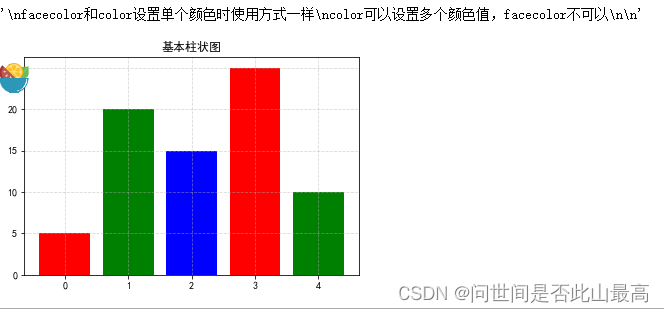
描边-相关的关键字参数为:
edgecolor或ec
linestyle或ls
linewidth或lw
举例:
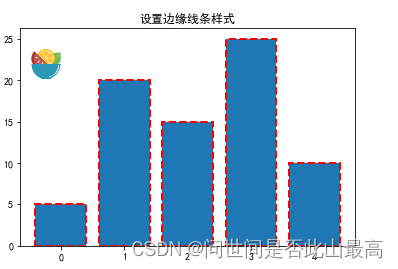
data = [5,20,15,25,10]
plt.title("设置边缘线条样式")
plt.bar(range(len(data)), data, ec='r', ls="--", lw=2)
输出:
设置tick label
柱子的刻度标签,字符串或字符串列表
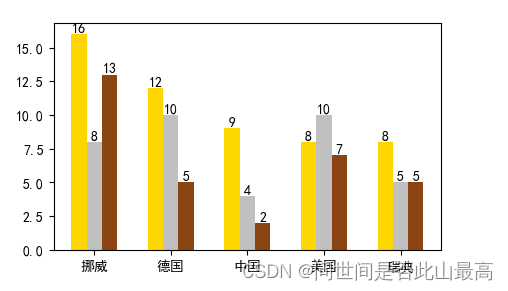
countries = ["挪威", "德国", "中国", "美国", "瑞典"]
gold_medal = [16,12,9,8,8]
silver_medal = [8,10,4,10,5]
bronze_medal = [13,5,2,7,5]
#1.将x轴转换为数值
x = np.arange(len(countries))
print(x.dtype)
width = 0.2
#2.确定x起始位置
#金牌起始位置
gold_x = x
#银牌起始位置
silver_x = x + width
#铜牌起始位置
bronze_x = x + 2*width
#========分别绘制图形
#金牌图形
plt.bar(gold_x,gold_medal,width = width,color="gold")
#银牌图形
plt.bar(silver_x,silver_medal,width = width,color="silver")
#铜牌图形
plt.bar(bronze_x,bronze_medal,width = width,color="saddlebrown")
#=======将x轴的坐标变回来
plt.xticks(x+width,labels=countries)
# 显示高度文本
for i in range(len(countries)):
plt.text(gold_x[i],gold_medal[i],gold_medal[i],va="bottom",ha="center")
plt.text(silver_x[i],silver_medal[i],silver_medal[i],va="bottom",ha="center")
plt.text(bronze_x[i],bronze_medal[i],bronze_medal[i],va="bottom",ha="center")
输出:
二、水平条形图pyplot.barh()
Barh()函数
barh()函数与bar()函数用法一样,只是在调用函数时使用y参数传入Y轴数据,使用width参数传入代表条柱宽度的数据。
例子:
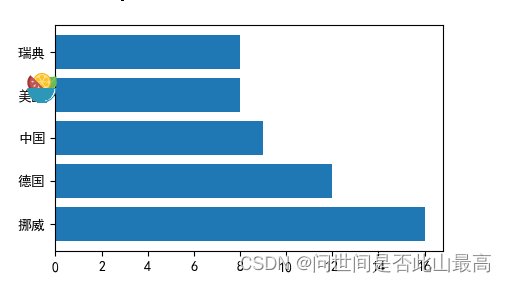
countries = ['挪威','德国','中国','美国','瑞典']
gold_medal = np.array([16,12,9,8,8])
plt.barh(countries, width=gold_medal)
输出:
示例:

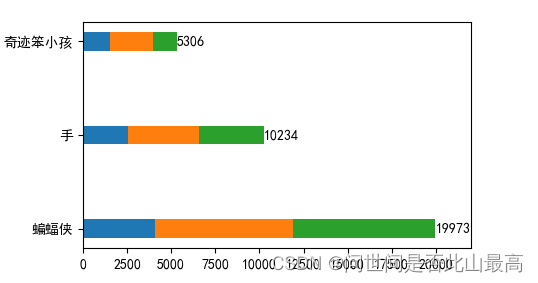
绘制水平条形图:
movies = ["蝙蝠侠","手","奇迹笨小孩"]
real_day1 = np.array([4053,2548,1543])
real_day2 = np.array([7840,4013,2421])
real_day3 = np.array([8080,3673,1342])
height=0.2
plt.barh(movies,real_day1,height=height)
plt.barh(movies,real_day2,left=real_day1,height=height)
plt.barh(movies,real_day3,left=real_day1+real_day2,height=height)
#标注数值
sum_data = real_day1 + real_day2 +real_day3
print(sum_data)
#horizontalalignment 控制文本的x位置参数表示文本边界框的左边,中间或右边
#verticalaignment控制文本的y位置参数表示文本边界框的底部,中心或顶部
for i in range(len(movies)):
plt.text(sum_data[i], movies[i], sum_data[i], va = "center" ,ha="left")
plt.xlim(0,sum_data.max()+2000)
输出:
三、直方图pyplot.hist
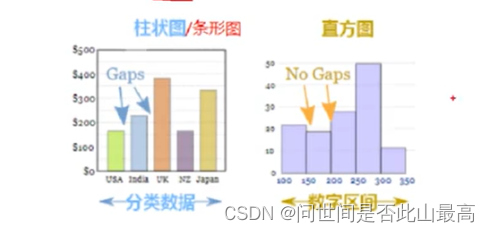
直方图,又称质量分布图,是条形图的一种,横轴表示数据类型,纵轴表示分布情况。
与柱状图的区别:
直方图用于概率分布,显示了一组数值序列在给定的数值范围内出现的频率;柱状图则用于展示各个类别的频数。
plt.hist(x,bins=None,range=None,density=None,weights=None,
cumulative=False,bottom=None,histtype='bar',align='mid',
orientation='vertical',rwidth=None,log=False,color=None,label=None,
stacked=False,normed=None,*,data=None,**kwargs)
参数说明

示例:
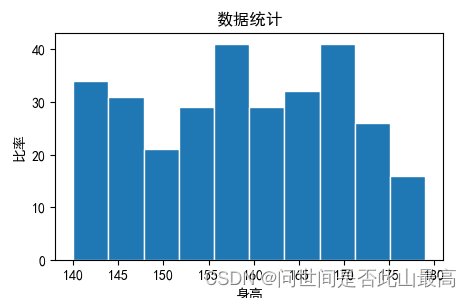
#使用numpy随机生成300个随机数据
x_value = np.random.randint(140,180,300)
plt.hist(x_value, bins=10, edgecolor='white')#直方图边框颜色
plt.title('数据统计')
plt.xlabel("身高")
plt.ylabel("比率")
输出:
返回值:
n:数组或数组列表
直方图的值
bins:数组
返回各个bin的区间范围
patches:列表的列表或列表,返回每个bin里面包含的数据,是一个list
例子:
num, bins_limit, patches = plt.hist(x_value,bins=10, edgecolor='white')
print("n是分组区间对应的频率 :",num,end="\n\n")
print("bins_limit是分组时的分隔值:",bins_limit,end="\n\n")
print(patches)
for p in patches:
print(p)
print(p.get_x())
print(p.get_y())
print(p.get_width())
print("patches指的是直方图中的列表对象:",type(patches),end="\n\n")
输出:

添加折线直方图:
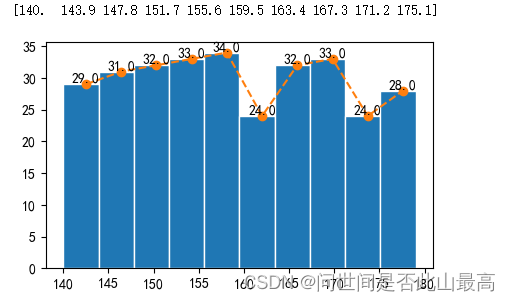
首先通过pyplot.subplots()创建Axes对象
通过Axes对象调用hist()方法绘制直方图,返回折线图所需的x,y数据
然后Axes对象调用plot()绘制折线图
改造刚才的代码:
#创建一个画布
fig,ax = plt.subplots()
#绘制直方图
num,bins_limit,patches = ax.hist(x_value, bins=10, edgecolor='white')
#num返回的个数是10,bins_limit返回的个数是11,需要截取
print(bins_limit[:10])
#曲线图
ax.plot(bins_limit[:10]+2.5, num, '--', marker='o')
#ax.plot(bins_limit, np.append(num,num[-1]), '--', marker='o')
for i in range(len(num)):
plt.text(bins_limit[i]+2.5,num[i],num[i],va='bottom',ha='center')
输出:
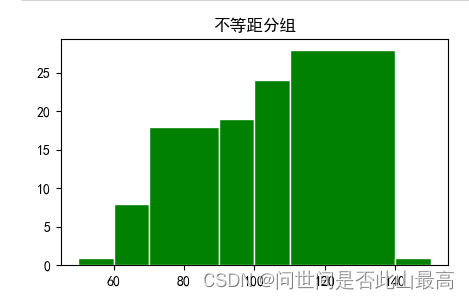
不等距分组:
指定分组上下限,指定histtype='bar’即可。
示例:
fig, ax = plt.subplots()
x = np.random.normal(100,20,100) #均值和标准差
bins = [50,60,70,90,100,110,140,150]
ax.hist(x, bins, color='g',edgecolor='white')
ax.set_title("不等距分组")
plt.show()
输出:
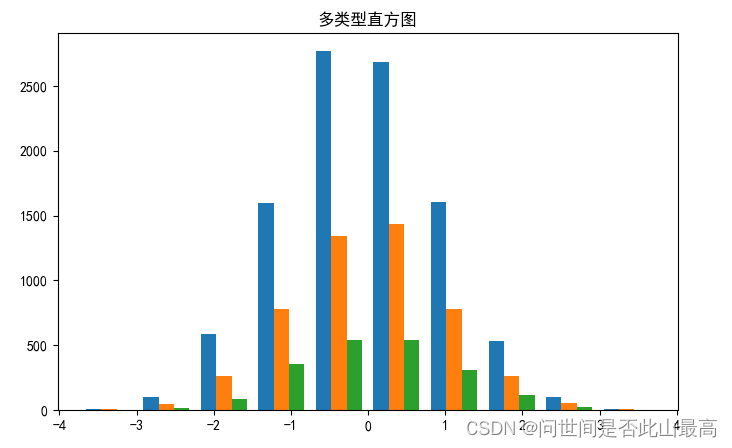
多类型直方图
以列表的形式传入多种数据给hist()方法的x数据
#指定分组个数
n_bins = 10
fig, ax=plt.subplots(figsize=(8,5))
#分别生成10000,5000,2000个值
x_multi = [np.random.randn(n) for n in [10000,5000,2000]]
#在ax.hist函数中先指定图例 label 名称
ax.hist(x_multi,n_bins,histtype='bar',label=list("ABC"))
ax.set_title('多类型直方图')
输出:
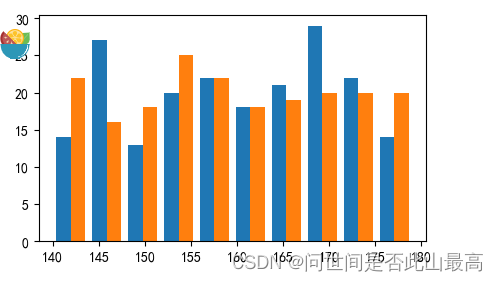
堆叠直方图:
有时候需要在同样数据范围下,对比两组不同对象群体收集的数据差异
直方图属性data:以列表的形式传入两组数据
设置直方图stacked:为true,允许数据覆盖
举例:
x_value = np.random.randint(140,180,200)
x2_value = np.random.randint(140,180,200)
plt.hist([x_value,x2_value],bins=10,stacked=False)
输出:
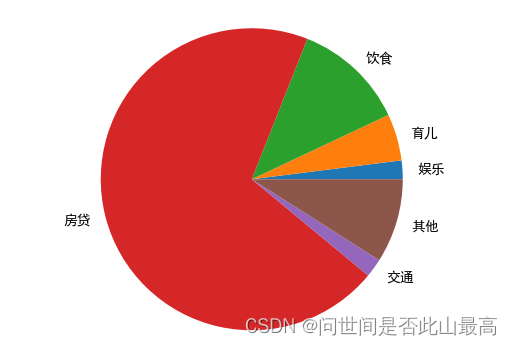
四、饼状图pyplot.pie()
参数说明
pyplot.pie(x,explode=None,labels=None,colors=None,autopct=None)

示例:
#设置大小
plt.rcParams['figure.figsize'] = (5,5)
#定义饼的标签
labels = ['娱乐','育儿','饮食','房贷','交通','其他']
#每个标签所在的数量
x = [200,500,1200,7000,200,900]
#绘制饼图
plt.pie(x,labels=labels)
输出:
百分比显示autopct
#定义饼的标签
labels = ['娱乐','育儿','饮食','房贷','交通','其他']
x = [200,500,1200,7000,200,900]
plt.title = ("饼图示例-8月份家庭支出")
plt.pie(x,labels=labels,autopct = '%.2f%%')#%.2f%%显示百分比,保留两位小数
输出:
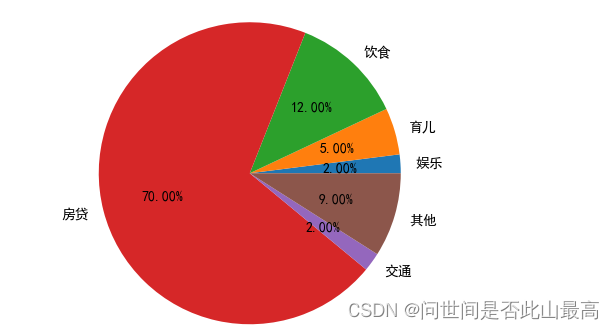
饼状图的分离:
explode:指定饼图某些部分的突出显示
#定义饼的标签
labels = ['娱乐','育儿','饮食','房贷','交通','其他']
x = [200,500,1200,7000,200,900]
plt.title = ("饼图示例-8月份家庭支出")
plt.pie(x,labels=labels,autopct = '%.2f%%')#%.2f%%显示百分比,保留两位小数
输出:
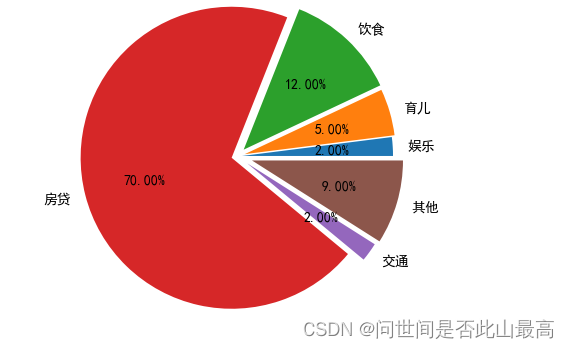
设置饼状图百分比和文本距离中心位置:
pctdistance:设置百分比标签与圆心的距离
labeldistance:设置各扇形标签(图例)与圆心的距离
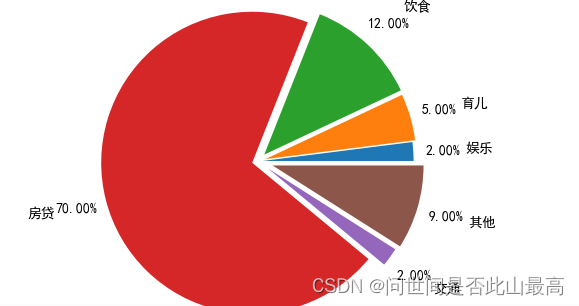
labels = ['娱乐','育儿','饮食','房贷','交通','其他']
x = [200,500,1200,7000,200,900]
explode = (0.03,0.05,0.06,0.04,0.08,0.1)
plt.pie(x, labels=labels, autopct='%3.2f%%',explode=explode,labeldistance=1.35, pctdistance=1.2)
输出:
五、散点图 pyplot.scatter()

`matplotlib.pyplot.scatter(x,y,s=None,c=None,marker=None,cmap=None,norm=None,
vmin=None,alpha=None,linewidths=None,edgecolors=None,
plotnonfinite=False,data=None,*kwargs)`
x,y 散点的坐标
s 散点的面积
c 散点的颜色(默认值为蓝色,'b',其余颜色同plt.plot())
marker 散点样式(默认值为实心圆,'o',其余样式同plt.plot())
alpha 散点透明度([0,1]之间的数,0表示完全透明,1表示完全不透明)
linewidths 散点的边缘线宽
edgecolors 散点的边缘颜色
cmap Colormap ,默认为None,标量是一个colormap的名字,只有c是一个浮点数数组时才使用
示例:
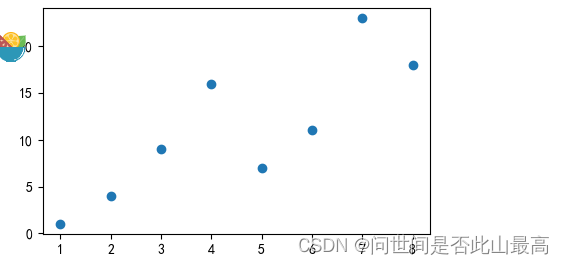
x = np.array([1,2,3,4,5,6,7,8])
y = np.array([1,4,9,16,7,11,23,18])
plt.scatter(x,y)
输出:
设置图标大小
x = np.array([1,2,3,4,5,6,7,8])
y = np.array([1,4,9,16,7,11,23,18])
#生成一个[0,1)之间的随机浮点数或N维浮点数组
print((20 * np.random.rand(8))**2)
s = (20 * np.random.rand(8))**2
plt.scatter(x, y, s)
输出:
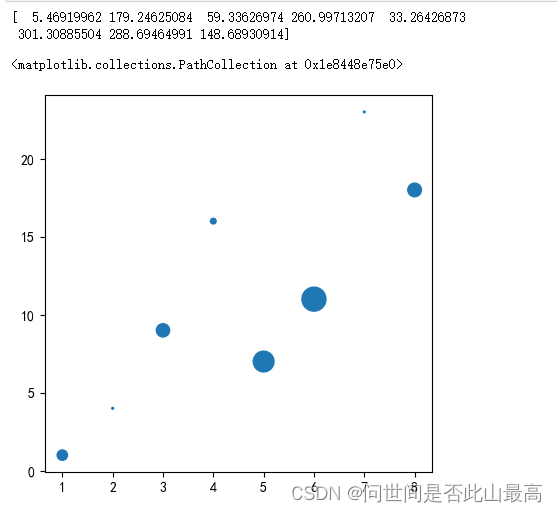
自定义点的颜色和透明度
x = np.random.rand(50)
y = np.random.rand(50)
s = (10*np.random.randn(50))**2
#颜色可以使用一组数字序列,如需要3种颜色
#color = np.resize(np.array([1,2,3]),100)
#颜色随机
colors = np.random.rand(50)
plt.scatter(x,y,s,c=colors,alpha=0.5)
输出:
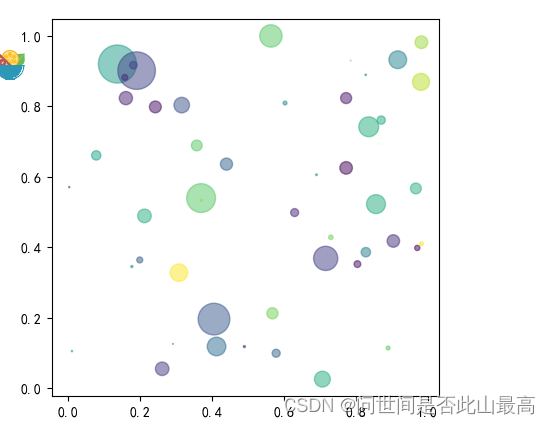
颜色条Colormap
x = np.arange(1,101)
y = np.arange(1,101)
colors = np.arange(1,101)
plt.scatter(x,y, c=colors, cmap='viridis')
输出:
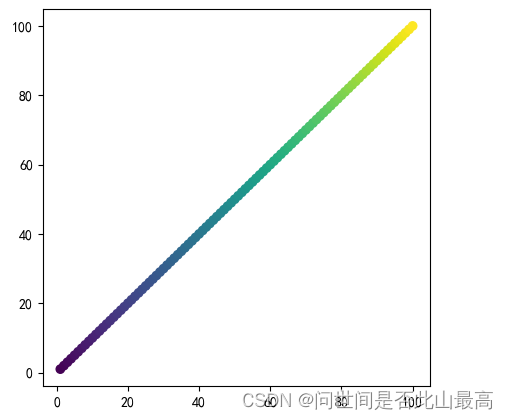
来个好看的:
x = np.arange(1,11)
y = np.arange(1,11)
colors = np.linspace(0,1,10)
plt.scatter(x,y,c=colors,cmap='Set1')
输出:
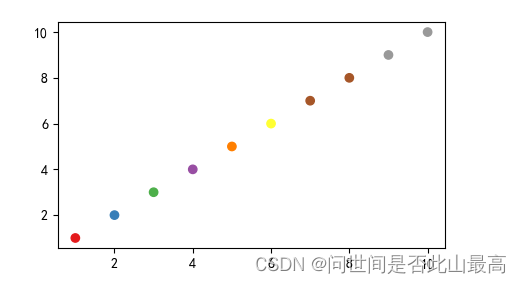
乱入:
%matplotlib notebook
x = np.random.randn(100)
y = np.random.randn(100)
colors = np.linspace(0,1,100)
plt.scatter(x,y,c=colors,cmap='Set1')
t = np.linspace(0,8,100)
x1 = 8 * np.sin(t) ** 3
y1 = 15 * np.cos(t) - 5*np.cos(2*t) - 4*np.cos(3*t) - np.cos(4*t)
plt.scatter(x,y,s=100, c=colors,alpha=0.6,marker='$\heartsuit$')
plt.axis('off')
输出:

六、 保存图片 pyplot.savefig()
savefig(fname,dpi=None,facecolor='w',edgecolor='w',orientation='portrait',
papertype=None,format=None,transparent=False,
bbox_inches=None,pad_inches=0.1,frameon=None,metadata=None)
 举例:
举例:
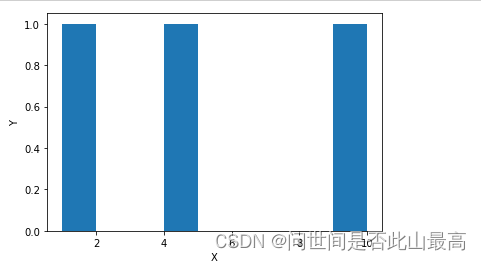
import numpy as np
import matplotlib.pyplot as plt
import os
x_axis = [1,4,9,16,25,36,49,64,81,100]
y_axis = [1,2,3,4,5,6,7,8,9,10]
plt.hist(x_axis, y_axis)
plt.xlabel("X")
plt.ylabel("Y")
#使用os模块判断目录是否存在
if not os.path.exists("my"):
os.mkdir("my")
plt.savefig("my/my2233.png")
plt.show() #如果plt.show()在前面,会保存空白画布
输出:
七、 箱线图绘制pyplot.boxplot()
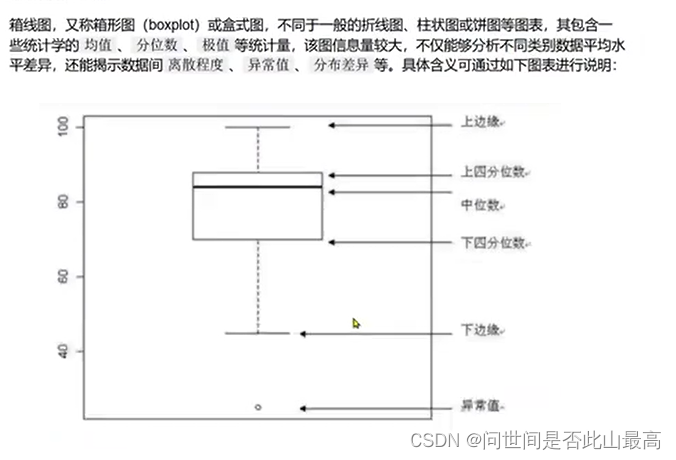

`
matplotlib.pyplot.boxplot(x, notch=None, sym=None, vert=None, whis=None, positions=None, widths=None, patch_artist=None, bootstrap=None, usermedians=None, conf_intervals=None, meanline=None, showmeans=None, showcaps=None, showbox=None, showfliers=None, boxprops=None, labels=None, flierprops=None, medianprops=None, meanprops=None, capprops=None, whiskerprops=None, manage_ticks=True, autorange=False, zorder=None, *, data=None)
x:输入数据。类型为数组或向量序列。必备参数。
notch:控制箱体中央是否有V型凹槽。当取值为True时,箱体中央有V型凹槽,凹槽表示中位数的置信区间;取值为False时,箱体为矩形。类型为布尔值,默认值为False。可选参数。
vert:箱体的方向,当取值为True时,绘制垂直箱体,当取值为False时,绘制水平箱体。类型为布尔值,默认值为True。可选参数。
positions:指定箱体的位置。刻度和极值会自动匹配箱体位置。类型为类数组结构。可选参数。默认值为range(1, N+1) ,N为箱线图的个数。
widths:箱体的宽度。类型为浮点数或类数组结构。默认值为0.5或0.15*极值间的距离。
labels:每个数据集的标签,默认值为’None’。类型为序列。可选参数。
autorange:类型为布尔值,默认值为False。可选参数。当取值为True且数据分布满足上四分位数(75%)和下四分位数(25%)相等,whis设置为(0, 100) ,即箱须端点为数据的最大值和最小值。
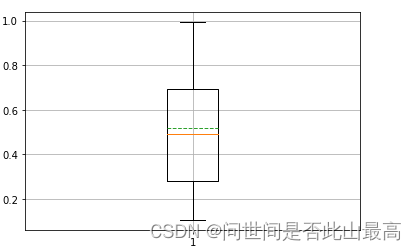
举例:
#logspace
x = np.random.rand(20)
#plt.boxplot(x)
#showmeans-- 是否显示算术平均值
#meanline :均值显示为线还是点,类型为布尔值,默认False
#可选参数,当取值为True,且showmeans、shownotches参数为True时显示为线
#labels:每个数据集的标签
plt.boxplot(x,showmeans=True,meanline=True)
plt.grid()
plt.show()
输出:
显示多个箱线图:
x = np.random.randint(10,100,size=(5,5))
box = {"linestyle":'--',"linewidth":1,"color":'blue'}
mean = {"marker":'o',"markerfacecolor":'pink',"markersize":2}
#boxprops--箱体的样式 类型为字典
#meanprops—算术平均值的样式,类型为字典
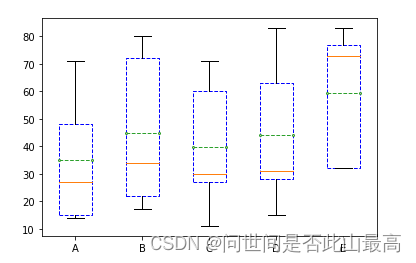
plt.boxplot(x,meanline=True,showmeans=True,labels=['A','B','C','D','E'],boxprops=box,meanprops=mean)#按列
plt.show()
输出:
八、词云WordCloud()
WordCloud是python环境下的词云图工具包,能把关键词数据转换成直观有趣的图文模式。
conda环境安装:
conda install -c conda-forge wordcloud
引入wordcloud
from wordcloud import WordCloud
模板示例:
with open("data/tag.txt",encoding="utf-8") as file:
txt = file.read()
#如果数据文件中包含有中文的话,font_path必须指定字体,否则中文会乱码
#collocations:是否包括两个词的搭配,默认为True,如果为true的时候会有重复的数据,不需要重复数据设置为False
#width:幕布的宽度 ,height:幕布的高度
#max_words 要显示的词的最大个数
#generate 读取文本文件
wordcloud = WordCloud(font_path = "C:/Windows/Fonts/simfang.ttf",collocations=True,
background_color='black',
width=800,
height=600,
max_words=20).generate(txt)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()
#写入文件
wordcloud.to_file("tag.jpg")
输出:

说明:


中文使用词云图—需要jieba分词模块
支持三种分词模式:
精确模式,适合文本分析
全模式,扫描所有可以成词的词语,不能解决歧义
搜索引擎模式,在精确模式上,再次对长词进行切分
支持繁体分词
支持自定义词典
pip install jieba
 示例:
示例:
import jieba
seg_list = jieba.cut("我来到北京清华大学",cut_all=True)# 返回列表
print("Full Mode: " + " ".join(seg_list))# 全模式
seg_list = jieba.cut("我来到北京清华大学",cut_all=False)
print("Default Mode: " + " ".join(seg_list))#精确模式 #列表拼接:.join()
seg_list = jieba.cut("小明硕士毕业于中国科学院研究所,后在日本京都大学深造")
print(" ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院研究所,后在日本京都大学深造")
print(" ".join(seg_list))
输出:

jieba.analyse:
提取关键字
jieba.analyse.extract_tags(sentence, topK=5, withWeight=True, allowPOS=())
第一个参数:待提取关键词的文本
第二个参数topK:返回关键词的数量,重要性从高到低排列
第三个参数:withWeight:是否同时返回每个关键词的权重
第四个参数allowPOS=():词性过滤,为空则表示不过滤,若提供则仅返回符合词性要求的关键词
举例:
import jieba.analyse
text = "2月12日,美国白宫公布了长达19页的《印太战略文件》,这是拜登政府首次明确美国在“印太地区”的五大政策目标,并提出在未来一至两年内拟重点推进的十大具体政策举措。从2009年奥巴马政府提成“亚太再平衡”到2017年特朗普入主白宫,提出“自由开放的印太战略”,拜登的《印太战略文件》致力于成为重塑“印太战略”未来十年走向的基石性文件。"
seg_list = jieba.analyse.extract_tags(text,allowPOS=("n")) #只返回名词
print("analysea extract allowPOS:" + str(seg_list))
str_txt = " ".join(seg_list)
background_image = plt.imread('F:/numpy/ditu.jpg')#设置背景图片
wordcloud = WordCloud(font_path = "C:/Windows/Fonts/simfang.ttf",collocations=True,
background_color='black',
mask=background_image,
width=800,
height=600,
max_words=50).generate(str_txt)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()
#写入文件
wordcloud.to_file("shipin.jpg")
输出:
 从文件中提取文本:
从文件中提取文本:
with open("data/qingshu.txt",encoding="utf-8") as file:
txt = file.read()
seg_list = jieba.cut(txt)
seg_list = jieba.analyse.extract_tags(txt)
txt_str = " ".join(seg_list)
#如果数据文件中包含有中文的话,font_path必须指定字体,否则中文会乱码
#collocations:是否包括两个词的搭配,默认为True,如果为true的时候会有重复的数据,不需要重复数据设置为False
#width:幕布的宽度 ,height:幕布的高度
#max_words 要显示的词的最大个数
#generate 读取文本文件
wordcloud = WordCloud(font_path = "C:/Windows/Fonts/simfang.ttf",collocations=False,
background_color='black',
width=800,
height=600,
max_words=50).generate(txt_str)
#生成图片
image = wordcloud.to_image()
#展示图片
image.show()
#写入文件
wordcloud.to_file("qingshu.jpg")
对于一篇新闻,完整的词云生成实例:
import jieba.analyse
from wordcloud import WordCloud
from matplotlib import pyplot as plt
import numpy as np
from PIL import Image
from matplotlib import colors
#绘制画布
fig = plt.figure(dpi=200)
#获取文本text
text = open("2022.txt", encoding="utf-8").read()
#已换行符分割文本内容
p_list = text.split("\n")
#保存结巴提取后的数据列表
text_cut = []
for p in p_list:
# 注意 列表中append和extend的区别
text_cut.extend(jieba.analyse.extract_tags(p,allowPOS=("n")))
#组合分词
new_text = ' '.join(text_cut) #组合
#background_image = plt.imread('F:/numpy/xiangqin.png')
background_image=np.array(Image.open("F:/numpy/xiangqin.png"))
#生成词云
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",
collocations=False,
background_color="black",
width=800,
height=600,
max_words=50,
mask=background_image, # 指定词云的形状
contour_width = 3,\
contour_color = 'white'
).generate(new_text)
image = wordcloud.to_image()
image.show()
wordcloud.to_file("2022.jpg")
输出:


















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









